

03.08.2023 15:51
GPT-3 може мислити не гірше за студента коледжу, повідомляють психологи
Дослідження психологів з Каліфорнійського університету в Лос-Анджелесі показало, що, на диво, мовна модель штучного інтелекту GPT-3 демонструє такі ж результати, як і студенти старших курсів, коли їх просять розв’язати задачі на логічне мислення, які зазвичай з’являються в тестах на рівень інтелекту та стандартизованих тестах, таких як SAT. Дослідження опубліковане в журналі Nature Human Behaviour.
Але автори статті пишуть, що дослідження піднімає питання: чи імітує GPT-3 людське мислення як побічний продукт свого величезного набору даних з мовного навчання, або він використовує принципово новий тип когнітивного процесу?
Без доступу до внутрішніх механізмів GPT-3, які охороняються компанією-розробником OpenAI, вчені з Каліфорнійського університету не можуть сказати напевно, чим зумовлені когнітивні здібності цієї системи. Вони також пишуть, що хоча в деяких завданнях на мислення GPT-3 працює набагато краще, ніж вони очікували, цей інструмент все ще вражаюче провалюється в інших.
“Якими б вражаючими не були наші результати, важливо підкреслити, що ця система має серйозні обмеження, — каже Тейлор Вебб (Taylor Webb), доктор психологічних наук з Каліфорнійського університету в Лос-Анджелесі і перший автор дослідження. “Вона може міркувати за аналогією, але не може робити речі, які є дуже простими для людей, наприклад, використовувати інструменти для розв’язання фізичних задач. Коли ми давали ШІ такі завдання — деякі з яких навіть діти можуть вирішити відносно швидко — те, що він пропонував, було безглуздим”.
Вебб та його колеги перевірили здатність GPT-3 розв’язувати низку завдань, натхненних тестом, відомим під назвою “Прогресивні матриці Равена”, в якому досліджуваного просять передбачити наступне зображення у складному розташуванні фігур. Щоб GPT-3 міг “бачити” фігури, Вебб перетворив зображення в текстовий формат, який GPT-3 міг обробити; такий підхід також гарантував, що ШІ ніколи не зтикався з цими питаннями раніше.
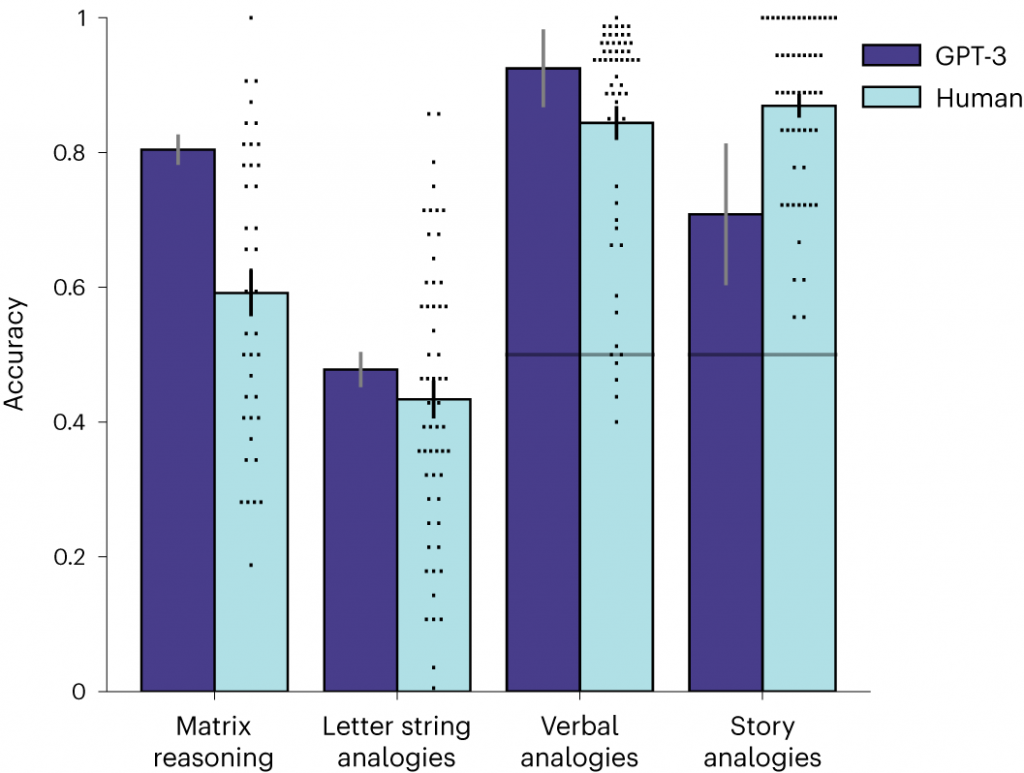
Дослідники попросили 40 студентів бакалаврату Каліфорнійського університету вирішити ті ж самі завдання.
“Дивно, але GPT-3 не тільки впорався з завданнями так само добре, як і люди, але й припускався тих самих помилок”, — сказав професор психології Каліфорнійського університету в Лос-Анджелесі Хунцзін Лу (Hongjing Lu), провідний автор дослідження.
Модель вирішила 80% завдань правильно — значно вище середнього показника для людей, який становить трохи менше 60%, але в межах діапазону найвищих людських результатів.
Дослідники також запропонували GPT-3 розв’язати низку аналогічних питань з тесту SAT, які, на їхню думку, ніколи не публікувалися в Інтернеті — це означає, що ці питання скоріш за все не були частиною навчальних даних GPT-3. У запитаннях користувачам пропонується вибрати пари слів, які мають однаковий тип зв’язку.
Вони порівняли результати моделі з опублікованими результатами тесту SAT-абітурієнтів коледжів і виявили, що ШІ показав кращі результати, ніж середній бал для людей.
Потім дослідники попросили GPT-3 і студентів-добровольців розв’язати аналогії на основі коротких оповідань — запропонувавши їм прочитати один уривок, а потім знайти іншу історію, яка передавала б той самий зміст. Технологія впоралася з цими завданнями гірше, ніж студенти, хоча GPT-4, остання ітерація технології OpenAI, показала кращі результати.
Дослідники з Каліфорнійського університету розробили власну комп’ютерну модель, натхненну людським пізнанням, і порівнювали її можливості з можливостями комерційного ШІ.
“ШІ ставав кращим, але наша психологічна модель ШІ все ще була найкращою у вирішенні завдань на аналогію до грудня минулого року, коли Тейлор отримав останню версію GPT-3, і вона була такою ж або навіть кращою”, — сказав професор психології Каліфорнійського університету в Лос-Анджелесі Кіт Голйоак, співавтор дослідження.
Дослідники зазначають, що GPT-3 поки що не може вирішувати завдання, які вимагають розуміння фізичного простору. Наприклад, якщо надати їй опис набору інструментів — скажімо, картонної трубки, ножиць і скотчу — за допомогою яких вона могла б перекладати жуйки з однієї миски в іншу, GPT-3 пропонувала химерні рішення.
“Моделі вивчення мови намагаються лише передбачати слова, тому ми здивовані, що вони можуть міркувати”, — каже Лу. “За останні два роки технологія зробила великий стрибок у порівнянні з попередніми імплементаціями”.
Вчені з Каліфорнійського університету сподіваються дослідити, чи дійсно моделі вивчення мови починають “думати” як люди, чи вони роблять щось зовсім інше, лише імітуючи людське мислення.
)
)
)
)
)
)
)
)
