

26.03.2024 16:17
Як дослідники з UC Berkeley, ICSI та LBNL підвищують продуктивність великих мовних моделей
Методологія LLM2LLM, запропонована дослідницькою групою Каліфорнійського університету в Берклі, Інститутом корпоративних секретарів Індії та Національною лабораторією Лоуренса Берклі, пропонує новий підхід до розширення можливостей великих мовних моделей у сценаріях з низьким рівнем даних. На відміну від звичайних методів доповнення даних, які покладаються на спрощені маніпуляції, LLM2LLM використовує ітеративний процес за участю двох LLM, тобто моделі вчителя та моделі учня, для усунення конкретних недоліків та покращення продуктивності моделі.
Основна ідея LLM2LLM полягає в цілеспрямованому створенні даних для забезпечення оптимального доповнення набору навчальних даних. Спочатку модель учня налаштовується на обмеженому наборі даних і оцінюється, щоб виявити слабкі місця, де її прогнози є неточними. Потім модель викладача генерує синтетичні дані, які імітують ці складні приклади, створюючи новий навчальний набір, орієнтований на поліпшення продуктивності моделі студента при виконанні конкретних завдань.
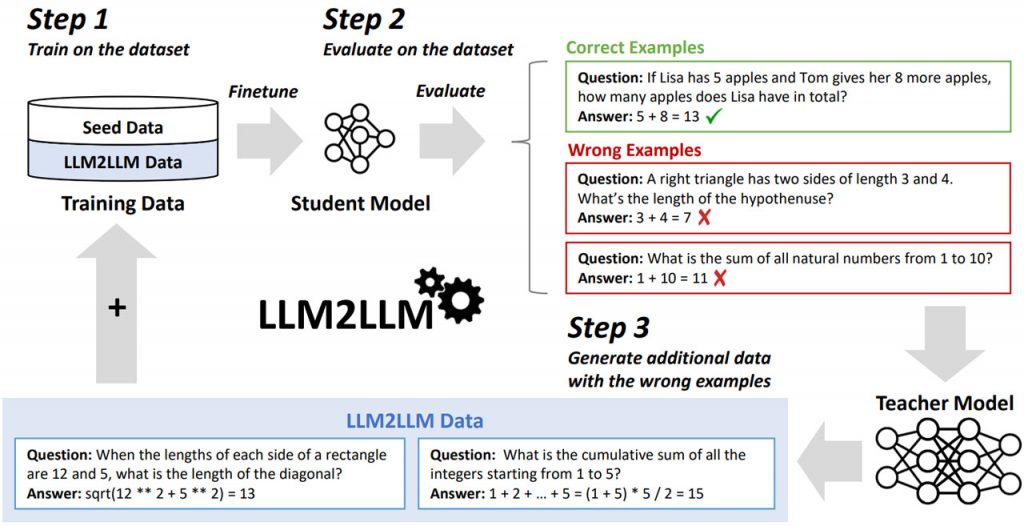
Ключова перевага LLM2LLM полягає в ітеративному та цілеспрямованому підході до доповнення даних. Замість того, щоб наосліп збільшувати розмір набору даних, він генерує нові дані стратегічно, усуваючи слабкі місця моделі. Ця методологія була протестована на різних наборах даних, включаючи GSM8K, CaseHOLD і SNIPS, продемонструвавши значне поліпшення продуктивності моделі від 24,2% до 32,6%.
Таким чином, LLM2LLM представляє надійне рішення проблеми дефіциту даних при навчанні LLM. Використовуючи одну велику мовну модель для покращення іншої, вона пропонує ефективний шлях до точного налаштування моделей для конкретних завдань з обмеженими початковими даними. Успіх LLM2LLM у покращенні продуктивності моделей перевершує традиційні методи доповнення та точного налаштування даних, що підкреслює його потенціал для здійснення прориву в навчанні та застосуванні LLM в задачах обробки природної мови.
)
)
)
)
)
)
)
)
