

20.09.2023 17:27
Об’єднання великих мовних моделей та графів знань
Великі мовні моделі, такі як ChatGPT і GPT-4, стали значним проривом в обробці природної мови і штучному інтелекті завдяки їхнім чудовим можливостям і узагальнюваності. Однак вони мають певні обмеження, зокрема, в захопленні та доступі до фактичних знань. З іншого боку, графи знань, такі як Вікіпедія і Huapu, є структурованими моделями знань, явно призначеними для зберігання багатих фактичних знань. Графи знань мають потенціал доповнювати великі мовні моделі, надаючи зовнішні знання для висновків та інтерпретації. Проте, графи знань є складними для побудови і постійно розвиваються, що створює труднощі у створенні нових фактів і представленні невидимих знань.
Що таке LLM?
Великі мовні моделі (Large Language Models, LLM) – це передові системи штучного інтелекту, призначені для розуміння та генерування людської мови. Ці моделі, що працюють на основі нейронних мереж, які містять мільярди параметрів, проходять тривале навчання на величезних масивах текстів. Це інтенсивне навчання дає їм глибоке розуміння структури та семантики людської мови.
LLM демонструють неабиякі здібності у виконанні широкого спектру завдань, пов’язаних з іноземними мовами. Вони досягають успіху в таких завданнях, як переклад, аналіз настроїв та участь у розмовних обмінах, серед іншого. Ці моделі здатні розуміти складну текстову інформацію, ідентифікувати об’єкти та їхні зв’язки, а також генерувати текст, який зберігає логічну зв’язність і відповідає граматичним правилам.
Що таке графи знань?
Граф знань – це структурована база даних, яка слугує для представлення даних та інформації про різні об’єкти. Вона складається з вузлів, які представляють об’єкти, людей або місця, і граней, які визначають зв’язки або відносини між цими вузлами. Така структура дозволяє машинам розуміти взаємозв’язки, спільні характеристики та асоціації між різними об’єктами у спосіб, що відображає зв’язки реального світу.
Графи знань знаходять застосування в широкому діапазоні сфер, включаючи рекомендацію відео на таких платформах, як YouTube, виявлення страхового шахрайства, надання рекомендацій щодо продуктів у роздрібній торгівлі та полегшення прогнозного моделювання завдяки використанню взаємопов’язаної природи інформації. Ці графіки є цінними інструментами для організації та вилучення інформації зі складних наборів даних.
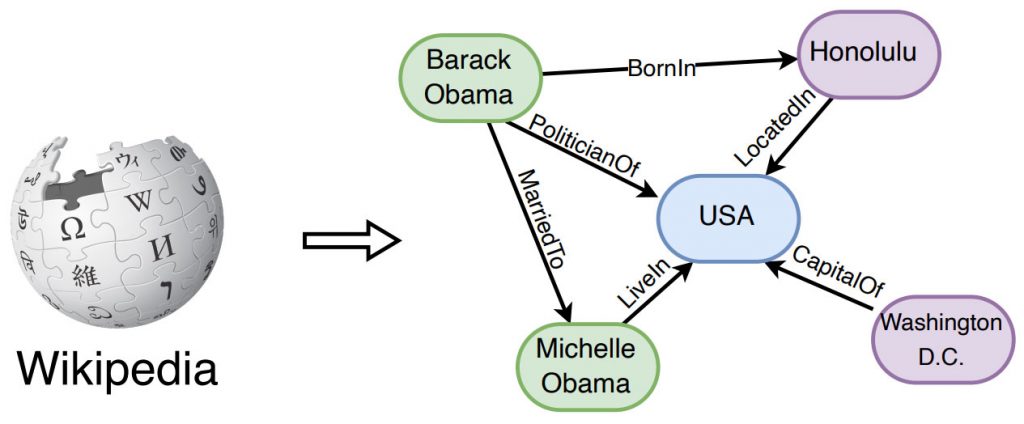
Великі мовні моделі в синтезі з графами знань
Дійсно, поєднання великих мовних моделей (LLM) і графів знань (KG) може усунути деякі обмеження великих мовних моделей, використовуючи при цьому структуровані знання в рамках графів знань. Існує три основні підходи до інтеграції LLMs і KGs:
- Великі мовні моделі, розширені за допомогою KG: У цьому підході графіки знань включаються в LLM як на етапі підготовки, так і на етапі виведення. Це дозволяє магістрам мати доступ до зовнішніх знань при формуванні відповідей або виконанні завдань. Знання, отримані від KG, можуть допомогти LLM надавати більш точну та фактичну інформацію у своїх роботах.
