

14.05.2024 13:45
Масштабування мультимодального ШІ за допомогою CuMo
Поява великих мовних моделей на кшталт GPT-4 викликала жвавий попит на збагачення їх мультимодальними можливостями для сприйняття візуальних даних поряд із текстом. Однак попередні спроби створити надійні мультимодальні мовні моделі зіткнулися з проблемою ефективного масштабування при збереженні продуктивності. Щоб розв’язати цю проблему, дослідники черпали натхнення в архітектурі змішаних експертів (MoE), відомій завдяки масштабуванню LLM за допомогою розріджених експертних модулів замість щільних шарів.
У цьому підході численні менші експертні субмоделі спеціалізуються на окремих підмножинах даних, визначених мережею маршрутизації. Цей метод дозволяє більш ефективно масштабувати загальну потужність моделі.
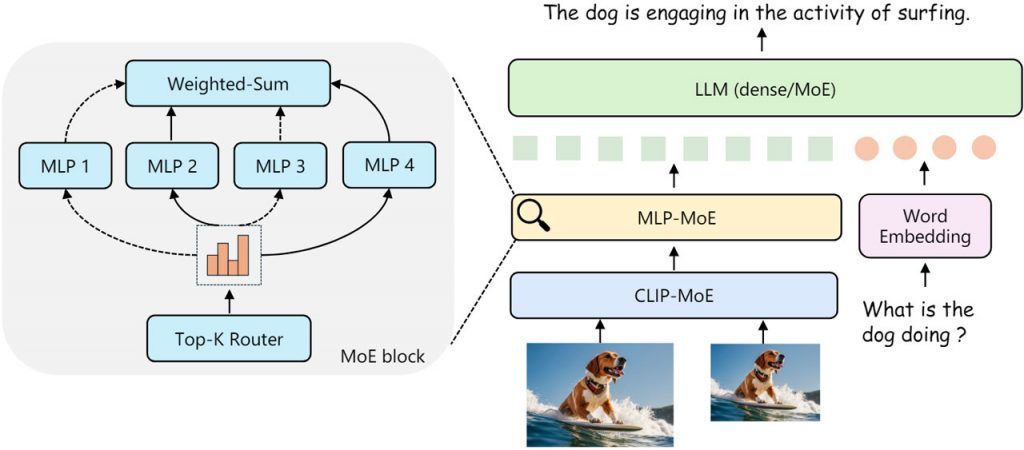
Використовуючи CuMo, дослідники інтегрували розріджені блоки MoE в кодер технічного зору і модуль мови технічного зору мультимодальної LLM. Це дозволяє різним експертним модулям обробляти різні аспекти візуальних і текстових вхідних даних одночасно, а не покладатися на одну модель для всебічного аналізу.
Ключовим нововведенням є спільне використання, за якого розріджені модулі MoE перед налаштуванням отримують інформацію з попередньо навченої моделі. Такий підхід забезпечує кращу стартову позицію для спеціалізації експертів під час навчання.
CuMo проходить триетапний процес навчання: попереднє навчання з’єднувача мови зору на даних зображення-тексту, таких як LLaVA, потім попереднє налаштування всіх параметрів моделі спільно на даних підписів з ALLaVA, і насамкінець точне налаштування за допомогою даних візуальних інструкцій з наборів даних, таких як VQAv2, GQA і LLaVA-Wild, з введенням розріджених блоків MoE разом з допоміжними втратами, щоб збалансувати навантаження на експерта і стабілізувати навчання.
Оцінка моделей CuMo на різних тестах і завданнях показала вищу продуктивність порівняно з іншими підходами, навіть при менших розмірах моделей. Ці результати підкреслюють потенціал розріджених архітектур MoE у поєднанні зі спільним використанням для створення ефективних і водночас потужних мультимодальних асистентів ШІ. Відкритий код CuMo може прокласти шлях до просунутих систем ШІ, здатних розуміти й міркувати про текст, зображення і не тільки.
)
)
)
)
)
)
)
)
