

31.07.2023 12:35
Використання ШІ для захисту від маніпуляцій із зображеннями
PhotoGuard, розроблений дослідниками MIT CSAIL, запобігає несанкціонованому маніпулюванню зображеннями та забезпечує автентичність в епоху просунутих генеративних моделей.
Оскільки ми вступаємо в нову еру, в якій технології на основі штучного інтелекту можуть створювати і маніпулювати зображеннями з точністю, що розмиває межу між реальністю і вигадкою, привид зловживань стає все більшим і більшим. Нещодавно передові генеративні моделі, такі як DALL-E і Midjourney, відомі своєю вражаючою точністю і зручним інтерфейсом, зробили виробництво гіперреалістичних зображень відносно легким. Завдяки зниженню бар’єрів для входу, навіть недосвідчені користувачі можуть створювати високоякісні зображення і маніпулювати ними на основі простих текстових описів – від невинних до зловмисних змін. Такі технології, як нанесення водяних знаків, пропонують багатообіцяюче рішення, але зловживання вимагає превентивних (а не реактивних) заходів.
У пошуках такого нового заходу дослідники з Лабораторії комп’ютерних наук і штучного інтелекту (CSAIL) Массачусетського технологічного інституту розробили PhotoGuard – технологію, яка використовує збурення – крихітні зміни значень пікселів, невидимі для людського ока, але помітні для комп’ютерних моделей – для ефективного підриву здатності моделі маніпулювати зображенням.
PhotoGuard використовує два різні методи “атаки” для створення цих збурень. Простіша атака “енкодера” націлена на приховане представлення зображення в моделі ШІ, змушуючи модель сприймати зображення як випадковий об’єкт. Більш складна атака “дифузії” визначає цільове зображення та оптимізує збурення так, щоб кінцеве зображення було максимально схожим на цільове.
“Розглянемо можливість шахрайського поширення фейкових катастрофічних подій, таких як вибух на великій пам’ятці. Такий обман може маніпулювати ринковими тенденціями та суспільними настроями, але ризики не обмежуються публічною сферою. Особисті зображення можуть бути неналежним чином змінені і використані для шантажу, що має значні фінансові наслідки, якщо це робиться у великих масштабах”, – говорить Хаді Салман, аспірант Массачусетського технологічного інституту в галузі електротехніки та комп’ютерних наук (EECS), що є філією MIT CSAIL, і провідний автор нової статті про PhotoGuard.
“У більш екстремальних сценаріях ці моделі можуть імітувати голоси та зображення для інсценування фальшивих злочинів, завдаючи психологічних страждань і фінансових втрат. Швидка природа цих дій загострює проблему. Навіть якщо шахрайство врешті-решт розкривається, шкода – репутаційна, емоційна чи фінансова – часто вже завдана. Це реальність для жертв на всіх рівнях – від окремих осіб, яких цькують у школі, до маніпуляцій у суспільстві в цілому.”
PhotoGuard на практиці
ШІ-моделі дивляться на зображення інакше, ніж люди. Вони бачать зображення як складний набір математичних точок, які описують колір і положення кожного пікселя – це приховане представлення зображення. Атака “енкодера” вносить невеликі корективи в це математичне представлення, змушуючи ШІ-модель сприймати зображення як випадковий об’єкт. Як наслідок, будь-яка спроба моделі маніпулювати зображенням стає майже неможливою. Зміни, що вносяться, настільки малі, що вони непомітні для людського ока, таким чином зберігаючи візуальну цілісність зображення та захищаючи його.
Друга і, безумовно, складніша “дифузійна” атака стратегічно націлена на всю дифузійну модель від початку до кінця. Це передбачає визначення бажаного цільового зображення, а потім запуск процесу оптимізації з метою зробити згенероване зображення максимально наближеним до попередньо обраної цілі.
Під час реалізації команда створила збурення у вхідному просторі оригінального зображення. Ці збурення потім використовуються на етапі виведення і застосовуються до зображень, забезпечуючи надійний захист від несанкціонованих маніпуляцій.
“Прогрес у галузі ШІ, який ми спостерігаємо, справді захоплює дух, але він дає можливість як корисного, так і зловмисного використання ШІ, – каже професор Массачусетського технологічного інституту і головний дослідник CSAIL Олександр Мадрі, який також є автором статті. “Тому вкрай важливо, щоб ми працювали над виявленням і запобіганням зловмисному використанню ШІ. Я розглядаю PhotoGuard як наш невеликий внесок у цю важливу справу”.
Дифузійна атака є більш обчислювально інтенсивною, ніж її простіший побратим, і вимагає значного обсягу пам’яті графічного процесора. Команда каже, що апроксимація процесу дифузії меншою кількістю кроків пом’якшує цю проблему, роблячи техніку більш практичною.
Щоб краще проілюструвати атаку, розглянемо художній проект. Оригінальне зображення – це малюнок, а цільове зображення – інший малюнок, зовсім інший. Атака дифузії полягає у внесенні крихітних, непомітних змін до першого малюнка, так що для моделі ШІ він починає нагадувати другий малюнок. Однак для людського ока оригінальний малюнок залишається незмінним.
Як наслідок, будь-яка модель ШІ, що намагається модифікувати оригінальне зображення, ненавмисно вноситиме зміни так, ніби вона працює з цільовим зображенням, таким чином захищаючи оригінальне зображення від навмисних маніпуляцій. В результаті зображення залишається візуально незмінним для глядачів, але захищеним від несанкціонованих маніпуляцій з боку ШІ-моделей.