- Графи знань, доповнені LLM: Тут великі мовні моделі використовуються для покращення завдань, пов’язаних з KG. LLM можуть допомогти у виконанні таких завдань, як вбудовування, заповнення, побудова графів знань, перетворення графів у текст і відповіді на запитання. Вони можуть покращити зручність використання КГ, роблячи їх більш інтерактивними та доступними для користувачів.
- Синергія LLM + KG: У цьому підході LLM і KG працюють у тандемі, отримуючи вигоду від сильних сторін один одного. Вони обидва відіграють ключові ролі і співпрацюють для покращення аргументації та розуміння. Ця синергія дозволяє двостороннє міркування, що ґрунтується як на даних, так і на знаннях, пропонуючи більш комплексні та точні результати.
Ці три підходи є багатообіцяючим шляхом до вдосконалення можливостей систем штучного інтелекту, використовуючи як можливості розуміння мови LLM, так і структуровані знання, що зберігаються в KG.
Графи знань, доповнені великими мовними моделями
Безумовно, поєднання великих мовних моделей (Large Language Models, LLM) з графами знань (Knowledge Graphs, KG) є багатообіцяючим підходом для пом’якшення деяких обмежень LLM. Графи знань надають структуровану фактичну інформацію, яка може покращити LLM різними способами, як ви зазначили:
- Поглиблення знань: Включення KG під час попередньої підготовки LLM може допомогти моделі отримати фактичні знання. Це підвищує точність згенерованого контенту і знижує ймовірність галюцинацій, коли LLM генерують невірну інформацію.
- Знання, специфічні для галузі: Під час виведення KG можуть бути використані для надання LLМ знань, специфічних для конкретної галузі. Це особливо корисно для завдань, які вимагають спеціалізованої інформації, таких як медичний діагноз або аналіз юридичних документів.
- Можливість інтерпретації: KG також можуть допомогти зробити великі мовні моделі більш інтерпретованими. Використовуючи KG для відстеження джерел інформації, стає легше зрозуміти, як LLM дійшли певного висновку. Така прозорість має вирішальне значення для тих сфер, де підзвітність і довіра мають першорядне значення.
Загалом, синергія між великими мовними моделями та графами знань має великий потенціал для підвищення точності, релевантності предметної області та прозорості мовних завдань, керованих штучним інтелектом.
