

21.11.2023 15:17
Метод штучного інтелекту SOTA для виявлення тексту, згенерованого LLM
ChatGPT зробив справжню революцію у створенні вільних текстів на широке коло тем, але оцінка їхньої достовірності має вирішальне значення через потенційні помилки в фактах і галюцинації. Ці моделі, включаючи ChatGPT, здатні генерувати відповіді на основі шаблонів у своїх навчальних даних, але вони не є безпомилковими і можуть створювати контент, який лише нагадує існуючу інформацію.
Занепокоєння щодо автентичності та оригінальності тексту, згенерованого цими моделями, призвело до обмежень на їх використання в освітніх установах. Той факт, що мовні моделі націлені на оригінальність і точність, не позбавляє користувачів необхідності проявляти розсудливість. Бажано не покладатися виключно на контент, створений штучним інтелектом, для прийняття критично важливих рішень або в ситуаціях, що вимагають експертної поради.
Різні фреймворки виявлення, такі як DetectGPT і GPTZero, намагаються ідентифікувати контент, створений за допомогою мовних моделей. Однак їхня ефективність може бути обмеженою, коли вони мають справу з наборами даних, на яких вони не були протестовані. Дослідники Каліфорнійського університету представили Ghostbusters – метод виявлення, заснований на структурованому пошуку та лінійній класифікації.
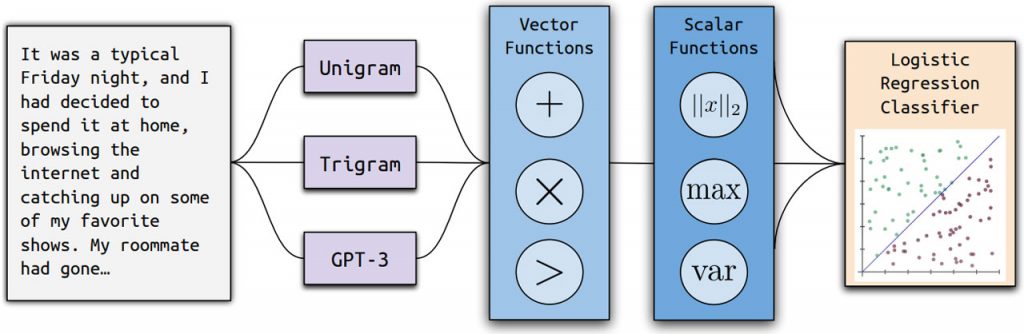
Процес навчання Ghostbuster складається з трьох етапів: обчислення ймовірності, вибір ознак і навчання класифікатора. Він перетворює документи у вектори, відбирає ознаки за допомогою структурованого пошуку і навчає класифікатор на основі ймовірнісних ознак і додаткових ознак, відібраних вручну. Класифікатори навчаються виявляти вміст, створений штучним інтелектом, враховуючи евристики, пов’язані з довжиною слів і ймовірністю токенів.
Продуктивність Ghostbuster надійно працює на різних наборах даних і перевершує попередні моделі. Він отримав оцінку 97,0 F1 в середньому за всіх умов, перевершивши DetectGPT на 39,6 F1 і GPTZero на 7,5 F1. Хоча він перевершив базову лінію RoBERTa в більшості доменів, його продуктивність була дещо гіршою у творчому письмі поза доменом. Показник F1, загальний показник для оцінки класифікаційної моделі, поєднує в собі точність і пригадування, пропонуючи комплексний вимір, особливо для незбалансованих наборів даних.
)
)
)
)
)
)
)
)
