

25.07.2024 17:09
Mistral випускає нову відкриту модель Mistral Large 2
Після того як Meta нещодавно випустила Llama 3.1, нову альтернативу провідним моделям із закритим кодом, французький ШІ-стартап Mistral представив наступне покоління своєї флагманської моделі, Mistral Large 2, яка має відкритий вихідний код. Ця модель може похвалитися 123 мільярдами параметрів і є ліцензованою для некомерційного використання в дослідницьких цілях, що дозволяє третім сторонам налаштовувати її за допомогою відкритих вагових коефіцієнтів. Для комерційного використання необхідна окрема ліцензія та угода про використання від Mistral, як зазначає у своєму блозі та на X науковець Девендра Сінгх Чаплот.
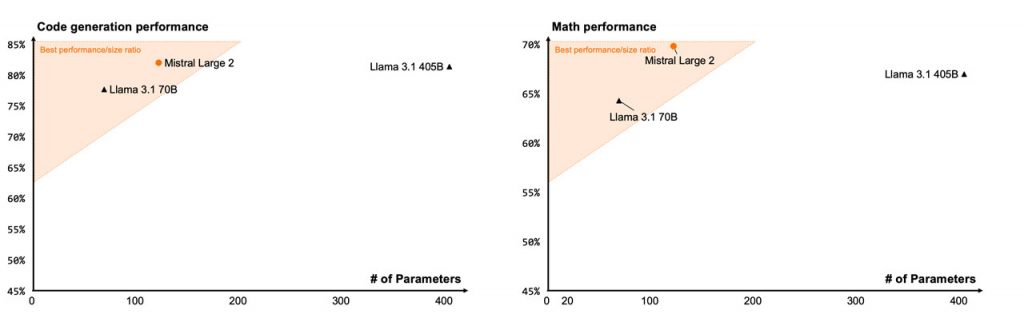
Маючи менше параметрів, ніж 405 мільярдів у Llama 3.1, Mistral Large 2 майже не поступається їй за продуктивністю. Модель, доступна на платформі компанії та через хмарних партнерів, розширює багатомовні можливості та добре справляється з міркуваннями, генерацією коду та математичними обчисленнями. За результатами різних тестів її можна порівняти з моделями класу GPT-4, такими як GPT-4o, Llama 3.1-405 та Claude 3.5 Sonnet від Anthropic.
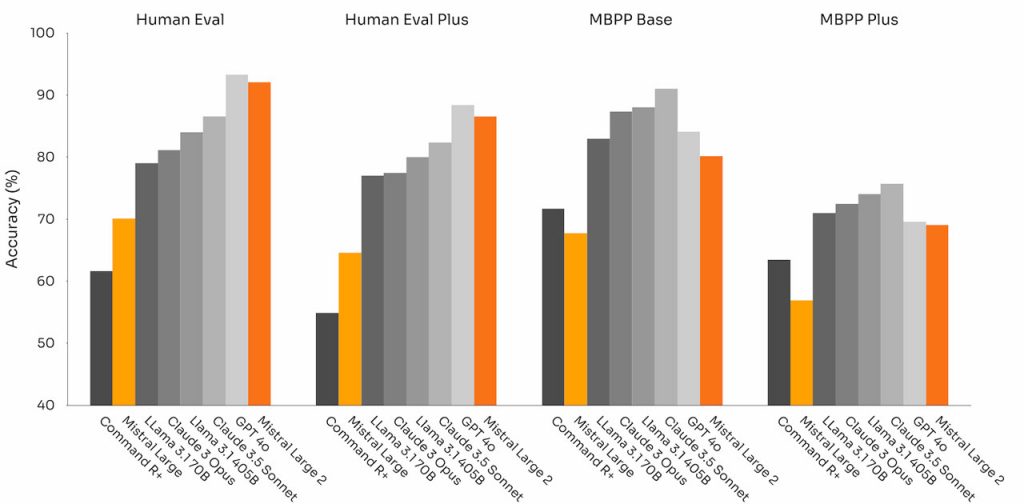
Mistral підкреслює ефективність своєї моделі з погляду вартості, швидкості та продуктивності, впроваджуючи такі функції, як розширений виклик і пошук функцій для покращення роботи додатків зі штучним інтелектом. Цей крок не є разовою відповіддю на Meta або OpenAI; Mistral активно розвиває свою технологію, запускає нові моделі та співпрацює з гігантами індустрії.
