

29.02.2024 14:21
Поєднання модальностей в ШІ за допомогою уніфікованої мультимодальної мовної моделі
Штучний інтелект зазнав трансформаційного зсуву в бік охоплення мультимодальності у великих мовних моделях (LLM), що започаткувало новий погляд на те, як машини сприймають і взаємодіють з навколишнім світом. Ця еволюція випливає з визнання того, що людський досвід за своєю суттю є мультимодальним, охоплюючи не лише текст, а й мовлення, зображення та музику. Отже, вдосконалення великих мовних моделей за допомогою здатності обробляти і генерувати різні модальності даних має величезні перспективи для підвищення їхньої корисності і застосовності в реальних сценаріях.
Одне з головних завдань у цій динамічній галузі полягає в розробці моделей, здатних безперешкодно інтегрувати та обробляти різні типи даних. Попри певний прогрес у створенні дуально-модальних моделей, що поєднують текст з іншими формами даних, такими як зображення або аудіо, вирішення більш складних мультимодальних взаємодій, що передбачають одночасне використання декількох типів даних, залишається значною перешкодою.
Щоб вирішити цю проблему, дослідники з Університету Фудань у співпраці з партнерами з Дослідницької спільноти мультимодальних арт-проекцій та Шанхайської лабораторії штучного інтелекту представили AnyGPT. Ця новітня LLM вирізняється тим, що використовує дискретні уявлення для обробки широкого спектру модальностей, включаючи текст, мовлення, зображення та музику. Примітно, що AnyGPT досягає цього без суттєвих змін в архітектурі великої мовної моделі, завдяки попередній обробці на рівні даних, яка спрощує інтеграцію нових модальностей.
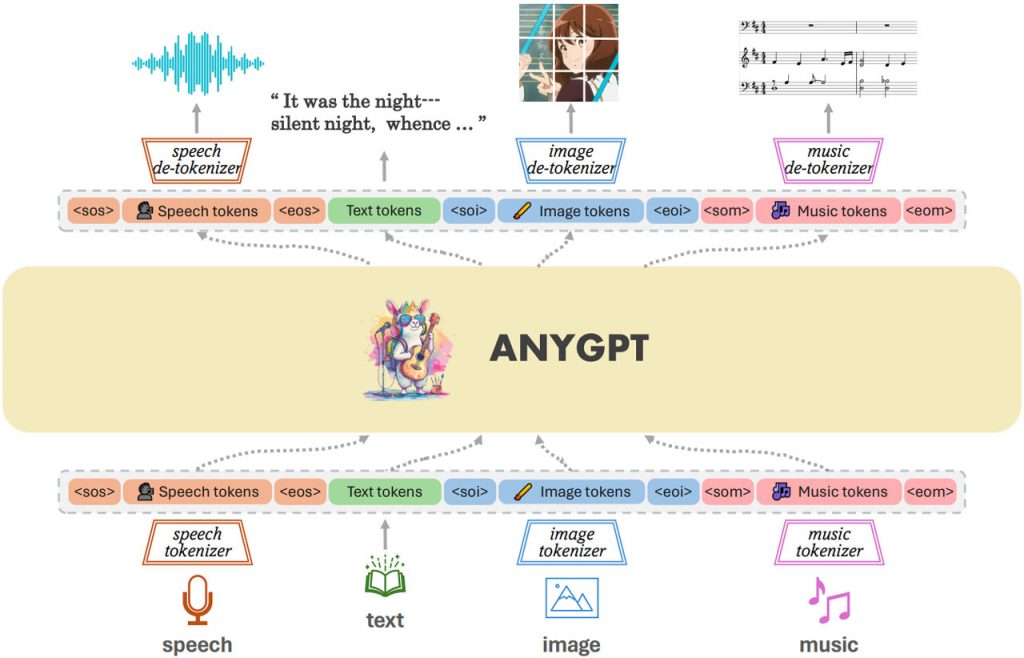
Методологія, що лежить в основі AnyGPT, є одночасно складною і новаторською. Стискаючи необроблені дані з різних модальностей в уніфіковану послідовність дискретних токенів за допомогою мультимодальних токенізаторів, модель уможливлює мультимодальне розуміння та генерування даних. Ця архітектура полегшує авторегресійну обробку токенів, що дозволяє AnyGPT генерувати когерентні відповіді, які безперешкодно охоплюють декілька модальностей.
Продуктивність AnyGPT підкреслює ефективність його дизайну. Модель демонструє можливості на рівні зі спеціалізованими моделями в усіх протестованих модальностях оцінювання. Наприклад, вона чудово справляється із завданнями створення підписів до зображень, отримавши 107,5 балів за шкалою CIDEr, і демонструє майстерність у перетворенні тексту в зображення, отримавши 0,65 балів. Крім того, AnyGPT демонструє ефективні можливості розпізнавання мовлення, про що свідчить його коефіцієнт помилок у словах (WER) 8,5 у наборі даних LibriSpeech.
Наслідки роботи AnyGPT дуже важливі. Уможливлюючи мультимодальну розмову «будь-який з будь-яким», AnyGPT відкриває нові шляхи для розробки систем штучного інтелекту, здатних брати участь у тонких взаємодіях. Його успіх в інтеграції дискретних представлень для різних модальностей в єдину структуру підкреслює потенціал великих мовних моделей, які можуть вийти за рамки традиційних обмежень, пропонуючи зазирнути в майбутнє, де штучний інтелект безперешкодно орієнтується в мультимодальній природі людської комунікації.
Отже, розробка AnyGPT є важливою подією в дослідженнях ШІ. Подолавши відстань між різними модальностями даних, AnyGPT розширює можливості LLM і відкриває можливості для більш складних застосувань ШІ. Оскільки дослідницьке співтовариство продовжує вивчати мультимодальний штучний інтелект, AnyGPT виступає в якості провідника інновацій, демонструючи невикористаний потенціал інтеграції різних типів даних в рамках єдиної моделі.
)
)
)
)
)
)
)
)
