

05.04.2024 14:26
JetMoE-8B досягає рівня LLaMA2 і демократизує навчання та інновації в галузі ШІ
У сфері розвитку штучного інтелекту, де досягнення часто сприймаються як привілей технологічних гігантів зі значними фінансовими ресурсами, нещодавня співпраця між Лабораторією комп’ютерних наук і штучного інтелекту Массачусетського технологічного інституту (CSAIL) та Myshell AI спростувала це уявлення. Їхнє новітнє дослідження впроваджує JetMoE-8B, економічно ефективну та високопродуктивну велику мовну модель (LLM), яка кидає виклик традиційним фінансовим бар’єрам галузі та відкриває двері до більш інклюзивного ландшафту штучного інтелекту.
Суть JetMoE-8B полягає в її здатності досягати надзвичайної ефективності та продуктивності за мінімальну частку витрат, які зазвичай пов’язані з навчанням великих мовних моделей. Інвестиції в JetMoE-8B склали лише $0,1 млн, що значно менше, ніж мільярди, витрачені такими гігантами індустрії, як OpenAI та Meta, і це свідчить про те, що передові технології ШІ більше не обмежуються організаціями з глибокими кишенями.
Однією з ключових особливостей JetMoE-8B є його повністю відкритий вихідний код і дружній до академічних кіл дизайн. Покладаючись виключно на загальнодоступні набори даних для навчання і надаючи відкритий код, JetMoE-8B усуває необхідність у пропрієтарних ресурсах, роблячи його доступним для ширшого спектру дослідницьких установ, стартапів і компаній з обмеженим бюджетом. Така демократизація доступу до високоякісних моделей ШІ передбачає перехід до нової ери інновацій та співпраці у спільноті розробників технологій штучного інтелекту.
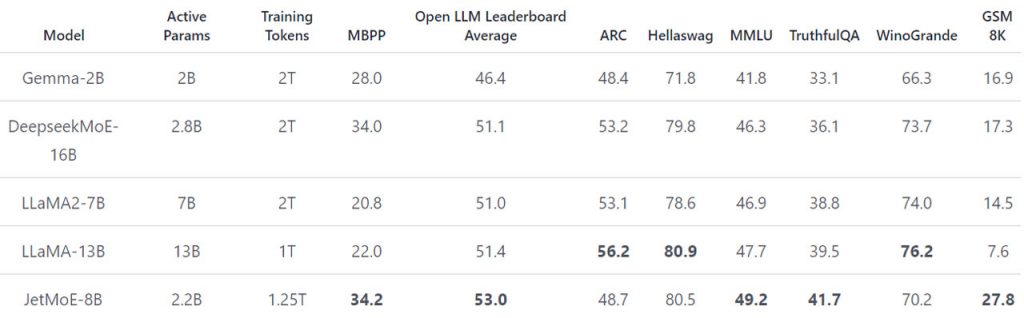
Архітектура JetMoE-8B свідчить про його ефективність та продуктивність. Використовуючи малоактивну архітектуру, натхненну ModuleFormer, JetMoE-8B складається з 24 блоків, кожен з яких містить два типи шарів Mixture of Experts (MoE). Така конструкція дає 8 мільярдів параметрів, з яких лише 2,2 мільярда активні під час отримання висновків, що значно зменшує обчислювальні витрати без шкоди для продуктивності. У порівняльних тестах JetMoE-8B перевершив моделі, навчені з більшими бюджетами та обчислювальними ресурсами, закріпивши свою позицію як новатора в галузі досліджень штучного інтелекту.
Процес навчання JetMoE-8B ще більше підкреслює його економічну ефективність. При використанні кластера графічних процесорів 96×H100 протягом двох тижнів загальна вартість навчання склала лише 0,08 мільйона доларів. Це досягнення стало можливим завдяки ретельній двофазній методології навчання, що включає постійну швидкість навчання з лінійним прогріванням і експоненціальним спадом швидкості навчання, в поєднанні з величезною навчальною базою з 1,25 трильйона токенів з відкритих джерел даних.
Ключові висновки з прориву JetMoE-8B різноманітні. По-перше, він спростовує уявлення про те, що високоякісне навчання LLM вимагає непомірних фінансових вкладень, доводячи, що досконалості в галузі штучного інтелекту можна досягти зі скромними бюджетами. По-друге, його відкритий характер і мінімальні обчислювальні вимоги під час тонкого налаштування демократизують доступ до передових технологій штучного інтелекту, сприяючи створенню більш інклюзивної та спільної екосистеми ШІ. Нарешті, JetMoE-8B встановлює нові стандарти ефективності та продуктивності, сигналізуючи про зміну парадигми розвитку ШІ в бік доступності, зручності та інновацій.
Демократизація навчання та інновацій в галузі ШІ, втілена в JetMoE-8B, обіцяє прискорити розвиток штучного інтелекту і розкрити творчий потенціал широкого кола користувачів, що в кінцевому підсумку формує майбутнє, в якому передовий технологічний прогрес буде доступним для всіх.
)
)
)
)
)
)
)
)
