

29.07.2023 13:33
Керований LLM, який може виконувати завдання на реальних веб-сайтах, слідуючи інструкціям на природній мові
За допомогою великих мовних моделей (LLM) можна розв’язати низку завдань на природній мові, включаючи арифметику, здоровий глузд, логічні міркування, запитально-відповідні завдання, створення текстів і навіть інтерактивні завдання з прийняття рішень. Використовуючи можливості розуміння HTML і багатокрокових міркувань, LLM нещодавно продемонстрували чудові успіхи в автономній веб-навігації, де агенти керують комп’ютерами або переглядають Інтернет, щоб задовольнити задані інструкції на природній мові через послідовність комп’ютерних дій. Відсутність заданого простору дій, триваліші спостереження за HTML порівняно з тренажерами і відсутність знань домену HTML у LLM негативно вплинули на веб-навігацію на реальних веб-сайтах.
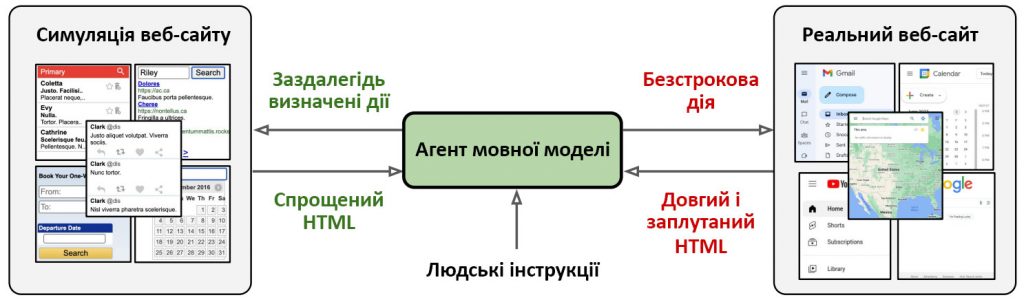
Враховуючи складність інструкцій і відкритість реальних веб-сайтів, нелегко заздалегідь вибрати правильний простір для дій. Останні LLM лише іноді мають оптимальний дизайн для опрацювання HTML-текстів, хоча різні дослідження стверджують, що налаштування інструкцій або навчання з підкріпленням на основі людського вводу покращує розуміння HTML і точність навігації в Інтернеті. Більшість LLM віддають перевагу широкому узагальненню завдань і масштабованості моделі, надаючи перевагу меншій тривалості контексту порівняно з типовими токенами HTML, що зустрічаються на реальних веб-сторінках, і відмовляючись від старих підходів до структурованих документів, включаючи вирівнювання текст-XPath і розділення токенів текст-HTML.
Навіть застосування вирівнювання на рівні токенів до таких довгих текстів було б відносно недорогим. Згрупувавши канонічні веб-операції в програмному просторі, вони пропонують WebAgent, автономний агент, керований LLM, який може виконувати завдання навігації на реальних веб-сайтах, дотримуючись людських команд. Розбиваючи інструкції природною мовою на менші кроки, WebAgent:
- Планує підінструкції для кожного кроку.
- Скорочує довгі HTML-сторінки до фрагментів, що відповідають завданням, на основі підінструкцій.
- Виконує підінструкції та фрагменти HTML на реальних веб-сайтах.
У цьому дослідженні дослідники з Google DeepMind і Токійського університету об’єднали дві магістерські програми для створення WebAgent: Нещодавно створена HTML-T5, попередньо навчена мовна модель доменного експерта, використовується для планування роботи та умовного узагальнення HTML. Flan-U-PaLM використовується для генерації обґрунтованого коду. Завдяки включенню в кодер методів локальної та глобальної уваги, HTML-T5 спеціалізується на кращому відображенні синтаксису структури та семантики довгих HTML-сторінок. Він є самоконтрольованим, попередньо навченим на великому корпусі HTML, створеному CommonCrawl1, з використанням комбінації довготривалих завдань зі зменшення шуму. Існуючі агенти, керовані LLM, часто виконують завдання прийняття рішень, використовуючи один LLM для підказки різних прикладів для кожного завдання. Однак цього недостатньо для реальних завдань, оскільки їхня складність перевищує складність симуляторів.
Згідно з ретельними оцінками, їхня інтегрована стратегія з плагінними мовними моделями покращує розуміння HTML і забезпечує більшу узагальненість. Ретельні дослідження показують, що зв’язок планування завдань зі стислим викладом HTML у спеціалізованих мовних моделях має вирішальне значення для виконання завдань, підвищуючи рівень успішності при реальній навігації в Інтернеті більш ніж на 50%. WebAgent перевершує окремі LLM у статичних завданнях розуміння веб-сайтів щодо точності контролю якості та має порівнянну продуктивність у порівнянні зі стандартними базовими показниками. Крім того, HTML-T5 функціонує як ключовий плагін для WebAgent і незалежно забезпечує передові результати при виконанні веб-завдань. У тесті MiniWoB++ HTML-T5 перевершує наївні локально-глобальні моделі уваги та їхні варіації, налаштовані за допомогою інструкцій, досягаючи на 14,9% більшого успіху, ніж попередня найкраща методика.
Вони зробили найбільший внесок:
- Вони надають WebAgent, який поєднує дві LLM для практичної веб-навігації. Універсальна мовна модель створює виконувані програми, тоді як експертна мовна модель домену займається плануванням і HTML-резюме.
- Застосовуючи локально-глобальну увагу та попереднє навчання з використанням комбінації довготривалого згладжування на великомасштабних корпусах HTML, вони створюють HTML-T5, нові специфічні для HTML мовні моделі.
- На реальному веб-сайті HTML-T5 значно підвищує показники успішності на понад 50%, а в MiniWoB++ він перевершує попередні агенти LLM на 14,9%.
)
)
)
)
)
)
)
)
