

13.11.2023 14:06
Потужна модель з відкритим вихідним кодом з 10 мільярдами параметрів зору та 7 мільярдами параметрів мови.
Зростання популярності візуальних мовних моделей (VLM) призвело до появи надійних та універсальних систем. Передбачення токенів тепер виходить за рамки зображень і охоплює цілий спектр завдань зорового сприйняття та крос-модальності, від підпису до зображень до візуальних відповідей на запитання. У міру того, як ці моделі розширюються, на перший план виходить їхнє контекстне навчання і розвиток подальшої діяльності. Однак створення VLM з нуля з еквівалентною продуктивністю обробки природної мови, як у досвідчених мовних моделях, таких як LLaMA2, є величезним викликом. Таким чином, використання попередньо підготовленої мовної моделі здається логічною відправною точкою для навчання VLM.
Поширені методи неглибокого вирівнювання, такі як BLIP-2, хоча й ефективні для перенесення характеристик зображення у вхідний простір вбудовування мовної моделі, не можуть конкурувати з моделями одночасного навчання, такими як PaLI-X. Неглибоко вирівняні VLM, такі як MiniGPT-4, LLAVA та VisualGLM, демонструють гірше візуальне сприйняття, що призводить до галюцинацій. Виникає фундаментальне питання: чи можуть VLM покращити візуальне сприйняття без шкоди для здатності до обробки природної мови?
CogVLM відповідає однозначно позитивно. Дослідники з Zhipu AI та Університету Цінхуа представили CogVLM, наголошуючи на відсутності глибокої інтеграції між мовою та візуальною інформацією як основній перешкоді для моделей поверхневого вирівнювання. Їхнє рішення, натхненне p-налаштуванням і LoRA, спрямоване на підтримку більш міцного і послідовного зв’язку між візуальними і мовними елементами в VLM.
Конкретні недоліки, які спостерігаються в методах p-tuning і неглибокого вирівнювання, включають неможливість адаптувати візуальні характеристики в глибоких шарах і кодувати текстові підказки у візуальні характеристики під час попереднього навчання. Інтеграція мовної моделі в комбіноване навчання зображення-текст, як це робиться в Qwen-VL і PaLI, є можливим засобом вирішення цієї проблеми.
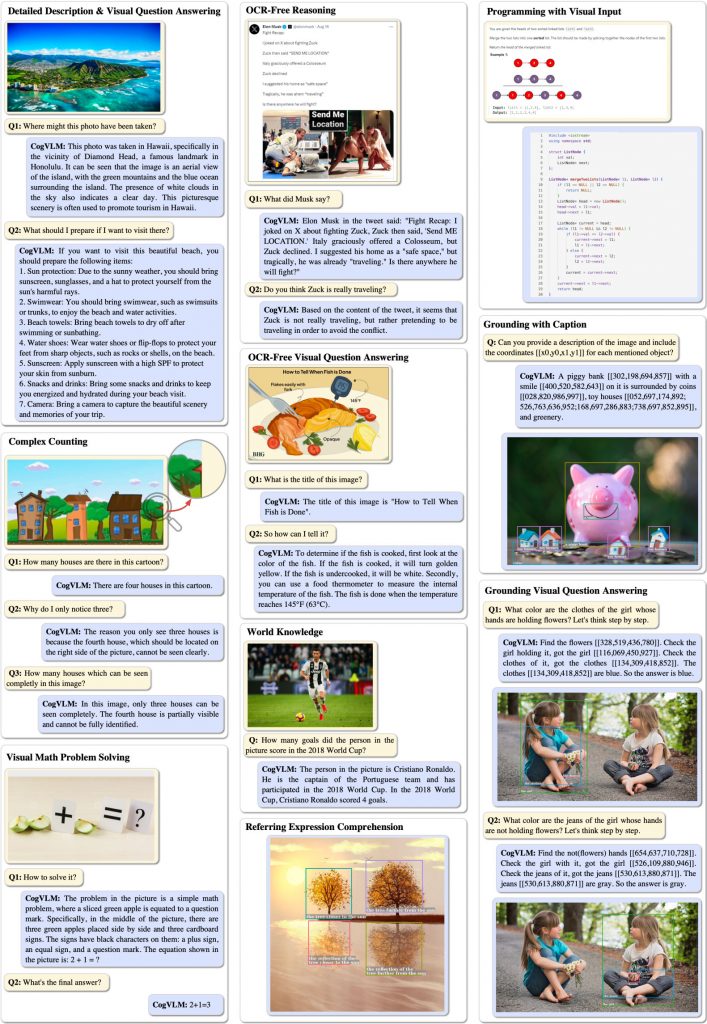
CogVLM вдосконалює мовні моделі, вводячи візуального експерта, що навчається, який використовує окремі матриці QKV і шари MLP для характеристик зображення і тексту. Цей метод не погіршує продуктивність моделі в завданнях, орієнтованих на текст, водночас значно покращуючи візуальне розуміння. Тестування на різних крос-модальних тестах продемонструвало чудову продуктивність CogVLM, яка перевершує або відповідає найсучаснішим результатам у підписі зображень, візуальних відповідях на запитання та наборах даних з множинним вибором.
Крім того, очікується, що відкритий код CogVLM, особливо враховуючи пропрієтарний характер попередніх VLM, суттєво вплине на дослідження візуального розуміння та промислові застосування. Зокрема, CogVLM-28B-zh вирізняється тим, що підтримує китайську та англійську мови, відкриваючи нову еру доступних і потужних VLM для різноманітних застосувань.
)
)
)
)
)
)
)
)
