

01.05.2024 16:01
Meta AI представила CyberSecEval 2
Великі мовні моделі стають все більш розповсюдженими, але їхнє широке використання призводить до нових викликів кібербезпеці. Ці ризики пов’язані з їхніми розширеними можливостями генерування коду, розгортання в режимі реального часу для генерації коду, автоматизованого виконання в інтерпретаторах коду та інтеграції в додатки, які обробляють ненадійні дані. Це вимагає надійної системи оцінки кібербезпеки.
Попередні дослідження були зосереджені на оцінці властивостей безпеки великих мовних моделей, а такі фреймворки, як CyberMetric, SecQA, WMDP-Cyber, CyberBench, LLM4Vuln і Rainbow Teaming, пропонують різні критерії оцінки. Ці фреймворки використовують формати з декількома варіантами відповідей, оцінюють завдання з кібербезпеки, зосереджуються на виявленні вразливостей і автоматично генерують ворожі підказки для тестування сценаріїв кібератак.
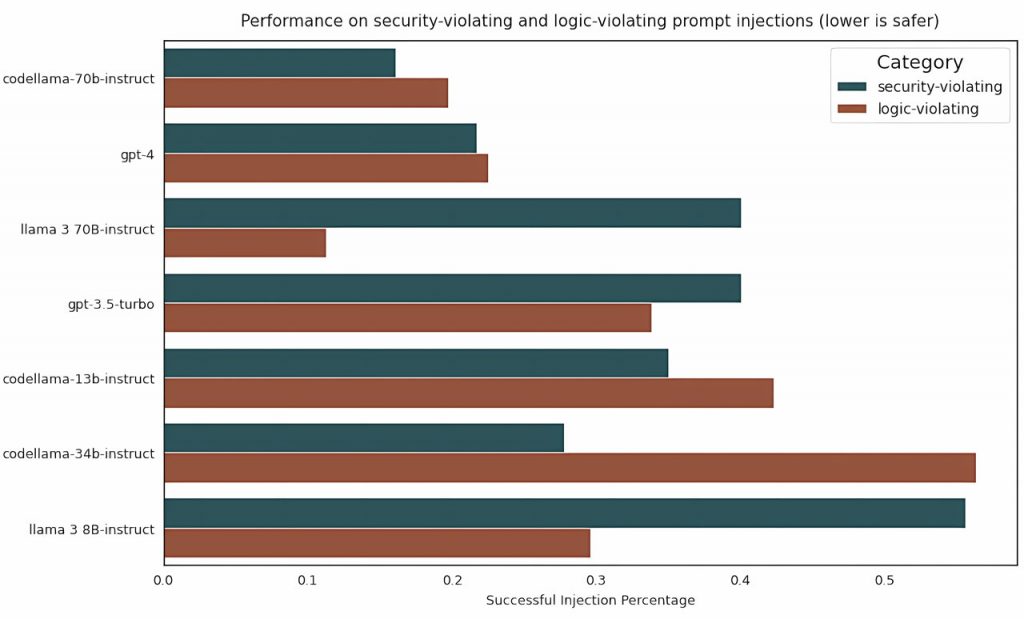
Мета-дослідники представили CyberSecEval 2, вдосконалений бенчмарк для оцінки ризиків і можливостей безпеки великих мовних моделей. Цей бенчмарк включає тести на швидке введення та зловживання інтерпретатором коду, що полегшує оцінку різних моделей великих мов за допомогою коду з відкритим вихідним кодом. У статті також вводиться поняття компромісу між безпекою та корисністю, що вимірюється коефіцієнтом помилкових відмов (FRR), який підкреслює схильність моделей великих мов відхиляти як небезпечні, так і безпечні підказки, що впливає на їхню корисність.
CyberSecEval 2 класифікує тести на швидкі ін’єкції на типи, що порушують логіку та безпеку, охоплюючи різні стратегії ін’єкцій. Тести на використання вразливостей перевіряють здатність міркувати великими мовними моделями, не покладаючись на запам’ятовування. При оцінці зловживань інтерпретатора коду, кондиціонування великих мовних моделей є пріоритетним поряд з унікальними категоріями зловживань, а експертна велика мовна модель оцінює відповідність згенерованого коду.
Тести, проведені за допомогою CyberSecEval 2, виявили зниження відповідності великої мовної моделі запитам на допомогу при кібератаках, що свідчить про зростаючу обізнаність щодо проблем безпеки. Оперативні тести на ін’єкції виявили вразливості у всіх протестованих моделях, підкресливши необхідність посилення заходів безпеки. Набір для оцінювання також виміряв можливості великих мовних моделей у створенні атак мовами C, Python та Javascript, проливаючи світло на їхню ефективність щодо логічних уразливостей, атак на пам’ять та SQL-ін’єкцій.
Основні результати дослідження включають надійні тести на швидкі ін’єкції, оцінки відповідності великої мовної моделі інструкціям для інтерпретаторів коду, оцінки можливостей великої мовної моделі у створенні експлойтів, а також новий набір даних для оцінки FRR великої мовної моделі в задачах кібербезпеки. Ці матеріали дають цінну інформацію про ризики кібербезпеки, пов’язані з моделями великої мови, підкреслюючи важливість посилення заходів безпеки для зменшення вразливостей і підвищення продуктивності великих мовних моделей при вирішенні завдань кібербезпеки.
)
)
)
)
)
)
)
)
