

06.10.2023 13:32
Останні досягнення в галузі мультимодального ШІ
Мультимодальний ШІ, динамічна галузь штучного інтелекту (ШІ), знаходиться на перехресті конвергенції даних, де різні типи даних — текст, зображення, відео, аудіо та інші — об’єднуються для досягнення безпрецедентного рівня продуктивності. На противагу цьому, традиційні моделі ШІ, часто унімодальні за своєю природою, обмежуються обробкою одного типу даних, а їхні алгоритми тонко підлаштовуються під його нюанси. Емблематичний унімодальний ШІ, ChatGPT, вправно розшифровує і виводить значення виключно з текстових даних, а його вихідні дані обмежуються сферою тексту.
Однак ландшафт змінюється. Мультимодальні системи штучного інтелекту, прикладом яких є популярний ChatGPT, що використовує GPT-4, вирушають у подорож, яка виходить за межі цих кордонів. Ці гіганти штучного інтелекту мають дивовижну здатність безперешкодно орієнтуватися в розмаїтті модальностей, організовуючи симфонію результатів. Горизонт можливостей розширюється, коли ці системи виходять за межі тексту, поширюючи свою майстерність на зображення і навіть на лабіринти таких форматів файлів, як PDF і CSV.
У цій статті ми розглянемо останні досягнення у сфері мультимодального штучного інтелекту, де інновації не знають меж, а дані знаходять своє гармонійне поєднання, підносячи штучний інтелект до безпрецедентних висот.
ChatGPT + DALLE 3
DALL-E 3 — це найновіша розробка OpenAI у галузі технології перетворення тексту на зображення, що є значним досягненням у мистецтві, створеному за допомогою штучного інтелекту. Ця ітерація системи покращила її здатність розуміти контекст користувацьких підказок і краще розуміти деталі, надані користувачами.

Як видно на зображенні вище, модель чудово вловлює всі аспекти підказки, створюючи цілісне зображення, яке відповідає тексту, що вводиться.
Захоплюючою розробкою є безшовна інтеграція DALL-E 3 в ChatGPT. Ця інтеграція полегшує співпрацю між двома системами штучного інтелекту. Коли користувачеві пропонується ідея, ChatGPT може без зусиль генерувати точні підказки для DALL-E 3, вдихаючи життя в творчі концепції користувачів. Якщо користувачі бажають внести якісь корективи в зображення, вони можуть легко запросити їх у ChatGPT, сказавши лише кілька слів.
Завдяки можливості звертатися за допомогою до ChatGPT у створенні підказок для DALL-E 3, створення творів мистецтва за допомогою ШІ стає більш доступним для широкої аудиторії. Хоча DALL-E 3 все ще може задовольнити специфічні запити користувачів, співпраця з ChatGPT спрощує процес, роблячи створення творів мистецтва за допомогою ШІ більш зручним для користувача.
Google Bard + розширення
Розмовний інструмент штучного інтелекту від Google, Bard, зазнав значних удосконалень завдяки впровадженню розширень. Ці вдосконалення дозволяють Bard легко інтегруватися з різними додатками та сервісами Google. Завдяки розширенням Bard тепер може отримувати доступ і представляти релевантну інформацію з цілого ряду повсякденних інструментів Google, включаючи Gmail, Документи, Диск, Карти Google, YouTube, Google Flights і готелі.

Можливості Bard ще більше розширюються, коли необхідна інформація охоплює кілька додатків і сервісів. Наприклад, плануючи поїздку до Великого Каньйону, користувачі можуть доручити Bard отримати дати з Gmail, надати актуальну інформацію про рейси та готелі, прокласти маршрут до аеропорту за допомогою Google Maps і навіть поділитися відеороликами з YouTube, що демонструють розваги в пункті призначення — і все це в межах однієї розмови. Така інтеграція підвищує зручність та ефективність використання Bard для різних завдань і запитів.
Claude + завантаження файлів
Розроблений компанією Anthropic, віртуальний чат-бот Claude створений для зручного та безпечного спілкування зі зниженою ймовірністю генерування шкідливих результатів. Claude 2 являє собою вдосконалення цієї технології, завдяки покращеному кодуванню, математичним та логічним можливостям, що дозволяє йому надавати більш розгорнуті та детальні відповіді.

