

29.09.2023 16:56
Як навчити спеціалізовану невелику модель машинного навчання з меншою кількістю даних
В останні роки великі мовні моделі (Large Language Models, LLM) трансформували обробку природної мови, уможлививши навчання з нульовою та малою кількістю кроків. Однак їхні високі обчислювальні вимоги, особливо моделей з мільярдами параметрів, обмежили їхню доступність для багатьох дослідницьких команд. Щоб вирішити цю проблему, дослідники з Google та Університету Вашингтона представили на ACL2023 технологію “Distilling Step-by-Step”.
Цей інноваційний підхід має на меті збалансувати розмір моделі та витрати на збір даних шляхом вилучення інформативних обґрунтувань природною мовою з LLM. Ці обґрунтування слугують додатковим навчальним наглядом для менших моделей для конкретних завдань поряд зі стандартними мітками завдань.
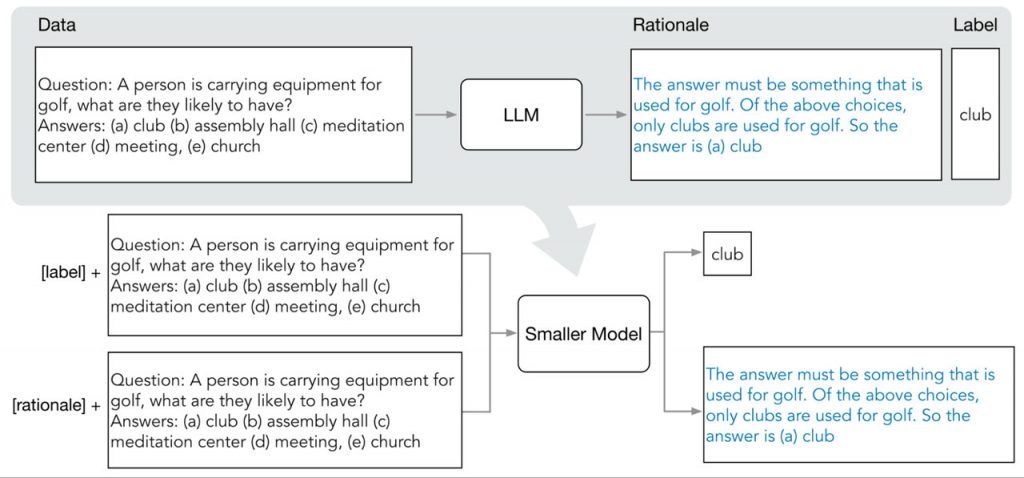
Покроковий процес дистиляції складається з двох етапів. На першому етапі для вилучення обґрунтувань з LLM використовується метод “ланцюга міркувань” (Chain of Thought, CoT), що дозволяє йому генерувати обґрунтування для невидимих вхідних даних. Потім ці міркування інтегруються в навчання менших моделей за допомогою багатозадачної навчальної системи, де префікси завдань керують розрізненням моделі між прогнозуванням міток і генеруванням міркувань.
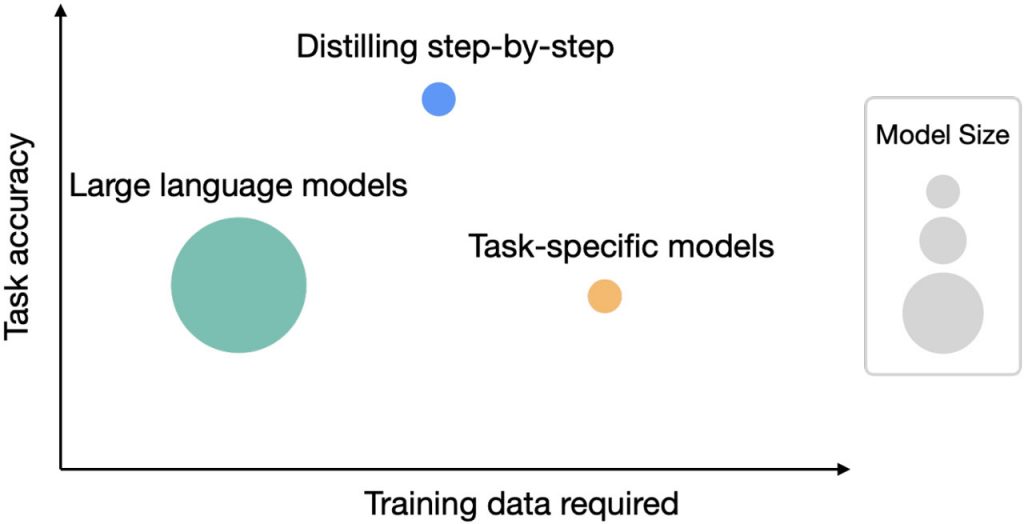
В експериментах з використанням моделей LLM і T5 на 540 мільярдів параметрів для подальших завдань Distilling Step-by-Step продемонстрував вражаючий приріст продуктивності при зменшених вимогах до даних. Наприклад, на наборі даних e-SNLI він перевершив стандартну точну настройку, використавши лише 12,5% від повного набору даних. Аналогічне зменшення розміру набору даних спостерігалося в різних завданнях обробки природної мови.
Крім того, Distilling Step-by-Step продемонстрував потенціал для підвищення ефективності завдяки досягненню вищої продуктивності при значно менших розмірах моделей порівняно з LLM на основі методу “ланцюжка міркувань”, який передбачає кілька спроб. Наприклад, модель T5 з 220 мільйонами параметрів перевершила продуктивність PaLM з 540 мільярдами параметрів на наборі даних e-SNLI. На ANLI модель T5 з 770 мільйонами параметрів перевершила PaLM з 540 мільярдами параметрів у понад 700 разів, що свідчить про підвищення ефективності.
Примітно, що цей підхід перевершив LLM з кількома пострілами, використовуючи менші моделі і меншу кількість даних. Наприклад, в ANLI модель T5 з 770 мільйонами параметрів перевершила продуктивність PaLM з 540 мільярдами параметрів, використовуючи лише 80% повного набору даних, чого неможливо досягти за допомогою стандартного точного налаштування.
На завершення, Distilling Step-by-Step представляє новаторський підхід до навчання невеликих моделей, орієнтованих на конкретні задачі. Витягуючи обґрунтування з LLM, він зменшує вимоги до даних для навчання моделей і дозволяє використовувати значно менші моделі. Ця інноваційна методика має потенціал для демократизації обробки природної мови, роблячи просунуті мовні моделі більш доступними та практичними для різних застосувань.
)
)
)
)
)
)
)
)
