

22.11.2023 17:38
Новітній фреймворк для антропоморфних персонажів у великих мовних моделях
Дослідницька група з Університету Нанкай і компанії ByteDance представила ChatAnything — новий фреймворк для створення антропоморфних персонажів на базі великих мовних моделей (LLM) в онлайн-середовищі. Цей прогресивний підхід спрямований на створення персонажів з унікальним зовнішнім виглядом, характером та інтонаціями, спираючись виключно на текстові описи. Використовуючи можливості навчання в контексті LLM, дослідники представили дві нові концепції: суміш голосів (MoV) і суміш дифузорів (MoD), щоб полегшити створення різноманітних голосів і зовнішнього вигляду.
MoV використовує алгоритми перетворення тексту в мову (TTS) із заздалегідь визначеними тонами, вибираючи найбільш підходящий з них на основі наданих користувачем текстових описів. З іншого боку, MoD поєднує методи перетворення тексту в зображення та алгоритми створення “балакучих голів”, щоб спростити процес генерації об’єктів, що розмовляють. Однак дослідники виявили проблему, коли антропоморфні об’єкти, згенеровані за допомогою існуючих моделей, часто уникають детекції попередньо навченими системами розпізнавання облич, що призводить до збоїв у генерації рухів обличчя. Щоб вирішити цю проблему, вони запровадили керування на рівні пікселів під час генерації зображень, щоб включити в них орієнтири людських облич. Ця ін’єкція на рівні пікселів значно покращує показники виявлення орієнтирів обличчя, що уможливлює автоматичну анімацію обличчя на основі згенерованого мовного контенту.
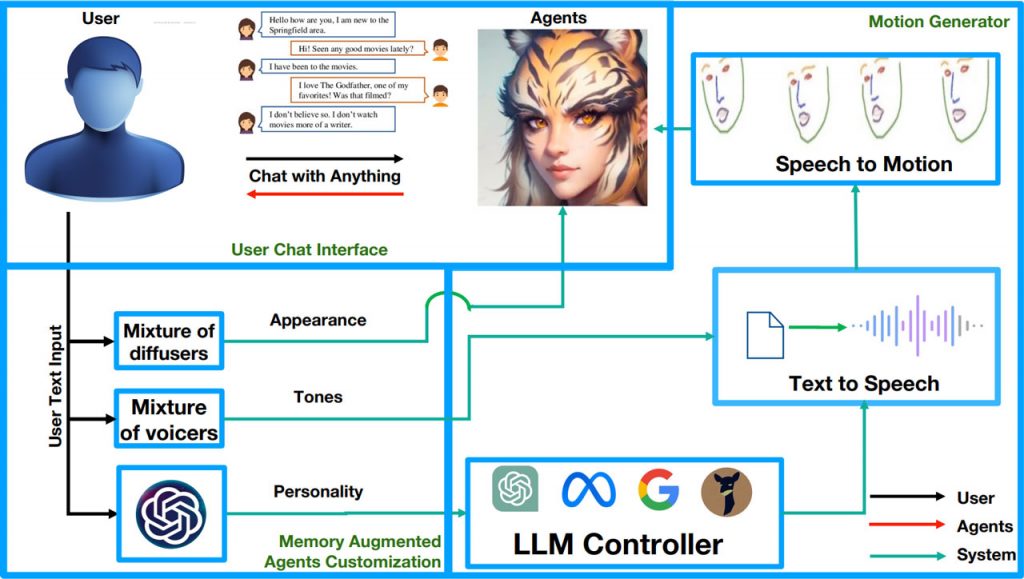
У публікації розглядаються останні досягнення в галузі великих мовних моделей та їхні можливості навчання в контексті, що робить їх центральною темою академічних дискусій. Дослідники наголошують на необхідності створення фреймворку, що генерує персонажів на основі LLM з індивідуальними характерами, голосами та зовнішнім виглядом. Для створення персонажів вони використовують можливості навчання в контексті LLM, формуючи пул голосових модулів за допомогою інтерфейсів перетворення тексту в мову. Потім модуль MoV вибирає тони на основі введеного користувачем тексту.
Для візуалізації рухів і виразів, керованих мовленням, використовуються новітні алгоритми “балакучої голови”. Однак при використанні зображень, згенерованих дифузійними моделями, як вхідних даних для моделей балакучих голів виникають проблеми: лише 30% зображень можуть бути розпізнані найсучаснішими моделями балакучих голів, що вказує на неспівпадіння розподілів. Щоб подолати цю проблему, дослідники пропонують метод нульового пострілу, який полягає у введенні орієнтирів обличчя на етапі генерації зображення.
Фреймворк ChatAnything складається з чотирьох основних блоків: модуль управління на основі LLM, портретний ініціалізатор, суміш модулів перетворення тексту в мовлення та модуль генерації рухів. Інтегруючи моделі дифузії, засоби зміни голосу та структурний контроль, дослідники створили модульну та гнучку систему. Для перевірки ефективності керованої дифузії створено валідаційний набір даних із підказками з різних категорій. Попередньо навчений детектор ключових точок обличчя використовується для оцінки швидкості виявлення орієнтирів обличчя, демонструючи вплив запропонованого ними методу.
Цей комплексний фреймворк, ChatAnything, представляє нову парадигму генерації персонажів з антропоморфними рисами на основі LLM. Вирішуючи проблеми виявлення орієнтирів обличчя та пропонуючи інноваційні рішення, дослідники представили багатообіцяючі результати у своєму валідаційному наборі даних, прокладаючи шлях для майбутніх досліджень у галузі інтеграції генеративних моделей з алгоритмами розмовних голів та покращення вирівнювання розподілу даних.
)
)
)
)
)
)
)
)
