

10.11.2023 16:18
Різні шляхи людського та машинного інтелекту у створенні та розумінні
Остання хвиля генеративного ШІ, від ChatGPT до GPT4, від DALL-E3 до Midjourney, привернула увагу всього світу. Це захоплення супроводжується занепокоєнням щодо потенційних ризиків, пов’язаних з “інтелектом”, який, здається, перевершує людські можливості. Хоча ці моделі штучного інтелекту можуть кинути виклик експертам у мовній та візуальній сферах, вони також демонструють фундаментальні помилки розуміння, що дивують навіть людей, які не є експертами.
Ця парадоксальна на перший погляд ситуація ставить питання про різницю між тим, як функціонує людський інтелект, і тим, як працюють сучасні генеративні моделі. Дослідники з Вашингтонського університету та Інституту штучного інтелекту Аллена запропонували та дослідили гіпотезу “Парадокс генеративного ШІ”. Ця гіпотеза припускає, що такі моделі можуть створювати результати більш творчо, оскільки вони навчені безпосередньо генерувати результати, подібні до експертних, на відміну від людського інтелекту, який зазвичай вимагає фундаментального розуміння, перш ніж досягти результатів на рівні експерта.
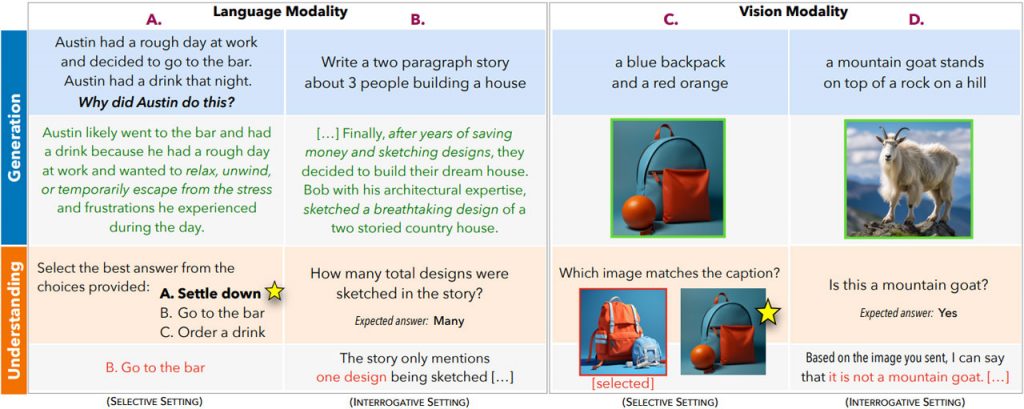
У дослідженні вивчаються можливості генеративних моделей у створенні та розумінні завдань у вербальній та візуальній сферах за допомогою контрольованих досліджень. Дослідники вивчають, наскільки добре ці моделі вибирають належні відповіді в порівнянні з тим, наскільки добре вони розуміють і оцінюють згенеровані ними результати. Для цього використовуються два експериментальні режими: селективне та опитувальне оцінювання.
Отримані результати виявляють інтригуючі закономірності. У вибіркових оцінках моделі часто працюють порівняно або навіть краще за людей у генеративних завданнях, але відстають у дискримінаційних сценаріях. Людські показники дискримінації залишаються більш стійкими до несприятливих вхідних даних і тісніше корелюють з показниками генерації, ніж з моделями. Крім того, зі збільшенням складності завдання розрив між дискримінацією моделі та людини збільшується. В опитувальних оцінках моделі генерують високоякісні результати, але зазнають труднощів, коли їх запитують про ті ж самі покоління, що вказує на можливість покращення їхнього сприйняття порівняно з людським розумінням.
Автори досліджують різні причини цих відмінностей у здібностях генеративних моделей і людей, включаючи навчальну мету, а також характер і кількість вхідних даних. Їхні висновки мають важливе значення. Вони свідчать про те, що можливості ШІ, хоча багато в чому нагадують або перевершують людський інтелект, можуть суттєво відрізнятися від людських процесів мислення. Це застереження щодо висновків про людський інтелект на основі цих моделей штучного інтелекту має вирішальне значення, оскільки їхні результати, хоча й схожі на експертні, можуть не відображати людські механізми. Замість того, щоб порівнювати ці моделі з людським інтелектом, загадка генеративного ШІ спонукає розглядати їх як інтригуючий контраст.
)
)
)
)
)
)
)
)
