

30.08.2023 17:30
UW-Medison пропонують ефективні трансформери для розпізнавання відео
Нещодавно трансформери, розроблені переважно для мовних завдань, стали розглядатися як потенційні архітектури для завдань, пов’язаних із зором. Трансформатори зору продемонстрували виняткову продуктивність у таких завданнях, як розпізнавання об’єктів, класифікація зображень і відео. Однак їхня ефективність стримується високими витратами на обробку даних. Порівняно зі стандартними згортковими мережами (CNN), трансформатори зору можуть вимагати значно більшої обчислювальної потужності, навіть сотні GFlops на зображення. Цей недолік стає ще більш помітним при обробці відео через значний обсяг даних.
Дослідники з Університету Вісконсину-Медісон представили методику, яка дозволяє зменшити витрати на обробку трансформаторів зору при роботі з відеоданими. Вони пропонують застосовувати трансформатор зору до відеопослідовностей кадр за кадром або кліп за кліпом. Такий підхід дозволяє повторно використовувати проміжні обчислення з попередніх кроків, краще використовуючи часову надлишковість. Незважаючи на часову надлишковість і мінімальні варіації кадрів у природному відео, глибокі мережі, наприклад трансформери, часто перераховують кожен кадр з нуля, що є неефективним.
Підхід дослідників спрямований на підвищення ефективності шляхом повторного використання даних з попередніх висновків, представляючи більш інтелектуальний процес виведення. У реальних застосуваннях обчислювальні витрати на трансформацію зору можуть змінюватися через зміну ресурсів, таких як конкуруючі процеси або перебої в електропостачанні. Таким чином, їхнє дослідження підкреслює адаптивність як ключову мету проектування, спрямовану на забезпечення можливості коригування обчислювальних витрат у реальному часі. У дослідженні представлено підхід, який пропонує контроль над обчислювальними витратами в реальному часі, висвітлюючи, як вони коригують бюджет під час зйомок фільму, щоб проілюструвати ефективність свого методу.
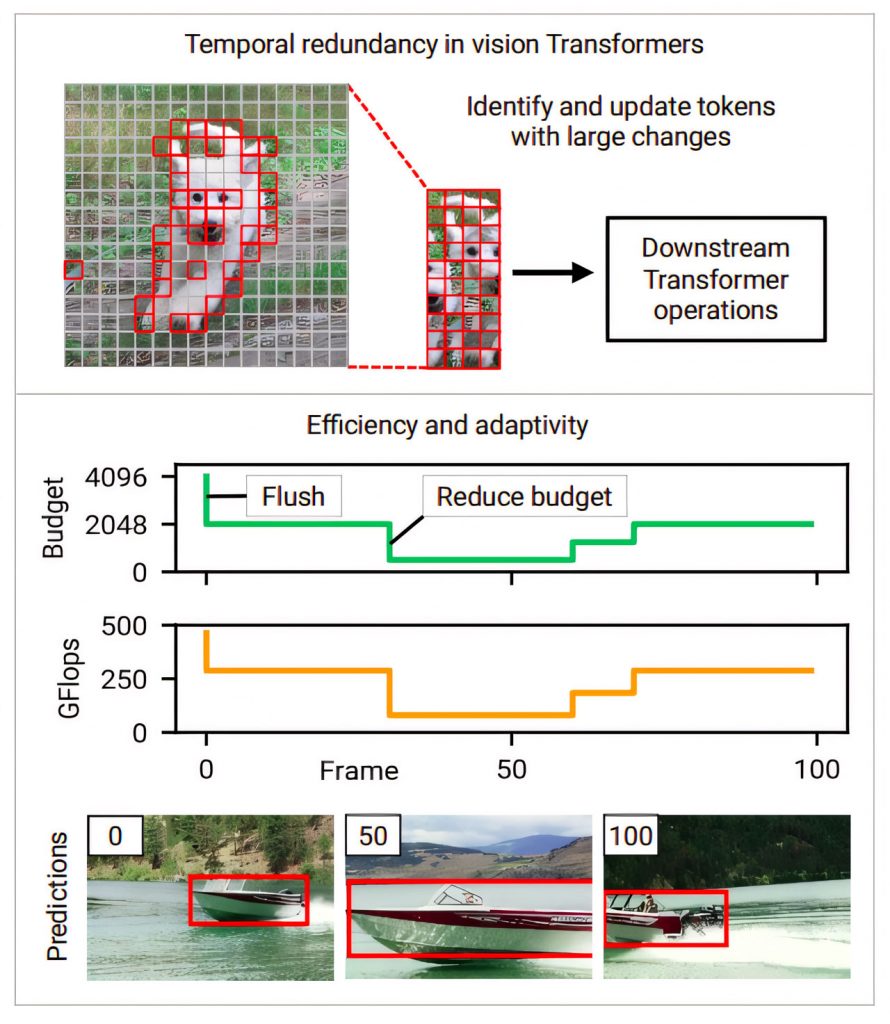
Попередні дослідження вивчали часову надлишковість та адаптивність у CNN, але ці підходи нелегко сумісні з трансформерами через їхню відмінну архітектуру. Трансформери вводять унікальний елемент — самоуважність, який відрізняється від CNN. Перенесення переваг розрідженості з CNN на трансформери є складним через відмінності в структурі, але природа трансформерів полегшує застосування розрідженості для скорочення часу виконання за допомогою звичайних операторів.
Для вирішення цієї проблеми запропоновано Eventful Transformers, які використовують часову надлишковість між вхідними даними для адаптивного виведення. Ці трансформатори оновлюють представлення токенів і карти самоуваги на кожному часовому кроці, щоб відстежувати зміни з часом. Модулі воріт дозволяють керувати оновленими токенами під час виконання. Eventful Transformers значно знижують обчислювальні витрати, зберігаючи при цьому точність. Їхній підхід працює з різними додатками для обробки відео і може бути застосований до готових моделей без перенавчання. Вихідний код для створення Eventful Transformers за допомогою модулів PyTorch знаходиться у відкритому доступі.
Хоча вони демонструють прискорення обробки на CPU і GPU, є місце для технічного вдосконалення. Оптимізація накладних витрат може ще більше підвищити коефіцієнт прискорення. Варто зауважити, що запропонований підхід передбачає неминучі витрати пам’яті, оскільки збереження певних тензорів необхідне для повторного використання обчислень з попередніх часових кроків.
)
)
)
)
)
)
)
)