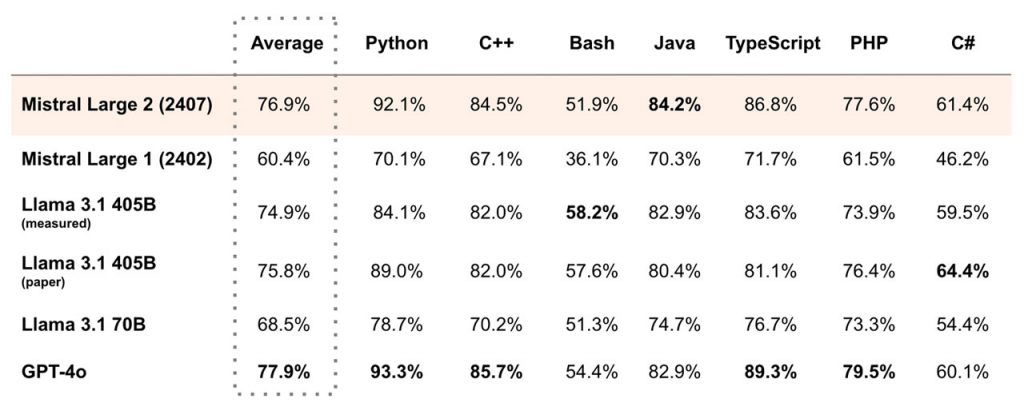
Оригінальна модель Large, яку було запущено в лютому, мала контекстне вікно на 32 000 лексем і демонструвала детальне розуміння граматики та культурного контексту. Нова версія розширена до 128 000 лексем і підтримує більше мов, зокрема португальську, арабську, хінді, китайську, японську та корейську. Вона чудово справляється зі складними завданнями, такими як синтетична генерація тексту та генерація коду.
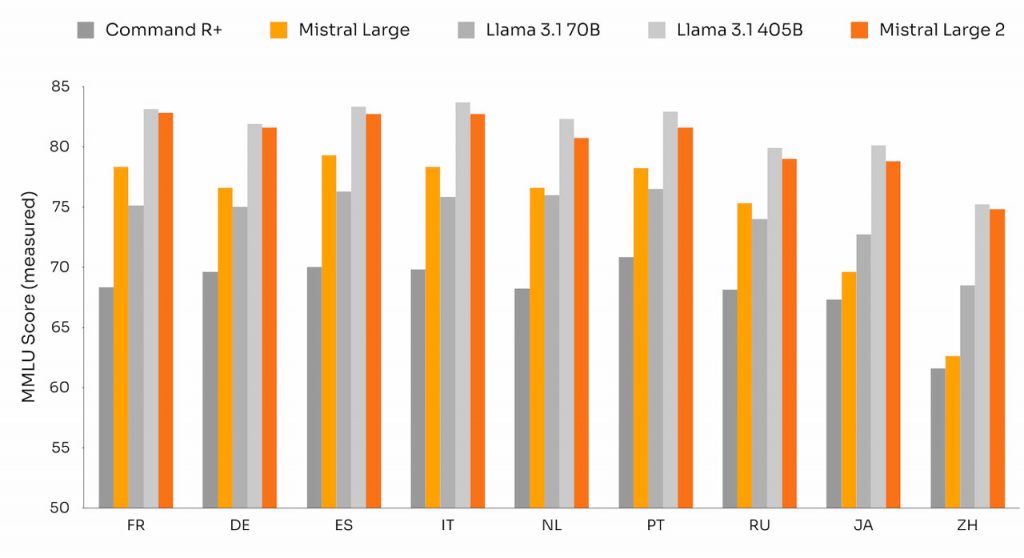
У багатомовному тесті MMLU Mistral Large 2 зрівнявся за продуктивністю з Llama 3.1-405B від Meta, пропонуючи при цьому значні економічні переваги завдяки меншим розмірам. Розроблена для одновузлового виводу з довгими контекстними додатками, її потужність у 123 мільярди параметрів забезпечує високу пропускну здатність на одному вузлі.
Нова модель також покращує виконання завдань кодування, генеруючи код на більш ніж 80 мовах програмування з високою точністю, перевершуючи Claude 3.5 Sonnet і Claude 3 Opus в таких бенчмарках, як HumanEval і HumanEval Plus, а також займаючи друге місце в математичних бенчмарках, таких як GSM8K і Math Instruct.with.
Команда Mistral також зосередилася на мінімізації галюцинацій, доопрацювавши модель для більш обережних і вибіркових реакцій, забезпечуючи прозорість у випадках, коли інформації недостатньо. Покращені можливості слідування інструкціям роблять модель пристосованою до довгих, багатооборотних розмов і надання лаконічних відповідей, що є корисним в корпоративних умовах.
Доступ до Mistral Large 2 можна отримати через кінцеву API-платформу компанії та через хмарні платформи, такі як Google Vertex AI, Amazon Bedrock, Azure AI Studio й IBM WatsonX. Користувачі також можуть протестувати новинку через чат-бот компанії.
)
)
)
)
)
)
)
)