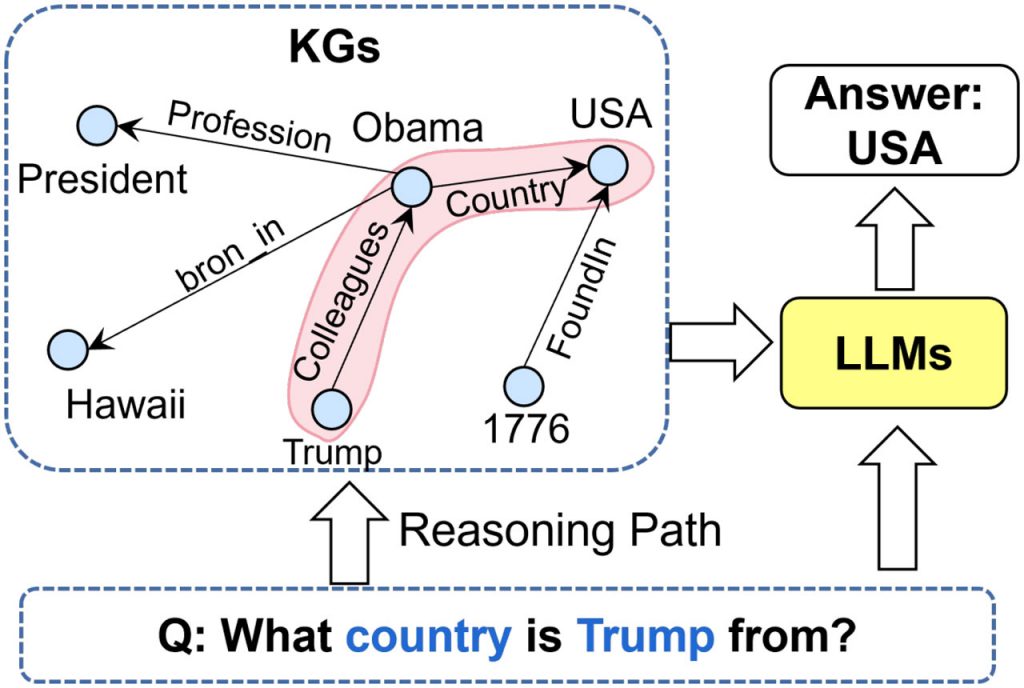
Великі мовні моделі, розширені графами знань
Дійсно, використання великих мовних моделей для графів знань відкриває захоплюючі можливості для вирішення проблем, пов’язаних з побудовою та використанням KG. Ось деякі з основних способів застосування LLM для задач, пов’язаних з графами знань:
- Обробка тексту для KG: LLM можуть аналізувати неструктуровані текстові дані в межах KG, що полегшує вилучення цінної інформації та взаємозв’язків. Це може допомогти поліпшити якість і повноту KG.
- Побудова KG з тексту: Дослідники вивчають, як LLM можуть автоматично обробляти великі обсяги текстових даних для вилучення сутностей, зв’язків і фактів, які потім можна використовувати для побудови KG. Це особливо корисно для побудови KG з таких джерел, як веб або текстові корпуси.
- Покращення представлення KG: LLM можуть збагачувати представлення KG, вбудовуючи текстові описи, контекст або навіть згадки про сутності у вузли KG. Це покращує загальне розуміння KG.
- Підказки до KG: Створення підказок, зрозумілих для великих мовних моделей, дозволяє безпосередньо застосовувати їх до завдань, пов’язаних з KG, таких як завершення та міркування в KG. Ці підказки слугують мостом між неструктурованим текстом і структурованими KG.
Співпраця між LLM і KG має потенціал для покращення як побудови, так і використання графів знань, роблячи їх більш точними, всеосяжними і доступними для різних реальних застосувань.
