

18.10.2023 12:46
Hайбільший попередньо навчений LLM з пошуком перед налаштуванням інструкцій
Команда дослідників з Nvidia та Університету Іллінойсу в Урбане-Шампейне представила захоплюючий прорив у сфері мовних моделей. Представляємо вам Retro 48B — гіганта серед мовних моделей, який може похвалитися 48 мільярдами параметрів, що є значним стрибком у порівнянні з попередніми моделями, доповненими пошуком, такими як Retro (7,5 мільярдів параметрів). Особливістю Retro 48B є попереднє навчання з пошуком на великому корпусі — стратегія, яка продемонструвала неабиякі перспективи в покращенні розпізнавання незрозумілих слів, фактографічності та загальної ефективності виконання завдань.
Мовні моделі, доповнені пошуком, добре зарекомендували себе у відповідях на запитання відкритого типу, продемонструвавши свою ефективність як під час попереднього навчання, так і під час виведення. Такий підхід не лише зменшує заплутаність моделі, але й підвищує її фактологічність, що в кінцевому підсумку покращує виконання завдань після точного налаштування. Хоча ці моделі показали свою ефективність, їхній відносно обмежений розмір порівняно з моделями, що використовують лише декодер, дещо обмежив їхній потенціал узагальнення з нуля, особливо при налаштуванні інструкцій. Однак з появою високоякісних наборів даних, таких як FLAN, OpenAssistant і Dolly, тюнінг інструкцій набув більш міцних позицій, що дозволило досягти чудової продуктивності в чатах і завданнях з відповідями на запитання.
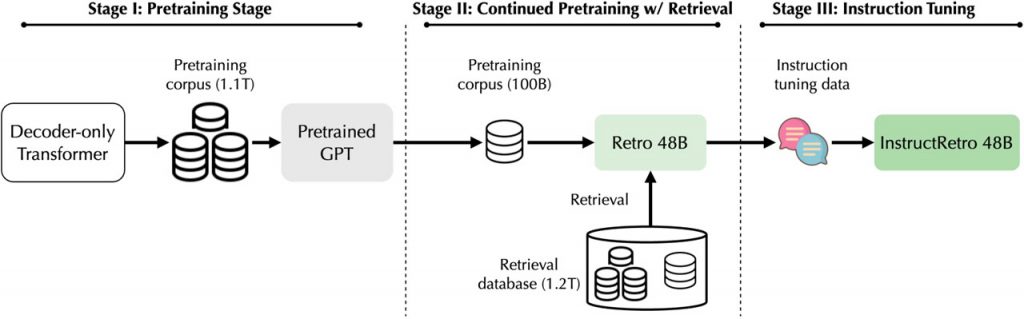
Дослідники зробили великий крок, представивши Retro 48B, найбільшу на сьогоднішній день модель, доповнену пошуком, що було досягнуто шляхом подальшого попереднього навчання GPT-моделі 43B з додатковими токенами. В результаті цього процесу вони створили InstructRetro, мовну модель з 48 мільярдами токенів, доповнену пошуком. Особливістю InstructRetro є її вражаюча продуктивність у пошуку відповідей на запитання без помилок, що є значним покращенням порівняно з традиційними моделями GPT. Фактично, вона досягає таких результатів, що кодер можна видалити, демонструючи неймовірну ефективність попереднього навчання, доповненого пошуком, для врахування контексту під час відповідей на запитання.
Це дослідження охоплює комплексний шлях від попереднього навчання моделі GPT до створення Retro 48B, інструктажу для покращення його здатності відповідати на запитання з нуля і, врешті-решт, оцінки його продуктивності при виконанні різних завдань. Впровадження InstructRetro 48B, цієї масивної мовної моделі, доповненої пошуком, значно підвищує точність безпомилкових відповідей у широкому діапазоні відкритих завдань з контролю якості порівняно з її аналогом GPT. Попереднє навчання Retro 48B з використанням пошуку значно зменшило кількість помилок, підкреслюючи потенціал попереднього навчання на основі пошуку для вдосконалення декодерів GPT у сфері відповідей на запитання.
Мабуть, найбільш інтригуючим є те, що лише основа декодера InstructRetro здатна забезпечити порівнянну точність. Цей інтригуючий результат підкреслює неабияку ефективність попереднього навчання з урахуванням контексту для відповідей на запитання. Модель чудово справляється з довгими завданнями контролю якості, що ще раз підкреслює потенціал попереднього навчання, доповненого пошуком, для складних завдань. У постійно мінливому ландшафті ШІ та мовних моделей Retro 48B та InstructRetro представляють значний прогрес у розумінні природної мови, піднімаючи планку можливого у світі відповідей на запитання, керованих ШІ.
)
)
)
)
)
)
)
)
