

18.06.2024 17:10
Google DeepMind оприлюднила інформацію про прогрес технології перетворення відео в аудіо (V2A)
Моделі генерації відео продовжують розквітати, немов яскраві квіти в цифровому саду. Наступним значним стрибком у цій галузі є інтеграція звукових супроводів, яку має на меті здійснити одна з нових технологій. Йдеться про технологію перетворення відео в аудіо (V2A), яку розробники Google DeepMind анонсують як технологію синхронізованої аудіовізуальної генерації, що поєднує відеопікселі з текстовими підказками для створення насиченого звукового супроводу.
Технологія V2A розроблена для поєднання з такими моделями генерації відео, як Veo, що дозволяє створювати саундтреки з драматичними партитурами, реалістичними звуковими ефектами та діалогами, які відповідають характерам і тональності відео. Ця можливість також поширюється на традиційні відеоматеріали, включно з архівними матеріалами та німими кінострічками, що значно розширює діапазон творчих можливостей, доступних для режисерів і творців контенту.
Однією з особливостей технології V2A є її гнучкість. Вона може генерувати необмежену кількість звукових доріжок для будь-якого вхідного відеосигналу. Користувачі можуть використовувати «позитивні підказки», щоб спрямувати згенерований звук до бажаних значень, або «негативні підказки», щоб уникнути певних звуків. Ця функціональність дозволяє швидко експериментувати та обирати найкращий звуковий супровід для конкретного відео.
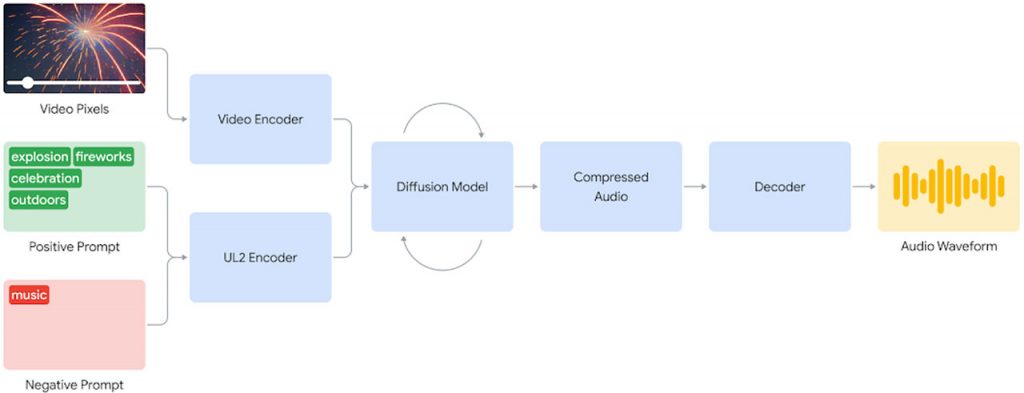
Шляхом ретельних експериментів розробники виявили, що дифузійний підхід до генерації звуку дає найбільш реалістичні та синхронізовані результати. Система V2A починає з кодування вхідного відеосигналу в стиснутий формат. Потім дифузійна модель ітеративно очищає звук від випадкових шумів, керуючись візуальним входом і підказками природною мовою. Остаточний аудіо вихід декодується у форму сигналу і поєднується з відео даними для створення цілісного аудіовізуального досвіду.
Щоб підвищити якість згенерованого аудіо та навчити модель відтворювати певні звуки, у навчальний процес були включені створені штучним інтелектом анотації з детальним описом звуку та розшифровкою розмовного процесу. Такий підхід дозволяє технології навчитися асоціювати певні звукові події з різними візуальними сценами, точно реагуючи на інформацію, надану в анотаціях або розшифровках.
Технологія V2A вирізняється тим, що розуміє необроблені пікселі, робить текстові підказки необов’язковими та усуває необхідність ручного вирівнювання звуку з відео. Однак, попри ці успіхи, все ще існують проблеми, які варто вирішити. Якість аудіовиходу тісно пов’язана з якістю відеовходу; будь-які спотворення або викривлення у відео можуть призвести до помітного падіння якості звуку. Крім того, покращення синхронізації губ для відео з мовленням залишається в активній фазі розробки, оскільки модель генерації відео може не залежати від транскриптів, що призводить до невідповідності рухів губ.
Розробляючи цю технологію, команда прагне до відповідального впровадження штучного інтелекту. Вони активно збирають відгуки від провідних фахівців, щоб удосконалити власний досвід, а також використовують інструментарій SynthID для нанесення авторських позначок на весь контент, створений за допомогою штучного інтелекту, щоб запобігти зловживанню. Перш ніж відкрити доступ до технології V2A широкому загалу, вона пройде ретельну оцінку безпеки та тестування. Перші результати є обнадійливими та вказують на те, що ця технологія може відіграти вирішальну роль у створенні фільмів із синхронізованим звуковим супроводом.
)
)
)
)
)
)
)
)
