

28.09.2023 16:25
Секрети мультимодальних нейронів: від Моліньє до трансформерів
Трансформери є трансформаційною інновацією у сфері штучного інтелекту. Ці нейромережеві архітектури, представлені у 2017 році, докорінно змінили те, як машини розуміють і генерують людську мову.
На відміну від своїх попередників, трансформери використовують механізми самоуваги для паралельної обробки даних, що дозволяє їм розпізнавати приховані зв’язки та залежності в послідовності інформації. Ця можливість паралельної обробки не тільки прискорює час навчання, але й прокладає шлях для розробки високотехнологічних моделей, прикладом яких є відомий ChatGPT.
За останні роки штучні нейронні мережі продемонстрували неабияку майстерність у різних сферах, від мовних завдань до проблем, пов’язаних із зором. Однак їхній справжній потенціал розкривається в крос-модальних завданнях, де вони легко інтегрують сенсорні модальності, такі як зір і текст. Ці моделі, підсилені додатковими сенсорними входами, досягли видатних результатів у завданнях, що вимагають розуміння та обробки інформації з різних джерел.
Проблема Моліньйо, вперше представлена філософом Вільямом Моліньйо у 1688 році Джону Локку, продовжує захоплювати науковців. Вона ставить глибоке питання: Якби сліпа від народження людина прозріла, чи змогла б вона розпізнавати об’єкти, які раніше були відомі лише за допомогою дотику та інших невізуальних відчуттів? Це дослідження на перетині філософії та науки про зір вивчає здатність людського мозку до адаптації.
У 2011 році нейробіологи, які вивчають зір, розпочали місію, щоб відповісти на це давнє питання. Їхні висновки показали, що миттєве візуальне розпізнавання об’єктів, до яких раніше можна було доторкнутися лише на дотик, є малоймовірним. Однак, чудовим відкриттям стала здатність мозку до адаптації. За кілька днів після операції з відновлення зору люди могли швидко навчитися візуально розпізнавати об’єкти, долаючи розрив між сенсорними модальностями.
Виникає питання: Чи справедливий феномен сенсорної інтеграції для мультимодальних нейронів у штучних нейронних мережах?
Ми перебуваємо в епоху технологічної революції, коли штучні нейронні мережі, особливо ті, що навчені вирішувати мовні завдання, демонструють вражаючі можливості в крос-модальних дослідженнях. Ці моделі, доповнені додатковими сенсорними даними, чудово справляються із завданнями, що вимагають інтеграції та осмислення інформації з різних джерел.
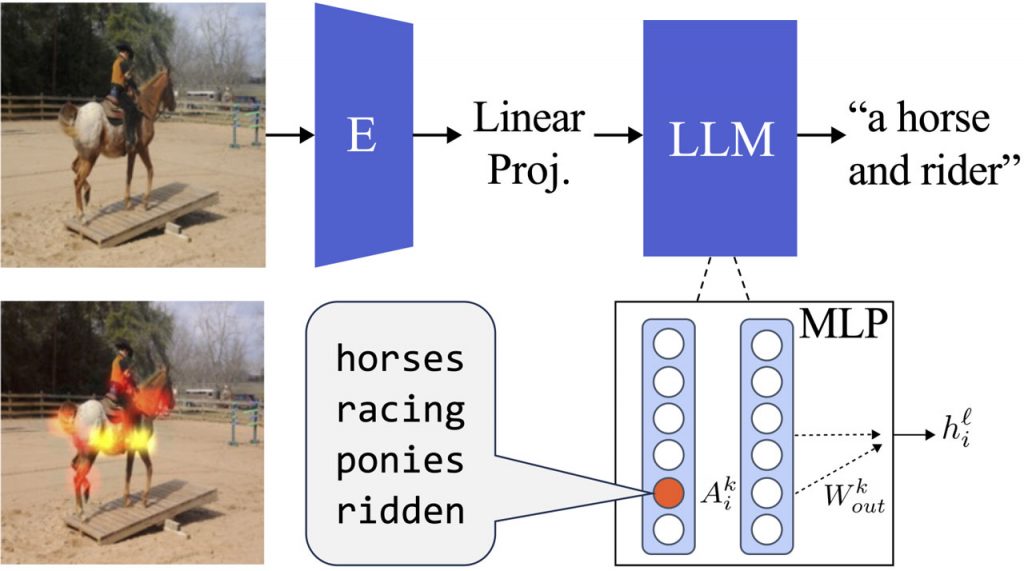
Один із поширених підходів у моделях мови зору передбачає налаштування префіксів на основі зображення. Тут окремий кодер зображення узгоджується з декодером тексту, часто за допомогою шару адаптера, що навчається. Хоча кілька методів використовують цю стратегію, вони, як правило, покладаються на кодувальники зображень, такі як CLIP, що навчаються разом з мовними моделями.
Однак нещодавнє дослідження LiMBeR представило сценарій, що нагадує проблему Моліньє в машинах. Вони з’єднали самокеровану мережу зображень BEIT, яка ніколи не стикалася з лінгвістичними даними, з мовною моделлю GPT-J, використовуючи лінійний проекційний шар, навчений на задачі перетворення зображення в текст. Така установка піднімає фундаментальні питання: Чи переклад семантики між модальностями відбувається в межах проекційного шару, чи узгодження зорових і мовних репрезентацій відбувається всередині самої мовної моделі?

Дослідження, представлене авторами з Массачусетського технологічного інституту, намагається розгадати цю багатовікову таємницю і пролити світло на внутрішню роботу мультимодальних моделей.
Їхні висновки вказують на те, що візуальні підказки, трансформовані у простір вбудовування трансформатора, не кодують семантику, яку можна інтерпретувати. Натомість переклад між модальностями відбувається всередині самого трансформатора.
Крім того, вони виявили мультимодальні нейрони в межах текстових MLP-трансформерів, здатні обробляти як графічну, так і текстову інформацію зі схожою семантикою. Ці нейрони відіграють ключову роль у перекладі візуальних репрезентацій на мову.
Можливо, найбільш важливим є те, що це дослідження показує, що ці мультимодальні нейрони мають причинно-наслідковий вплив на вихідні дані моделі. Модуляція цих нейронів може вибірково вилучати певні поняття з підписів до зображень, підкреслюючи їхню важливість у розумінні мультимодального контенту.
Таке поглиблене дослідження окремих одиниць у глибинних мережах відкриває безліч можливостей для розуміння. Подібно до того, як згорткові одиниці в класифікаторах зображень виявляють кольори і візерунки, а пізніші одиниці розпізнають категорії об’єктів, у трансформаторах з’являються мультимодальні нейрони. Ці нейрони виявляють вибірковість до зображень і тексту зі схожою семантикою.
Більше того, мультимодальні нейрони можуть виникати навіть тоді, коли зір і мова вивчаються незалежно. Вони можуть ефективно перетворювати візуальні образи на зв’язний текст з далекосяжними наслідками, що робить мовні моделі універсальними інструментами для широкого спектру завдань, які потребують послідовного моделювання, від прогнозування ігрових стратегій до конструювання білків.
)
)
)
)
)
)
)
)
