

02.08.2023 11:41
ШІ-генератор зображень що вміщується на дискеті
Новий генератор зображень Perfusion від Nvidia займає 100 КБ місця і потребує лише 4 хвилини навчання.
Дослідники Nvidia представили новий інноваційний метод персоналізації “текст-зображення” під назвою Perfusion, який швидко розвивається на ринку ШІ-арт інструментів. Але, на відміну від конкурентів, це не надважка модель вартістю в мільйон доларів. Маючи розмір всього 100 КБ і 4-хвилинний час навчання, Perfusion забезпечує значну творчу гнучкість у зображенні персоналізованих концепцій, зберігаючи при цьому їхню ідентичність.
Perfusion був представлений у дослідницькій роботі, створеній Nvidia та Тель-Авівським університетом в Ізраїлі. Незважаючи на свій невеликий розмір, цей метод здатен перевершити провідні арт-генератори на базі ШІ, такі як Stable Diffusion v1.5 від Stability AI, нещодавно випущений Stable Diffusion XL (SDXL) та MidJourney, за ефективністю конкретних видань.

Основна нова ідея Perfusion називається “Key-Locking”. Вона полягає в тому, що під час генерації зображень нові поняття, які користувач хоче додати, наприклад, конкретного кота чи крісло, пов’язуються з більш загальною категорією. Наприклад, кішка буде пов’язана з ширшим поняттям “котячі”.
Це допомагає уникнути переналаштування, коли модель занадто глибоко фокусується під точні навчальні приклади. Надмірне пристосування ускладнює створення штучним інтелектом нових креативних версій концепції.
Прив’язуючи нового кота до загального уявлення про котячих, модель може зображати його в різних позах, вигляді та оточенні. Але вона все одно зберігає основну “котячу сутність”, яка робить її схожою на передбачуваного кота, а не на будь-яку іншу котячу тварину.
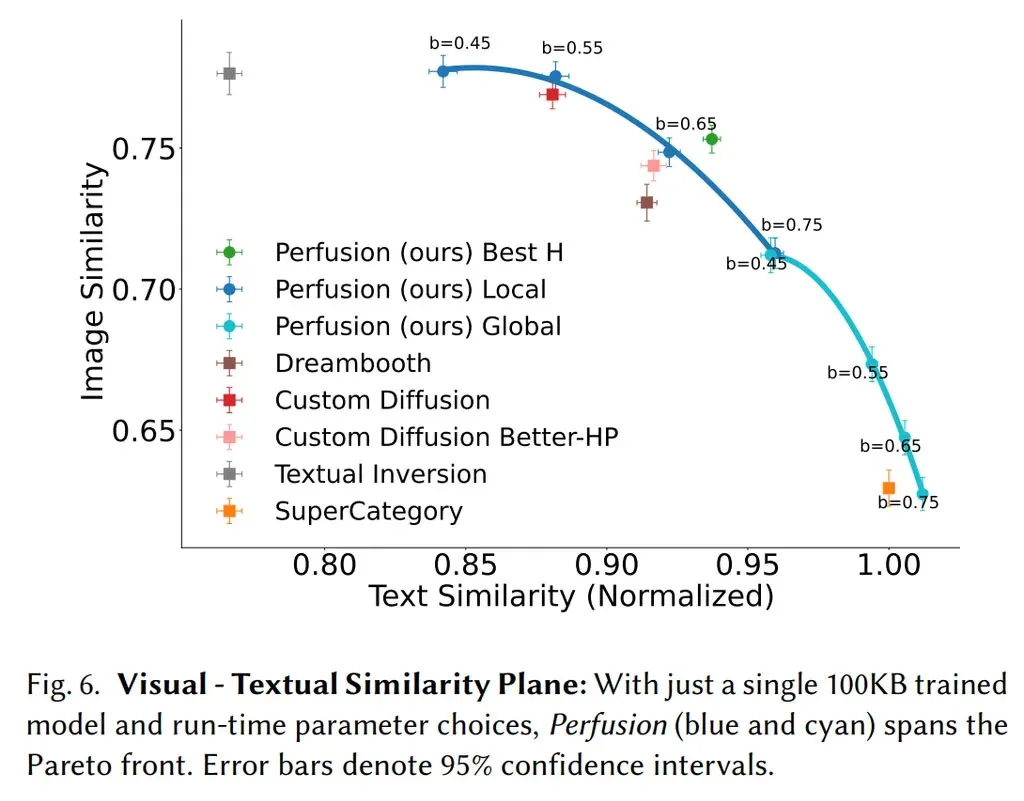
Perfusion дозволяє користувачам контролювати баланс між візуальною точністю (зображення) і текстовим вирівнюванням (підказка) під час виведення шляхом налаштування єдиної моделі розміром 100 КБ. Ця можливість дозволяє користувачам легко досліджувати межу ефективності Парето (схожість тексту проти схожості зображення) і вибирати оптимальний компроміс, який відповідає їхнім конкретним потребам, і все це без необхідності перенавчання. Важливо зазначити, що навчання моделі вимагає певної витонченості. Надмірне зосередження на відтворенні моделі призводить до того, що модель знову і знову видає один і той самий результат, а надто точне наслідування підказки без свободи дій зазвичай призводить до поганого результату. Гнучкість у налаштуванні того, наскільки генератор наближається до підказки, є важливим елементом кастомізації.
Інші генератори зображень зі штучним інтелектом мають способи точного налаштування результатів, але вони громіздкі. Для порівняння, LoRA — це популярний метод точного налаштування, який використовується в Stable Diffusion. Він може додати до програми від десятків мегабайт до більш ніж одного гігабайта (ГБ). Інший метод — вбудовування текстової інверсії — легший, але менш точний. Модель, навчена за допомогою Dreambooth, найточнішого методу на сьогодні, важить понад 2 ГБ.
Nvidia стверджує, що Perfusion забезпечує кращу якість зображення та узгодження з підказками порівняно з провідними методами штучного інтелекту, згаданими раніше. Ультра-ефективний розмір дозволяє просто оновлювати необхідні частини під час точного налаштування зображення, порівняно з багатогігабайтними методами, які потребують точного налаштування всієї моделі.
Це дослідження корелює зі зростаючою увагою Nvidia до ШІ. Акції компанії зросли більш ніж на 230% у 2023 році, оскільки її графічні процесори продовжують домінувати у навчанні моделей штучного інтелекту. Оскільки такі компанії, як Anthropic, Google, Microsoft і Baidu, вкладають мільярди в генеративний штучний інтелект, інноваційна модель Perfusion від Nvidia може дати їм фору.
Nvidia поки що представила лише дослідницьку роботу, пообіцявши незабаром випустити код.
)
)
)
)
)
)
)
)