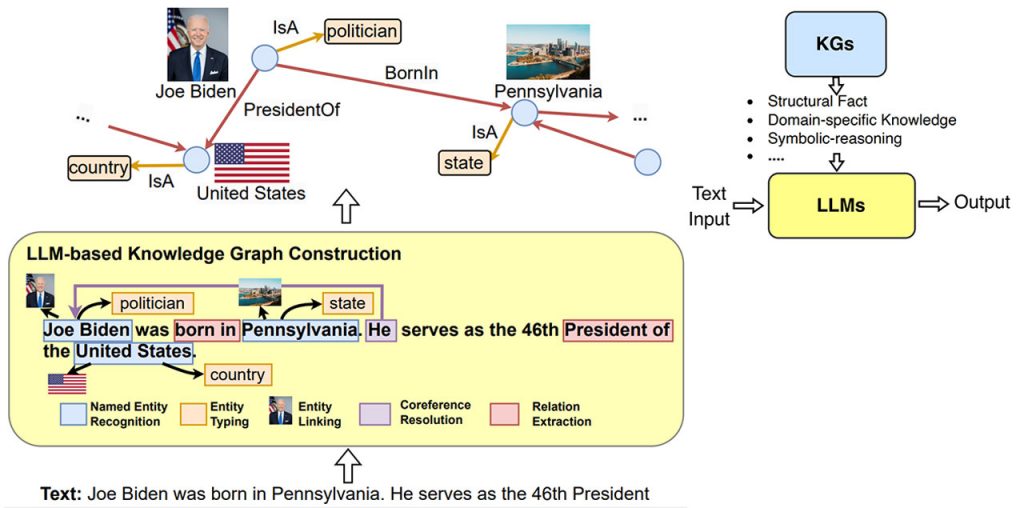
Синергетичні LLM + KG
Інтеграція великих мовних моделей (LLM) і графів знань (KG) за допомогою фреймворку “Синергетичні LLM + KG” має великі перспективи в різних сферах застосування. Ця уніфікована структура складається з чотирьох взаємопов’язаних шарів, кожен з яких відіграє важливу роль:
- Рівень даних: Цей рівень передбачає обробку даних. LLM особливо вправні в обробці та розумінні текстових даних, тоді як KG досягають успіху в управлінні структурованими даними. Крім того, фреймворк може бути розширений, щоб охопити мультимодальні LLM і KG, що дозволить йому працювати з різними типами даних, включаючи текст, зображення, відео та аудіо.
- Синергетичний рівень моделей: Тут LLM і KG працюють разом для створення синергетичних моделей. Магістри можуть покращити роботу KG, надаючи текстовий контекст і розуміння, тоді як KG можуть збагатити LLM, пропонуючи структуровані знання. Таке спільне моделювання зміцнює обидва компоненти і покращує їхню продуктивність.
- Технічний рівень: Для полегшення взаємодії між LLM і KG використовуються різні методи. Ці методи включають методи включення знань, міркувань та узгодження, що гарантують, що LLM та KG ефективно доповнюють один одного.
- Прикладний рівень: Кінцевою метою цієї структури є вдосконалення різних додатків. Завдяки синергії LLM і KG такі додатки, як пошукові системи, рекомендаційні системи, асистенти зі штучним інтелектом тощо, можуть отримати вигоду від покращеного розуміння даних, інтеграції знань і можливостей міркування.
Фреймворк “Синергія LLM + KG” представляє цілісний підхід до використання взаємодоповнюючих сильних сторін LLM і KG, тим самим розкриваючи їхній повний потенціал у широкому діапазоні реальних застосувань.
Відповіді на запитання з декількома переходами
Зазвичай, використовуючи LLM для вилучення інформації з документів, ми розбиваємо їх на сегменти, а потім перетворюємо ці сегменти на векторні вбудовування. Однак такий підхід може виявитися недостатнім для виявлення інформації, яка поширюється на кілька документів, що є проблемою, відомою як відповідь на питання в декілька етапів.
Для вирішення цієї проблеми на допомогу приходять графи знань. Ми можемо створити структуроване представлення інформації, опрацьовуючи кожен документ окремо, а потім пов’язуючи їх в рамках графа знань. Це полегшує навігацію і дослідження взаємопов’язаних документів, дозволяючи нам відповідати на складні питання, які передбачають кілька послідовних кроків.