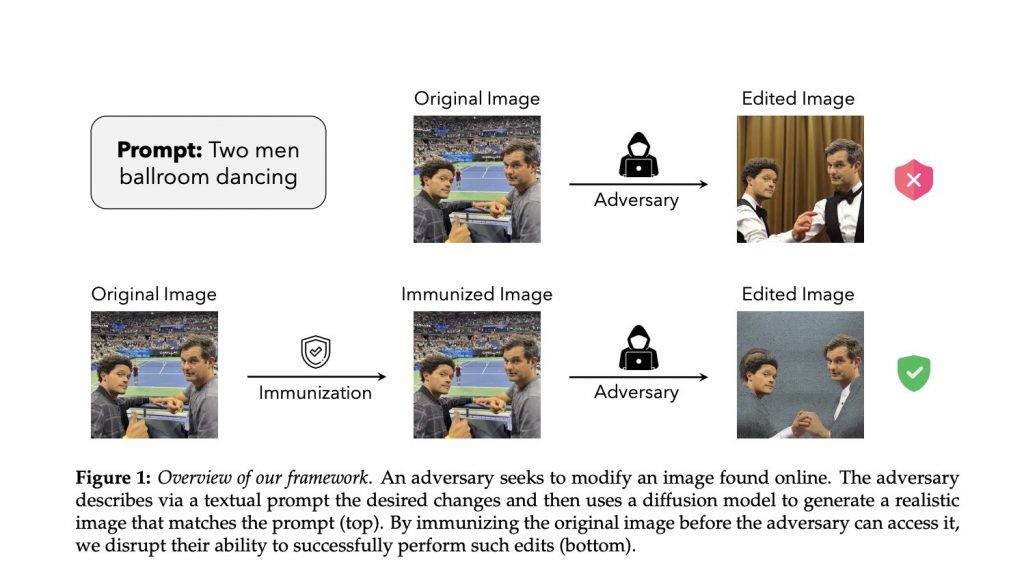
Для прикладу реального застосування PhotoGuard розглянемо зображення з кількома обличчями. Ви можете замаскувати всі обличчя, які не хочете змінювати, а потім ввести запит “двоє чоловіків на весіллі”. Система відкоригує зображення відповідно до запиту, створивши правдоподібне зображення двох чоловіків, які присутні на весільній церемонії.

Тепер подумайте про захист зображення від редагування; додавання збурень до зображення перед завантаженням може захистити його від змін. У цьому випадку кінцевому результату буде бракувати реалістичності порівняно з оригінальним, не захищеним зображенням.
Гукати всіх нагору
Ключовими союзниками в боротьбі з маніпуляціями з зображеннями є творці моделей маніпуляцій з зображеннями, каже команда. Щоб PhotoGuard був ефективним, необхідна комплексна реакція всіх зацікавлених сторін.
“Політики повинні розглянути можливість впровадження правил, які вимагають від компаній захищати дані користувачів від таких маніпуляцій. Розробники цих моделей штучного інтелекту могли б створити API, які автоматично додають спотворення до зображень користувачів, забезпечуючи додатковий рівень захисту від несанкціонованого редагування”, – каже Салман.
Незважаючи на свої обіцянки, PhotoGuard не є панацеєю. Як тільки зображення потрапляє в мережу, люди зі зловмисними намірами можуть спробувати обійти захист, додавши шум, обрізавши або повернувши зображення. Однак, існує велика кількість попередніх напрацювань з літератури про приклади зловмисників, які можуть бути використані тут для реалізації надійних збурень, що протистоять поширеним маніпуляціям із зображеннями.
“Спільний підхід за участю розробників моделей, платформ соціальних мереж і політиків забезпечує надійний захист від несанкціонованих маніпуляцій з іміджем. Робота над цим нагальним питанням сьогодні має першорядне значення, – каже Салман. “І хоча я радий бути частиною цього рішення, потрібно ще багато працювати, щоб зробити цей захист практичним. Компанії, що розробляють ці моделі, повинні інвестувати в розробку надійних засобів захисту від потенційних загроз, які несуть у собі ці інструменти штучного інтелекту. Вступаючи в нову еру генеративних моделей, давайте прагнути як до потенціалу, так і до захисту”.
“Перспектива використання атак на машинне навчання для захисту від зловживань цією технологією є дуже переконливою, – каже Флоріан Трамер, доцент Швейцарської вищої технічної школи Цюріха. “У статті є гарне розуміння того, що розробники генеративних моделей ШІ мають сильні стимули надавати такий захист своїм користувачам, що в майбутньому може навіть стати законодавчою вимогою. Однак розробка засобів захисту зображень, які ефективно протистоятимуть спробам обходу, є складною проблемою: як тільки компанія-розробник генеративного ШІ візьме на себе зобов’язання щодо механізму імунізації, а люди почнуть застосовувати його до своїх онлайн-зображень, ми повинні забезпечити, щоб цей захист працював проти вмотивованих супротивників, які можуть навіть використовувати кращі моделі генеративного ШІ, розроблені в найближчому майбутньому. Розробка такого надійного захисту – складна і відкрита проблема, і ця стаття переконливо доводить, що компанії, які розробляють генеративний ШІ, повинні працювати над її вирішенням”.
Салман написав статтю разом зі співавторами Алаа Хаддадж та Гійомом Леклерком (Alaa Khaddaj, MS ’18), а також Ендрю Ільясом (Andrew Ilyas, MEng ’18); всі троє є аспірантами EECS та стипендіатами MIT CSAIL. Робота команди проводилася частково на обчислювальному кластері MIT Supercloud за підтримки грантів Національного наукового фонду США та Open Philanthropy, а також ґрунтується на роботі, підтриманій Агентством передових оборонних дослідницьких проектів Міністерства оборони США. Вона була представлена на Міжнародній конференції з машинного навчання в липні цього року.
)
)
)
)
)
)
)
)
