

22.04.2024 17:50
Пекінський університет та Microsoft співпрацюють над створенням ефективних довгих контекстних вбудовувань
Моделі вбудовування є фундаментальними в обробці природної мови (NLP), полегшуючи такі завдання, як пошук інформації та генерація з розширенням пошуку шляхом перетворення тексту в машинозчитувані числові формати. Однак традиційні моделі обмежені вузькими контекстними вікнами, зазвичай близько 512 токенів, що робить їх практично непридатними для аналізу об’ємних документів, таких як юридичні контракти або наукові огляди.
Останні дослідження в галузі обробки природної мови зосереджені на розширенні можливостей контексту. Ранні моделі, такі як BERT, використовували вбудовування в абсолютну позицію (APE), тоді як новіші інновації, такі як RoFormer і LLaMA, прийняли ротаційне вбудовування в позицію (RoPE) для обробки довших текстів. У таких вартих уваги моделях, як Longformer і BigBird, інтегровані механізми розрідженої уваги для ефективного опрацювання довгих документів, що знаменує собою перехід до обробки значно більших послідовностей у завданнях обробки природної мови.
Спільними зусиллями Пекінського університету та Microsoft було представлено LongEmbed — метод розширення контекстного вікна вбудовування моделей до 32 000 токенів без перенавчання. LongEmbed унікально поєднує інтерполяцію позиції та RoPE для обробки довших текстових послідовностей, зберігаючи при цьому базову продуктивність на коротких вхідних даних. Позиційна інтерполяція розширює вихідне вікно контексту за допомогою лінійної інтерполяції чинних вбудовувань позицій, тоді як RoPE покращує масштабованість для довших послідовностей.
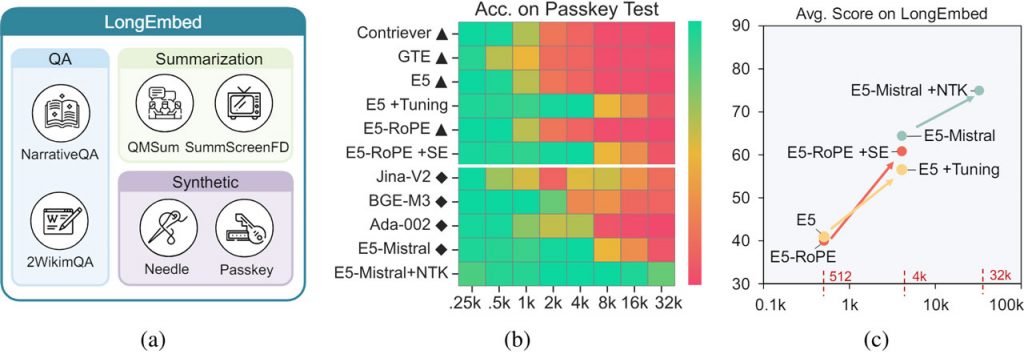
Оцінка на бенчмарку LongEmbed, розробленому для цього дослідження, демонструє значне покращення продуктивності. Моделі з розширеними контекстними вікнами показали підвищення точності на 20% при пошуку документів, що перевищують 4 000 токенів, тоді як моделі з інтеграцією RoPE показали підвищення точності в середньому на 15% для документів будь-якої довжини.
Таким чином, LongEmbed розширює контекстне вікно моделей обробки природної мови без перенавчання, підвищуючи точність пошуку та застосовність до довших текстів. Ефективність цього методу, підтверджена порівняльним тестуванням, підкреслює його потенціал зробити наявні моделі більш універсальними та придатними для різноманітних реальних завдань, що вимагають розширених можливостей обробки текстів.
)
)
)
)
)
)
)
)