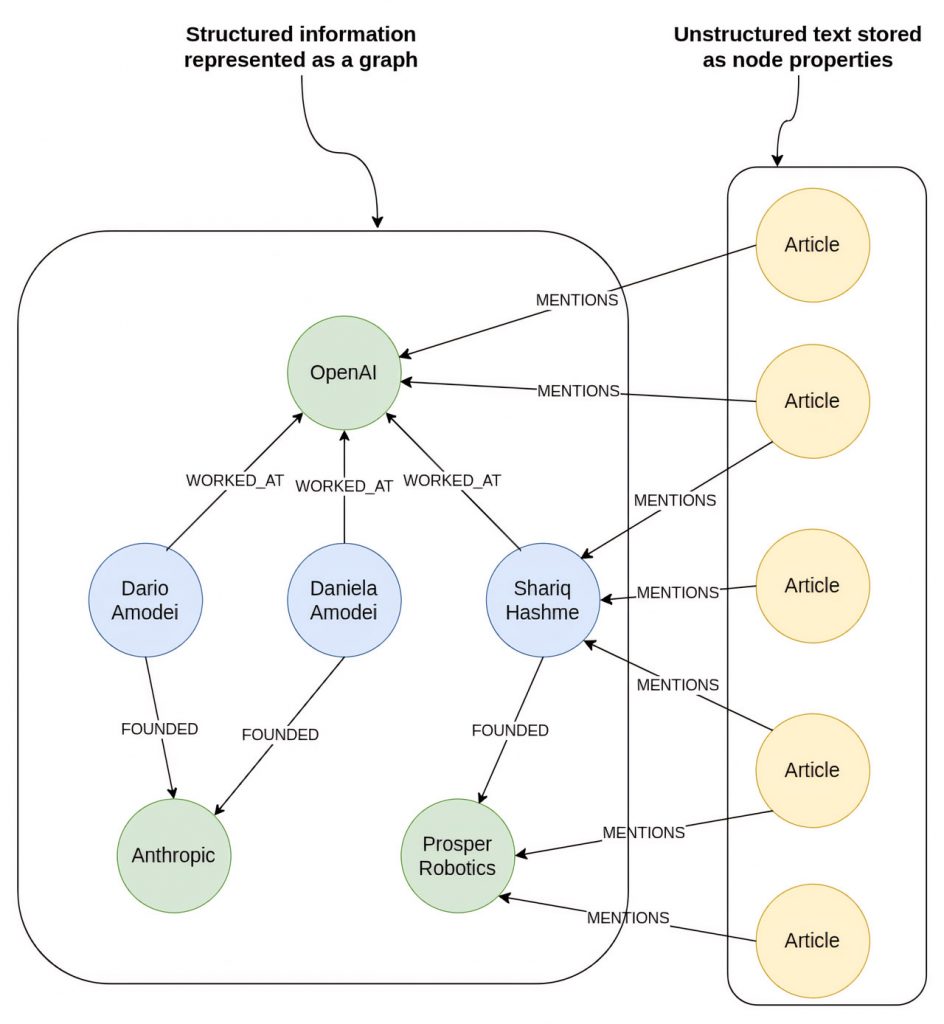
Наприклад, якщо ми хочемо, щоб LLM відповів на питання “Чи заснували колишні співробітники OpenAI власні компанії?”, LLM може або повернути дублюючу інформацію, або пропустити важливі деталі. Виокремлюючи сутності та зв’язки з тексту для побудови графа знань, ми даємо можливість LLM кваліфіковано відповідати на питання, які охоплюють кілька документів.