На додаток до цих удосконалень, Claude також має можливість обробляти різні формати документів, включаючи PDF, DOC, CSV та інші. Claude 2 може аналізувати колекцію з п’яти документів, загальною кількістю до 100 000 токенів, для поглибленого аналізу та вилучення інформації. Така розширена функціональність робить Claude 2 універсальним і цінним інструментом для вирішення цілого ряду завдань, пов’язаних з обробкою та аналізом документів.
DeepFloyd IF
DeepFloyd IF, розроблений компанією Stability AI, є потужною моделлю перетворення тексту в зображення в галузі технологій штучного інтелекту. Він працює на основі каскадної моделі дифузії пікселів — унікального підходу до генерації зображень. Робота моделі передбачає каскадний процес, в якому початкова базова модель генерує зразки зображень низької роздільної здатності. Далі послідовність моделей вищого рівня уточнює та покращує ці зображення, щоб отримати вихідні дані з високою роздільною здатністю.
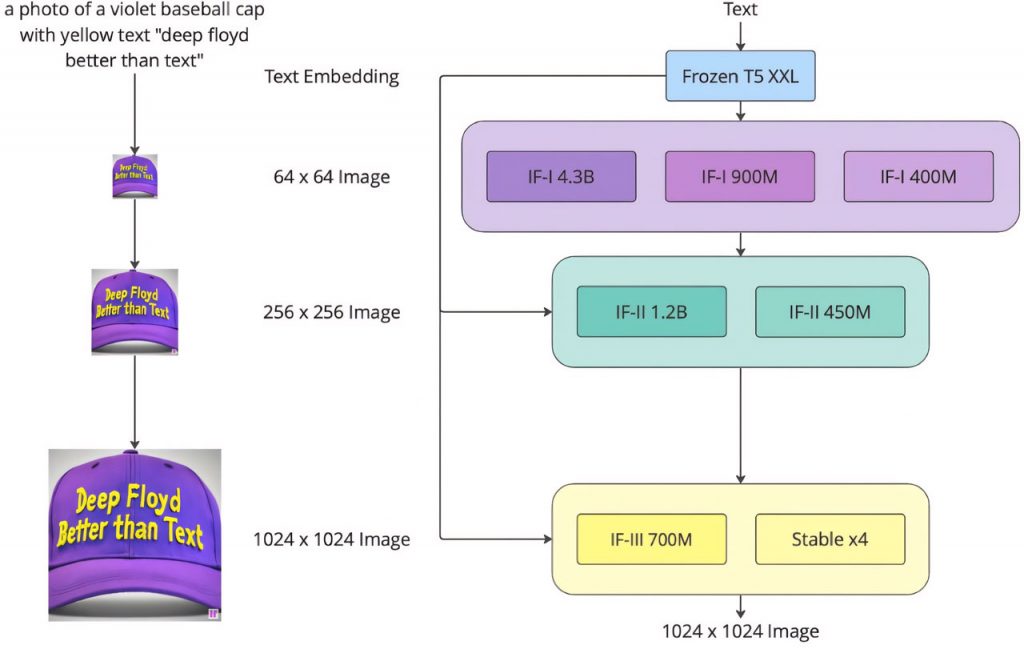
DeepFloyd IF вирізняється своєю надзвичайною ефективністю та вищою продуктивністю порівняно з іншими провідними інструментами в цій галузі. Ця модель підкреслює потенціал використання більших структур UNet для розширення можливостей генерації зображень, натякаючи на захоплююче майбутнє для перетворення тексту в зображення.
Моделі базової та надвисокої роздільної здатності в DeepFloyd IF побудовані на основі дифузійних моделей. Ці моделі включають в себе процес введення випадкового шуму в дані за допомогою кроків ланцюга Маркова, а потім зворотний процес для генерації нових зразків даних з шуму. Цей підхід дозволяє створювати високоякісні зображення з текстових вхідних даних.
ImageBind
ImageBind, новітня модель штучного інтелекту, розроблена компанією Meta AI, являє собою значний стрибок у галузі штучного інтелекту. Ця модель має унікальну здатність безперешкодно інтегрувати та аналізувати дані з шести різних типів, не потребуючи прямих вказівок. Таким чином, вона розширює можливості штучного інтелекту, дозволяючи машинам розпізнавати і розуміти зв’язки між різними формами інформації, включаючи зображення, відео, аудіо, текст, глибину, температуру і IMU (одиниці інерційних вимірювань).

ImageBind може похвалитися кількома вражаючими можливостями, серед яких:
- Негайні звукові підказки: ImageBind може негайно запропонувати аудіоконтент на основі вхідного зображення або відео. Ця функція відкриває можливості для покращення візуального контенту шляхом додавання відповідного звукового супроводу, наприклад, включення заспокійливого звуку хвиль у зображення пляжу.
- Миттєва генерація зображень на основі аудіо: І навпаки, ImageBind може генерувати зображення “на льоту”, якщо на вхід подано аудіокліп. Наприклад, якщо на вхід подати аудіозапис пташиного крику, модель може згенерувати зображення, що показують, як може виглядати цей птах.
- Зв’язування аудіо-зображення: ImageBind дозволяє людям швидко знаходити пов’язані зображення за допомогою підказки, яка пов’язує аудіо та зображення. Ця функціональність виявляється цінною для пошуку зображень, пов’язаних як з візуальними, так і зі слуховими компонентами відеокліпів, створюючи нові можливості для пошуку та дослідження контенту.
Таким чином, здатність ImageBind безперешкодно поєднувати та аналізувати дані з різних модальностей відкриває шлях до інноваційних застосувань у сфері ШІ, що охоплюють покращення аудіовізуального контенту, створення зображень зі звуку та спрощений пошук контенту на основі аудіовізуальних зв’язків. Ця модель є значним кроком у пошуках систем штучного інтелекту, здатних розуміти і маніпулювати різноманітними формами інформації.
CM3leon
CM3Leon — це вдосконалена та універсальна модель, призначена для створення як тексту, так і зображень. Він має чудову здатність безперешкодно перетворювати текст на зображення і навпаки. Однією з його особливостей є виняткова майстерність у перетворенні тексту в зображення, що забезпечує найвищу продуктивність, вимагаючи при цьому лише частину навчальних обчислювальних ресурсів порівняно з аналогічними методами. Така ефективність робить CM3Leon високоефективним і дієвим рішенням для різноманітних завдань генерації тексту і зображень.

Спостерігаючи за постійним розвитком мультимодального ШІ, можна з упевненістю сказати одне: злиття модальностей запалило іскру інновацій, яка обіцяє змінити майбутнє штучного інтелекту. У цьому динамічному ландшафті єдиною константою є прогрес, і ми з нетерпінням чекаємо на майбутні видатні прориви. Подорож мультимодального ШІ триває, прокладаючи курс до незвіданих горизонтів і безмежних можливостей.
)
)
)
)
)
)
)
)
