

20.11.2023 17:33
Синтетичні зображення встановлюють нову планку ефективності навчання ШІ
Дослідники Массачусетського технологічного інституту створюють більше, ніж просто пікселі, використовуючи синтетичні зображення для навчання моделей машинного навчання. Завдяки системі під назвою StableRep вони генерують синтетичні зображення за допомогою моделей “текст-зображення”, таких як Stable Diffusion, використовуючи стратегію під назвою “багатопозитивне контрастне навчання”. Цей підхід розглядає кілька зображень, згенерованих з одного тексту, як позитивні пари, заглиблюючись у концепції високого рівня. StableRep перевершує найкращі моделі, навчені на реальних зображеннях, вирішуючи проблеми зі збором даних і відкриваючи нову еру економічно ефективного навчання штучного інтелекту. Регулювання шкали наведення в генеративній моделі досягає тонкого балансу, роблячи синтетичні зображення настільки ж ефективними, якщо не більш ефективними, ніж реальні.
Мовний контроль, доданий у StableRep+, підвищує точність і ефективність, перевершуючи моделі, навчені на великій кількості реальних зображень. Подальший шлях передбачає подолання таких обмежень, як повільна генерація зображень, семантичні невідповідності, упередження та складнощі з атрибуцією зображень. Визнаючи необхідність починати з реальних даних, команда наголошує на перепрофілюванні якісної генеративної моделі для нових завдань. StableRep, зменшуючи залежність від великих колекцій реальних зображень, викликає занепокоєння щодо прихованих упереджень у необроблених даних. Ретельний відбір текстових підказок має вирішальне значення для зменшення упередженості, що підкреслює необхідність постійного покращення якості даних та їх синтезу.
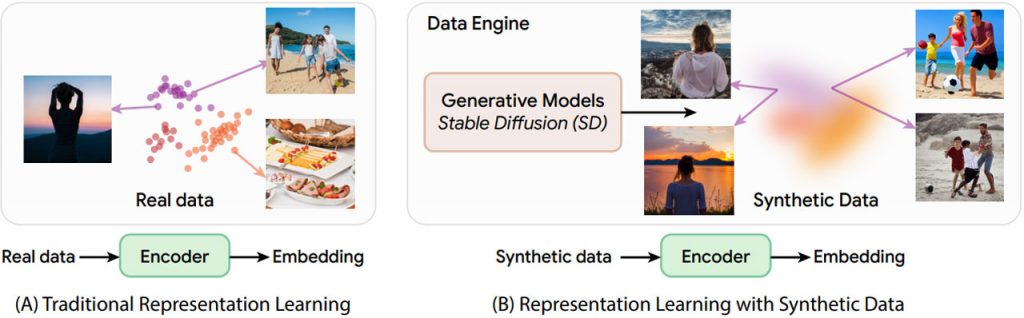
Дослідники Массачусетського технологічного інституту отримали безпрецедентний контроль над генерацією зображень, перевершивши за ефективністю та універсальністю збір зображень у реальному світі. Цей підхід виявляється корисним у таких завданнях, як балансування різноманітності зображень при розпізнаванні зображень з довгим ланцюжком, пропонуючи практичне доповнення до використання реальних зображень для навчання. Ця робота є кроком вперед у візуальному навчанні, надаючи економічно ефективні альтернативи навчанню та підкреслюючи важливість постійного вдосконалення якості та синтезу даних.
Дослідник Google DeepMind Девід Фліт відзначає давню мрію про навчання генеративних моделей для отримання даних, корисних для навчання дискримінативних моделей. Ця мрія стає реальністю, показуючи, що контрастне навчання на основі величезних обсягів даних синтетичних зображень може створювати зображення, що перевершують ті, які були отримані на основі реальних даних в масштабі, з потенціалом для поліпшення подальших завдань технічного зору.
Провідні автори дослідження Ліцзе Фан та Юнлун Тіан, а також професор Массачусетського технологічного інституту Філіп Ізола, Хуйвен Чанг з Google та Діліп Крішнан представлять StableRep на Конференції з нейронних систем обробки інформації (NeurIPS) 2023 року в Новому Орлеані.
)
)
)
)
)
)
)
)