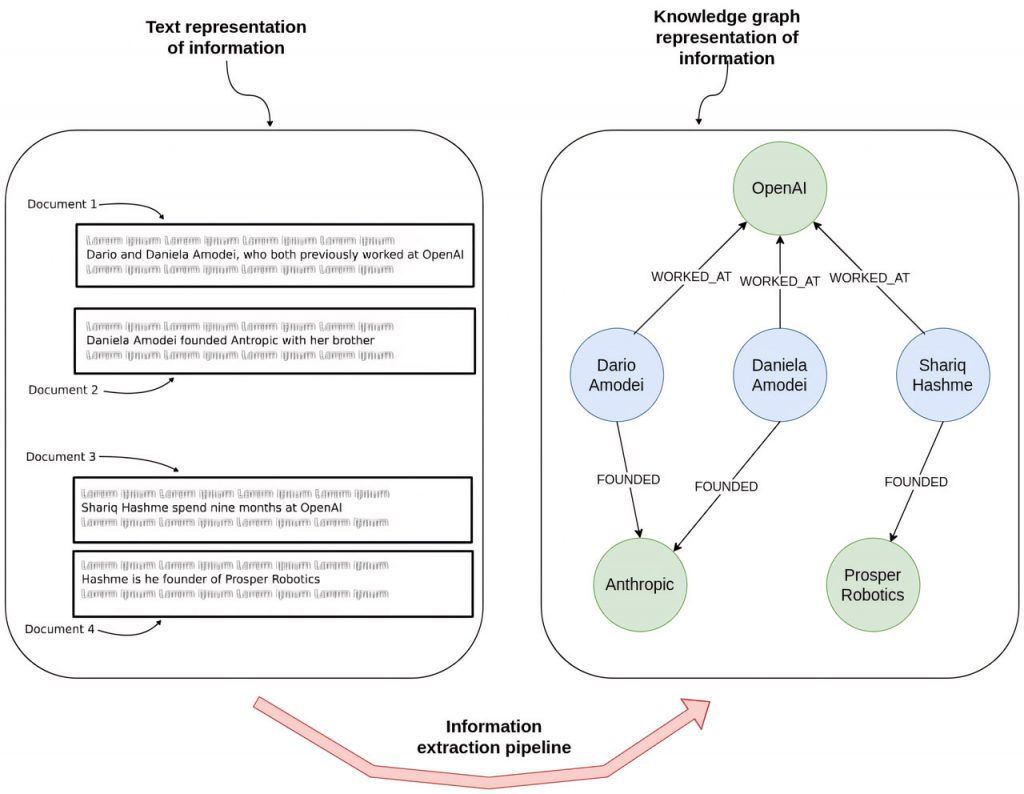
Поєднання текстових даних з графом знань
Використання графа знань разом з LLM має ще одну важливу перевагу: можливість охопити як структуровані, так і неструктуровані дані, встановлюючи між ними значущі зв’язки. Така інтеграція значно спрощує процес пошуку інформації.
У наведеному прикладі граф знань слугує сховищем для:
Структурованих даних: Інформація про колишніх співробітників OpenAI та компаній, які вони заснували.
Неструктурованих даних: Новин, в яких згадується OpenAI та його співробітники.
Завдяки такій конфігурації ми можемо без зусиль відповідати на такі запити, як “Які останні події стосуються засновників Prosper Robotics?”, починаючи з вузла, що представляє Prosper Robotics, переходячи до її засновників, а потім отримуючи останні статті, що стосуються їх.
Така універсальність робить комбінацію графів знань і великих мовних моделей придатною для різноманітних застосувань, оскільки вона вміло управляє різними форматами даних і складними зв’язками між об’єктами. Крім того, візуальна структура графа забезпечує наочне представлення знань, покращуючи розуміння і зручність використання як для розробників, так і для користувачів.
Висновок
Дослідники все більше заглиблюються у спільний потенціал поєднання великих мовних моделей (LLM) та графів знань (KG), використовуючи три основні підходи: Великі мовні моделі, розширені за допомогою графів знань, великі мовні моделі, доповнені графами знань, та синергетичні великі мовні моделі + графи знань. Ці підходи розроблені для того, щоб використовувати сильні сторони LLM та KG для вирішення широкого спектру мовних та знаннєво-орієнтованих завдань.
Інтеграція LLM і KG відкриває цілу низку багатообіцяючих можливостей, що поширюються на такі додатки, як відповіді на запитання в кілька етапів, злиття текстових і структурованих даних, а також підвищення прозорості та інтерпретованості систем штучного інтелекту. Оскільки технології продовжують розвиватися, це синергетичне партнерство між LLM та KG має потенціал для стимулювання інновацій у таких сферах, як пошукові системи, системи рекомендацій та асистенти ШІ, що в кінцевому підсумку принесе користь як кінцевим користувачам, так і розробникам.
)
)
)
)
)
)
)
)
