

24.05.2024 12:57
ШІ та теорія розуму: чи можуть GPT-4 та LLaMA-2 мислити як люди?
Дослідники з Університетського медичного центру Гамбург-Еппендорф, Італійського технологічного інституту в Генуї, Університету Тренто та інших інституцій дослідили, чи здатні великі мовні моделі (LLM), такі як GPT-4, GPT-3.5 та LLaMA2-70B, розуміти людські думки та емоції.
Теорія розуму — це здатність приписувати психічні стани собі та іншим. Вона є основою людської соціальної взаємодії. З розвитком штучного інтелекту (ШІ) та LLM виникає питання, чи зможуть вони коли-небудь досягти такого ж рівня розуміння соціальних нюансів, як люди.
Дослідження
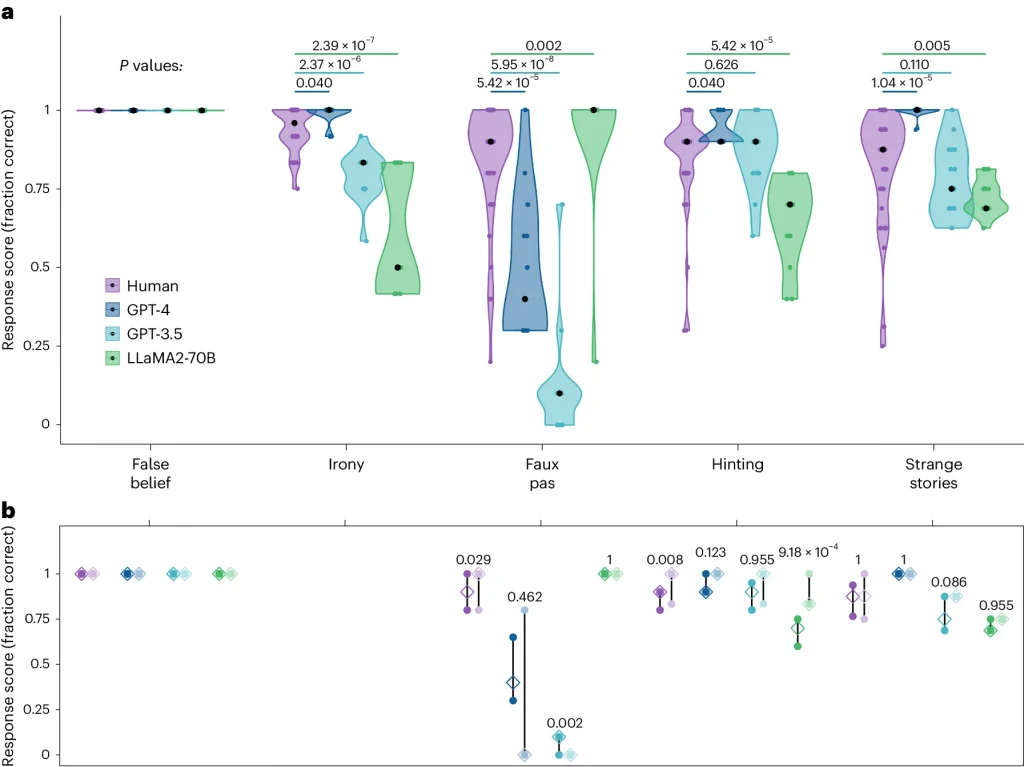
Дослідники провели серію тестів на теорію розуму з LLM та людьми. Тести включали завдання на розуміння іронії, розпізнавання хибних переконань та інтерпретацію складних соціальних ситуацій.
Результати
- GPT-4 показав сильні результати в тестах на розуміння іронії та натяків, часто перевершуючи людей. Однак він бореться з невизначеними сценаріями, де не вистачає чітких доказів.
- GPT-3.5 та LLaMA2-70B мали схильність до підтвердження невідповідних тверджень, що свідчить про те, що їм важче розрізняти правду та вигадку.
- Всі LLM були обережні у своїх відповідях, щоб уникнути помилок. Це може бути пов’язано з тим, що їх навчають на величезних обсягах даних, які можуть містити помилки та неточності.
- Відсутність тіла у LLM може також впливати на їхню здатність розуміти соціальні ситуації. Люди використовують не лише слова, але й невербальні сигнали, такі як вираз обличчя та мова тіла, щоб інтерпретувати соціальні взаємодії. LLM не мають такої можливості.
Висновок
Дослідження показало, що LLM, такі як GPT-4, досягли значного прогресу в розумінні людської мови та поведінки. Однак вони все ще не здатні досягти такого ж рівня розуміння соціальних нюансів, як люди. Це важливий момент, який слід враховувати при розробці ШІ-систем, які повинні взаємодіяти з людьми.
Нагадаємо, дослідження Google DeepMind у лютому виявило недоліки критичного мислення у великих мовних моделях
)
)
)
)
)
)
)
)
