

19.10.2023 13:21
Мультимодальний фреймворк ШІ для автоматичної розробки та дизайну зображень
Сфера “дизайну та генерації зображень” обертається навколо складного завдання створення зображень на основі наданих користувачем високорівневих концепцій. Ці концепції, відомі як IDEA, можуть мати форму еталонних зображень або детальних інструкцій. Процес, як правило, передбачає втручання людини, оскільки користувачі використовують моделі перетворення тексту в зображення (T2I), щоб перевести свої уявні концепції у візуальні образи. Таке ручне дослідження може потребувати кількох ітерацій, доки не буде досягнуто ідеального перекладу.
В епоху, позначену вражаючими можливостями великих мультимодальних моделей (LMM), дослідницька спільнота поставила перед собою цікаве питання: Чи можемо ми навчити LMM самостійно набувати здатності до ітеративного самоудосконалення і звільнити людину від важкого завдання перетворення абстрактних ідей у візуальні образи? Люди, керуючись вродженою схильністю до постійного вдосконалення, коли стикаються з невідомими або складними завданнями, розвинули здатність удосконалювати свої методи з плином часу. Таке самовдосконалення особливо помітне в задачах обробки природної мови, від генерації абревіатур до аналізу настроїв і дослідження текстового середовища, де агенти з великими мовними моделями (LLM) постійно демонструють покращену продуктивність. Однак перехід до мультимодальних налаштувань, що характеризуються конвергенцією текстових і графічних даних, породжує нові виклики, включаючи покращення, оцінювання та перевірку послідовностей зображень і текстів, що чергуються між собою.
Дослідники з Microsoft Azure заглиблюються в цю інтригуючу грань ітеративного самовдосконалення, зосереджуючись на області “дизайну і генерації зображень”. Вони представляють Idea2Img, мультимодальний фреймворк, що дозволяє автономно створювати та оформлювати зображення. Ця новаторська система поєднує в собі LMM, GPT-4V (зір), з T2I моделлю для дослідження та виявлення корисних T2I підказок. Синергія між цими моделями дозволяє як інтерпретувати відповіді T2I-моделі (ескізні зображення), так і формулювати подальші запити (текстові T2I-підказки).
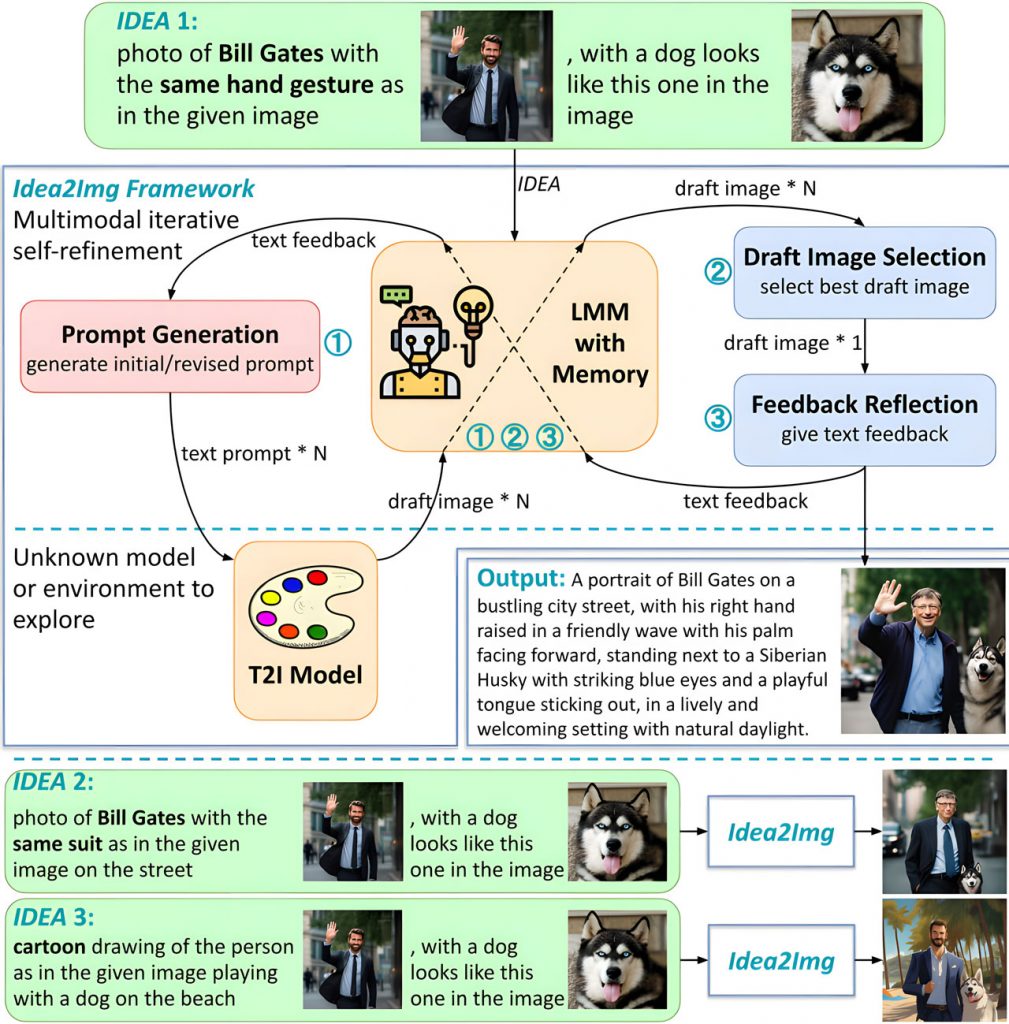
Мультимодальний ітеративний процес самоудосконалення в Idea2Img включає кілька ключових етапів:
- Генерація підказок: GPT-4V генерує набір з N текстових підказок, які відповідають початковій мультимодальній IDEA користувача, на основі попередніх текстових відгуків та історії уточнення.
- Вибір чорнового зображення: GPT-4V ретельно оцінює N ескізів, створених для однієї і тієї ж IDEA, і вибирає найбільш перспективний.
- Рефлексія зворотного зв’язку: GPT-4V аналізує розбіжності між чорновим зображенням та оригінальною IDEA, надаючи зворотній зв’язок про проблеми, причини цих проблем та пропозиції щодо покращення підказок T2I.
Крім того, Idea2Img має модуль пам’яті, який відстежує історію дослідження для кожного типу підказок (зображення, текст і зворотний зв’язок). Фреймворк циклічно перемикається між цими трьома процесами, полегшуючи автоматизований дизайн і генерацію зображень.
Що відрізняє Idea2Img від традиційних T2I-моделей, так це її здатність приймати директиви дизайну замість детальних описів зображень. Завдяки тому, що Idea2Img приймає мультимодальні IDEA та генерує зображення вищої семантичної та візуальної якості, він є цінним інструментом для користувачів, які потребують допомоги у створенні зображень та дизайну.
Щоб підтвердити його ефективність, дослідницька група провела дослідження вподобань користувачів, використовуючи 104 зразки оціночного набору IDEA зі складними запитаннями, які люди можуть вважати складними з першої спроби. Порівняння Idea2Img з різними моделями T2I показало значне покращення результатів, зокрема, на 26,9% у порівнянні з моделлю SDXL, що підкреслює переваги Idea2Img у покращенні процесу генерації зображень.
)
)
)
)
)
)
)
)
