

18.03.2024 12:02
Масштабування мовних моделей за допомогою перенавчання
Вивчення законів масштабування у великих мовних моделях має вирішальне значення для їхнього поширення у штучному інтелекті. Ці закони керують розширенням моделей, виявляючи закономірності, що виходять за рамки простих обчислень, і дозволяючи їм точно розуміти людське мовлення. Закони масштабування також розблоковують потенціал для розуміння і створення мови, особливо в режимі оптимального для обчислень навчання, що передбачає втрати при прогнозуванні наступної лексеми.
Однак існуючі дослідження в галузі масштабування не збігаються з реальним навчанням та оцінюванням мовних моделей. Навчання великих мовних моделей є дорогим, часто призводячи до перенавчання, з метою зменшення витрат на виведення та оцінювання моделей на основі виконання наступних завдань. Досягнення високоякісних моделей вимагає складного поєднання алгоритмічних методів і навчальних даних, часто з використанням надійної екстраполяції для фінальних навчальних прогонів для створення найсучасніших моделей, таких як Chinchilla 70B, PaLM 540B і GPT-4.
Дослідники з різних університетів провели експерименти з тестовим стендом зі 104 моделей з параметрами від 0,011B до 6,9B, навчених на різній кількості токенів з наборів даних RedPajama, C4 і Refined Web. Це допомогло передбачити втрати валідації для моделей з параметрами 1.4B, 900B токенів і 6.9B параметрів, 138B токенів, пов’язавши заплутаність мовної моделі з подальшою продуктивністю завдання за допомогою степеневого закону.
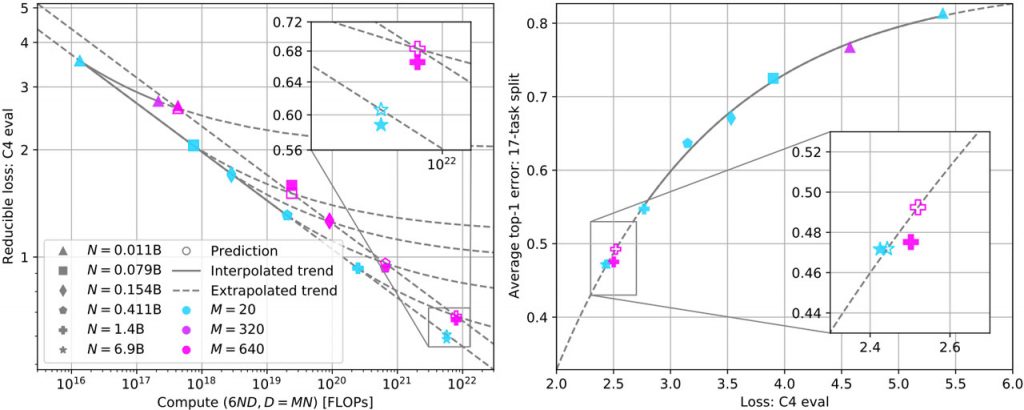
Закони масштабування, застосовані до менших моделей ближче до стадії обчислювального оптимуму, можуть точно передбачити продуктивність більших моделей, які значно надто треновані. Однак прогнозування помилок на окремих завданнях залишається проблематичним. Сукупна продуктивність надійно прогнозується на основі розгубленості моделі відносно інших, що навчалися на тому ж наборі даних, вказуючи на узгоджені степеневі закони зменшення втрат, пов’язаних з навчальними обчисленнями.
Для оцінки ступеня перенавчання використовуються множники маркерів, причому такі моделі, як Chinchilla 70B, мають множник маркерів 20, а LLaMA-2 7B використовує множник маркерів 290. Аналіз точок даних, навчених на трьох наборах даних, показує експоненціальне спадання середньої помилки в першій точці зі зменшенням втрат при оцінюванні C4.
Отже, дане дослідження ефективно вирішує проблему масштабування в режимі перенавчання та прогнозування продуктивності в подальшому. Поведінка масштабування втрат за межами обчислювального оптимуму є передбачуваною, що дозволяє прогнозувати продуктивність більш дорогих циклів з використанням менших проксі-серверів. Майбутні закони масштабування можуть включати гіперпараметри та розвивати аналітичну теорію для випадків, коли масштабування може бути невдалим.
)
)
)
)
)
)
)
)
