

21.08.2024 16:45
Nvidia створила компактну мовну модель Llama-3.1-Minitron 4B
У той час як технологічні компанії змагаються за впровадження штучного інтелекту на пристроях, з’являється все більше досліджень, які зосереджені на створенні малих мовних моделей, здатних працювати на пристроях з обмеженими ресурсами. Останнім досягненням Nvidia в цій галузі є Llama-3.1-Minitron 4B, компактна версія моделі Llama 3, яка використовує останні досягнення в відсіканні та дистиляції. Ця модель конкурує за продуктивністю як з більшими моделями, так і з аналогічними за розміром малими мовними моделями, але при цьому є значно ефективнішою у навчанні та розгортанні.
Переваги відсікання та дистиляції
Відсікання та дистиляція є важливими методами у створенні менших та ефективніших мовних моделей. Обрізання передбачає видалення менш важливих компонентів моделі. Існують різні підходи, такі як «обрізання по глибині», коли видаляються цілі шари, і «обрізання по ширині», коли вилучаються окремі елементи, такі як нейрони та головки, що відповідають за увагу.
Дистиляція моделі є процесом, який переносить дані з великої «моделі вчителя» на меншу, простішу «модель учня». Існує два основних методи дистиляції: «навчання SGD», коли модель учня навчається на основі вхідних даних і відповідей вчителя, і «класична дистиляція знань», коли учень навчається на основі внутрішніх реакцій моделі вчителя.
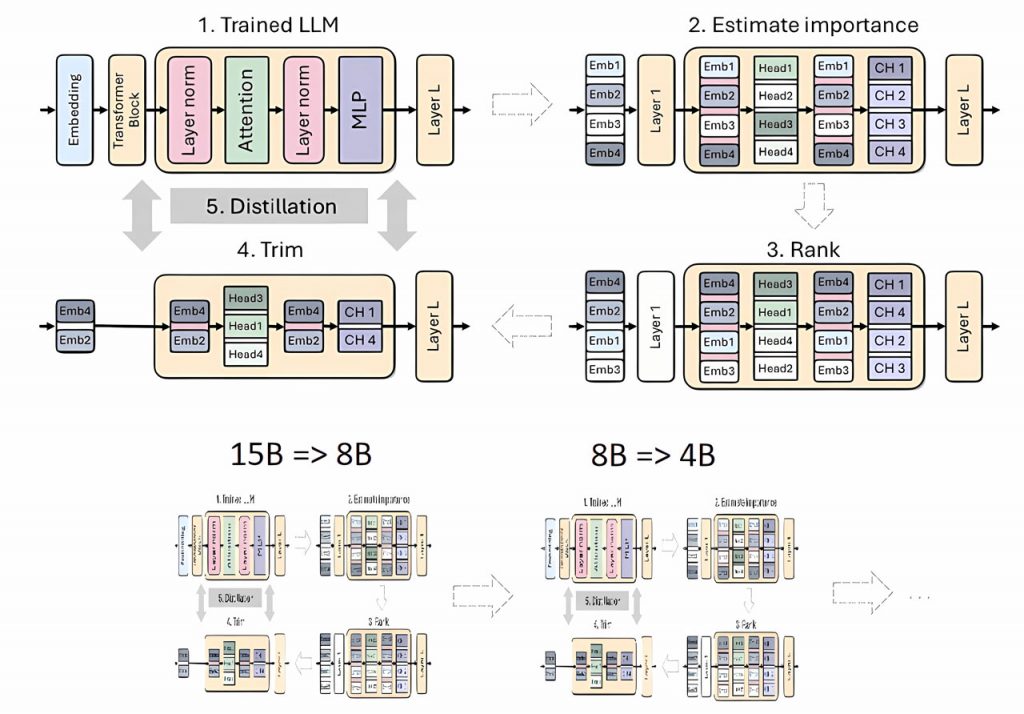
У попередніх дослідженнях Nvidia продемонструвала ефективність поєднання відсікання з класичною дистиляцією знань. Почавши з моделі Nemotron 15B, команда поступово скорочувала та дистилювала її до моделі з 8 мільярдами параметрів. Після легкої процедури перенавчання з використанням дистиляції моделі, вони створили меншу модель 4B. Цей метод забезпечив покращення продуктивності на 16% у популярному бенчмарку MMLU порівняно з навчанням моделі з 4 мільярдами параметрів з нуля, використовуючи в 40 разів менше токенів. Продуктивність була порівнянна з такими моделями, як Mistral 7B, Gemma 7B і Llama-3 8B, що навчалися на трильйонах токенів.
Створення Minitron 4B
Спираючись на свою попередню роботу, Nvidia застосувала ті ж самі методи до моделі Llama 3.1 8B, прагнучи створити версію з 4 мільярдами параметрів, яка могла б відповідати продуктивності більших моделей, але при цьому була б більш ефективною для навчання.
Першим кроком було точне налаштування необрізаної 8B моделі на наборі даних у 94 мільярди тегів, щоб виправити зсув розподілу між вихідними навчальними даними та дистиляційним набором даних. Ця корекція була необхідна для того, щоб модель вчителя забезпечувала оптимальне керування під час процесу дистиляції.
Далі дослідники застосували два типи відсікання: відсікання тільки по глибині, яке видалило 50% шарів, і відсікання тільки по ширині, яке видалило 50% нейронів з деяких щільних шарів в трансформаторних блоках. Це дозволило отримати дві різні версії моделі Llama-3.1-Minitron 4B.
Нарешті, обрізані моделі були доопрацьовані за допомогою NeMo-Aligner, інструментарію, що підтримує різні алгоритми вирівнювання, такі як навчання з підкріпленням на основі зворотного зв’язку з людиною (‘reinforcement learning from human feedback’, RLHF), пряма оптимізація переваг (DPO) та Nvidia’s SteerLM. Моделі оцінювали за їхніми здібностями у виконанні інструкцій, рольових іграх, генерації, доповненім пошуком («retrieval-augmented generation», RAG), та викликом функцій.
Результати та вплив
Попри меншу кількість навчальних даних, Llama-3.1-Minitron 4B продемонструвала результати, близькі до інших малих мовних моделей, таких як Phi-2 2.7B, Gemma2 2.6B та Qwen2-1.5B. Хоча вона щонайменше на 50% більша за ці моделі, її навчали на меншій частині даних, що підкреслює нову динаміку між витратами на навчання і висновками.
Обрізана по ширині версія моделі Llama-3.1-Minitron 4B була випущена на Hugging Face під ліцензією Nvidia Open Model License, що дозволяє комерційне використання. Це робить модель доступною для ширшого кола користувачів і розробників, які можуть скористатися її ефективністю та продуктивністю.
Майбутнє економічно ефективної розробки моделей ШІ
Дослідження Nvidia демонструє високу економічну ефективність відсікання та класичної дистиляції знань при створенні менших за розміром та високопродуктивних мовних моделей. Ці методи пропонують більш ефективну та економну альтернативу навчанню моделей з нуля, забезпечуючи високий ступінь деталізації в різних галузях.
Досягнутий прогрес підкреслює цінність розробки з відкритим вихідним кодом для розвитку досліджень у галузі ШІ. Ці інновації дають змогу компаніям оптимізувати та налаштовувати великі мовні моделі за частку традиційних витрат, прокладаючи шлях до більш доступних та ефективних рішень у сфері ШІ.
)
)
)
)
)
)
)
)
