

21.07.2023 13:18
Метод штучного інтелекту для поєднання LLM з моделями кодування та декодування зображень
З виходом нової версії OpenAI GPT 4 було запроваджено мультимодальність у великих мовних моделях. На відміну від попередньої версії, GPT 3.5, яка використовувалася лише для того, щоб дозволити відомому ChatGPT приймати текстові дані, остання версія GPT-4 приймає як текст, так і зображення. Нещодавно команда дослідників з Університету Карнегі-Меллона запропонувала підхід під назвою Generating Images with Large Language Models (GILL), який фокусується на розширенні мультимодальних мовних моделей для створення чудових унікальних зображень.
Метод GILL дозволяє обробляти вхідні дані, змішані з зображеннями і текстом, для створення тексту, отримання зображень і створення нових зображень. GILL досягає цього, незважаючи на моделі, що використовують окремі текстові кодери, шляхом перенесення вихідного простору вбудовування замороженої текстової моделі LLM до простору замороженої моделі, що генерує зображення. На відміну від інших методів, які вимагають чергування даних зображення і тексту, відображення відбувається шляхом точного налаштування невеликої кількості параметрів, використовуючи пари зображення і підписів.
Команда зазначає, що цей метод поєднує великі мовні моделі для замороженого тексту з моделями для кодування і декодування зображень, які вже були навчені. Він може забезпечити широкий спектр мультимодальних можливостей, таких як пошук зображень, створення унікальних зображень і мультимодальний діалог. Це досягається шляхом мапування просторів вбудовування модальностей з метою їхнього об’єднання. GILL працює з умовними змішаними вхідними даними зображень і тексту і створює вихідні дані, які є одночасно зв’язними і читабельними.
Цей метод забезпечує ефективну мережу відображення, яка прив’язує LLM до моделі перетворення тексту в зображення, щоб досягти високої продуктивності при генерації зображень. Ця мережа відображення перетворює приховані текстові представлення у простір вбудовування візуальних моделей. При цьому вона використовує потужні текстові представлення LLM для створення естетично узгоджених результатів.
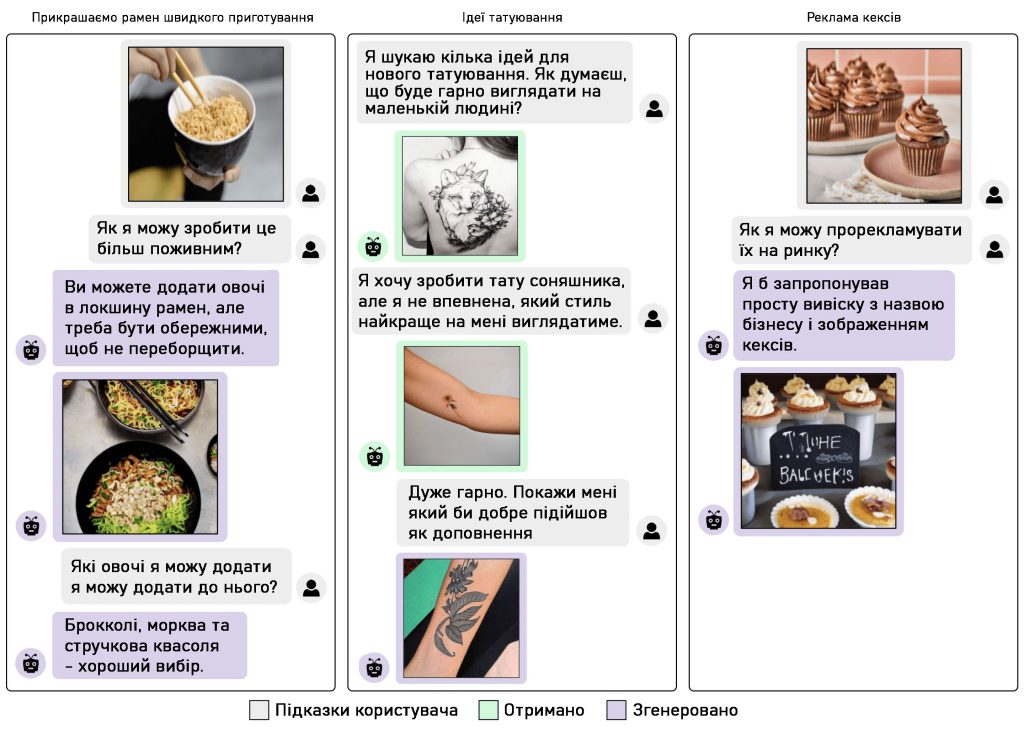
Завдяки такому підходу модель може отримувати зображення із заданого набору даних, а також створювати нові зображення. Модель обирає, чи створювати, чи отримувати зображення під час виведення. Для цього використовується модуль прийняття рішень, який залежить від прихованих представлень НМД. Цей підхід є ефективним з точки зору обчислень, оскільки він працює без необхідності запускати модель генерації зображень під час навчання.
Цей метод працює краще, ніж базові моделі генерації, особливо для завдань, що вимагають довшої та складнішої мови. Для порівняння, GILL перевершує метод стабільної дифузії в обробці довгих текстів, зокрема діалогів і дискусій. GILL краще генерує зображення, зумовлені діалогом, ніж моделі генерації, що не базуються на LLM, використовуючи мультимодальний контекст і генеруючи зображення, які краще відповідають заданому тексту. На відміну від звичайних моделей перетворення тексту в зображення, які обробляють лише текстове введення, GILL може також обробляти довільне чергування введення зображення і тексту.
На закінчення, GILL (Generating Images with Large Language Models) видається багатообіцяючою, оскільки вона демонструє ширший спектр можливостей порівняно з попередніми мультимодальними мовними моделями. Його здатність перевершувати моделі генерації, що не базуються на ЛВМ, у різних завданнях перетворення тексту в зображення, які вимірюють залежність від контексту, робить його потужним рішенням для мультимодальних завдань.
)
)
)
)
)
)
)
)
