

31.10.2023 18:01
Новітнє покоління мультимодальних мовних моделей для розширеного розуміння та опису зображень
Включення просторових знань у моделі є значним викликом у навчанні мови технічного зору, що включає дві основні можливості: референціювання та заземлення. У той час як обґрунтування передбачає локалізацію просторових об’єктів на основі наданих семантичних описів, прив’язка вимагає всебічного розуміння семантики зазначених просторових об’єктів. Суть як референції, так і прив’язки полягає в узгодженні географічної інформації з семантикою, проте традиційні підходи часто викладають ці поняття окремо. На відміну від машин, люди легко інтегрують посилання та прив’язку у повсякденні дискусії та міркування, легко переносячи знання з одного контексту в інший.
Це дослідження спрямоване на усунення існуючої невідповідності шляхом вивчення трьох ключових питань. По-перше, досліджується, як можна об’єднати посилання та обґрунтування в єдину систему і як вони можуть доповнювати одне одного. По-друге, він заглиблюється у проблему відображення різноманітних специфічних форм, включно з точками, квадратами, каракулями та формами довільної форми, які люди часто використовують для позначення об’єктів. Нарешті, дослідження прагне зробити посилання та обґрунтування відкритим словником, зрозумілим для виконання інструкцій та придатним для практичного застосування.
Щоб вирішити ці проблеми, дослідники з Колумбійського університету та Apple AI/ML представили Ferret — нову мультимодальну велику мовну модель (Multimodal Large Language Model, MLLM) з функцією посилання та обґрунтування. Ferret побудована на платформі MLLM, обраній завдяки її потужним можливостям глобального розуміння мови зору. Спочатку Ferret кодує просторові координати, використовуючи числові форми простої мови, щоб уніфікувати прив’язку та обґрунтування.
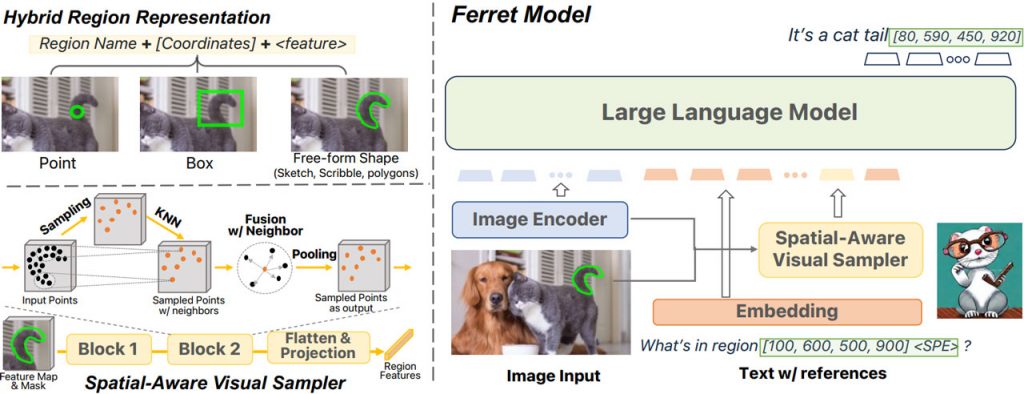
Однак непрактично представляти різноманітні особливості форми (такі як штрихи, каракулі або складні багатокутники) за допомогою одного набору координат. Ці різноманітні форми необхідні для точної взаємодії людини з моделлю.Щоб вирішити цю проблему, дослідники пропонують просторово-орієнтований візуальний семплер, який фіксує оптичні особливості областей будь-якої форми, враховуючи змінну щільність цих форм. У Ferret візуальні області на вході представлені за допомогою гібридного представлення областей, що складається з дискретних координат і безперервних візуальних ознак. За допомогою цих методів Ferret може обробляти вхідні дані, що поєднують текст у довільній формі та області з посиланнями, прив’язуючи вказані об’єкти шляхом автоматичного генерування координат для кожного об’єкта та текстового опису.
Наскільки відомо дослідникам, Ferret є першою програмою, здатною обробляти вхідні дані з MLLM, що містять області довільної форми. Для розвитку відкритого словника Ferret, його здатності слідувати інструкціям і надійної системи орієнтації, дослідники створили базу даних Ground-and-Refer Instruction-Tuning Data Set (GRIT), що складається з 1,1 мільйона зразків. GRIT охоплює різні рівні просторових знань, включаючи описи областей, зв’язків, об’єктів і складні міркування. Він містить дані з комбінованим розташуванням і текстовими елементами як на вході, так і на виході, що охоплює як сценарії посилання, так і обґрунтування.
Крім того, дослідники зібрали 34 000 діалогів для налаштування інструкцій з орієнтування за допомогою ChatGPT/GPT-4, щоб навчити Ferret працювати з відкритим словником і орієнтуватися на місцевості. Вони також виконують просторовий аналіз негативних даних, щоб підвищити надійність моделі. Ferret демонструє чудові можливості просторової обізнаності та локалізації в контексті відкритого словника, перевершуючи традиційні завдання з пошуку посилань та обґрунтування. Крім того, дослідники представляють Ferret-Bench, який представляє три нові типи завдань: “Посилання на опис”, “Посилання на міркування” та “Обґрунтування в розмові”. За оцінками, Ferret перевершує існуючі MLLM в середньому на 20,4% і помітно зменшує об’єктні галюцинації.
Дослідження пропонує три ключові висновки:
- Впровадження Ferret, що полегшує посилання на деталізований і відкритий словниковий запас і обґрунтування в MLLM, використовуючи гібридне уявлення областей і унікальний візуальний семплер з урахуванням просторових особливостей;
- Створення GRIT, всеосяжного набору даних для налаштування інструкцій для навчання моделі, включаючи додаткові просторові негативні приклади для покращення стійкості моделі до зовнішніх впливів;
- Впровадження Ferret-Bench, системи оцінювання в завданнях, що вимагають посилань, обґрунтування, семантики, знань і міркувань, де Ferret демонструє вищу продуктивність і меншу об’єктну галюцинацію порівняно з іншими моделями.
)
)
)
)
)
)
)
)
