

07.05.2024 14:41
Nvidia DrEureka перевершує людей у навчанні робототехнічних систем
Досягнення в галузі генеративного ШІ та великих мовних моделей (LLM) призводять до революційних змін у сфері робототехніки, про що свідчить нещодавнє дослідження, проведене Nvidia, Університетом Пенсильванії та Техаським університетом в Остіні. Це дослідження демонструє новітню технологію DrEureka, призначену для оптимізації навчання робототехнічних систем з використанням методів, що базуються на штучному інтелекті.
DrEureka, скорочення від Domain Randomization Eureka, пропонує свіжий підхід, який полягає в автоматичному генеруванні функцій винагороди та розподілів рандомізації для робототехнічних систем. На відміну від традиційних методів, які покладаються на розроблені людиною винагороди, DrEureka використовує високорівневі описи завдань для швидкого та ефективного створення нових компонентів. Ця інновація має величезний потенціал для подолання розриву між симульованими середовищами та реальними застосуваннями, роблячи перенесення вивчених політик з симуляції в реальність більш плавним і ефективним.
Ключовий виклик у робототехніці полягає в перенесенні «з симуляції в реальність», коли політики, відпрацьовані в симуляційних середовищах, повинні адаптуватися до реальних умов. Цей перехід часто вимагає значних коригувань функцій винагороди та параметрів симуляції вручну. DrEureka вирішує цю проблему шляхом автоматизації цих трудомістких процесів за допомогою великих мовних моделей.
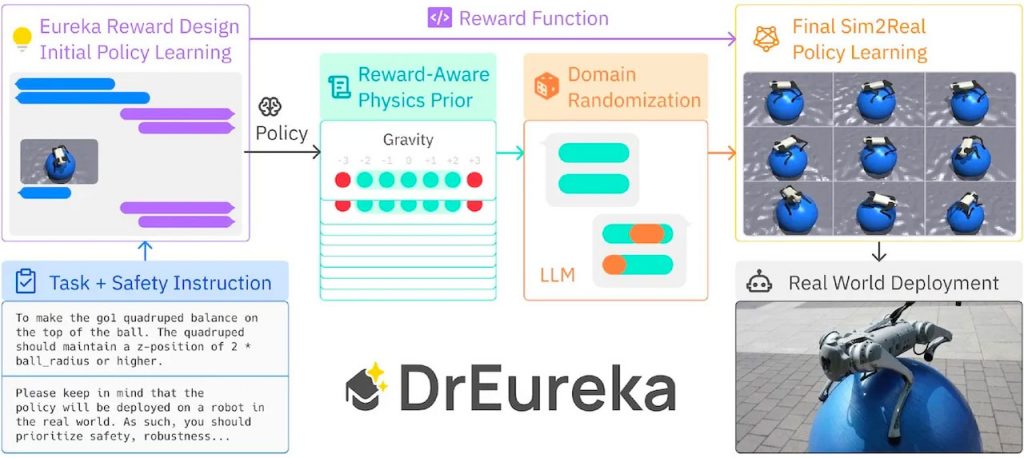
В основі DrEureka лежить технологія Eureka, представлена в жовтні 2023 року. Eureka використовує LLM для генерації реалізацій функцій винагороди на основі описів завдань, які потім виконуються в симуляційних середовищах. DrEureka робить ще один крок вперед, автоматично налаштовуючи параметри доменної рандомізації, що має вирішальне значення для забезпечення узагальнення робототехнічних правил до збурень реального світу.
Методи доменної рандомізації розподіляють фізичні параметри в симуляційних середовищах, дозволяючи адаптувати правила до непередбачуваних варіацій в реальному світі. Однак вибір відповідних параметрів доменної рандомізації вимагає складних міркувань і знань про цільового робота і навколишнє середовище. Саме тут виявляються корисними великі мовні моделі, які використовують своє глибоке розуміння фізичних концепцій і можливості генерування гіпотез.
DrEureka використовує багатоетапний процес для одночасної оптимізації функцій винагороди та параметрів рандомізації області. Спочатку LLM генерує функції винагороди на основі описів завдань і правил безпеки. Потім ці функції використовуються для вивчення правил, подібно до підходу Eureka. Згодом проводяться тести для визначення відповідних конфігурацій рандомізації домену, таких як тертя і гравітація, на основі продуктивності вивченої системи. Нарешті, стратегія перенавчається з використанням цих оптимізованих конфігурацій доменної рандомізації для підвищення надійності в реальних сценаріях.
Дослідження оцінювало DrEureka в задачах чотириногого пересування та вправних маніпуляцій, продемонструвавши значне покращення продуктивності порівняно з традиційними методами. Наприклад, при пересуванні на чотирьох кінцівках, роботи, навчені за допомогою DrEureka, продемонстрували збільшення швидкості руху на 34% і покращення відстані, яку вони долали на реальній місцевості, на 20%. Аналогічно, у завданнях на спритне маніпулювання DrEureka зі значним відривом перевершила стратегії, розроблені людиною.
)
)
)
)
)
)
)
)
