

26.09.2023 12:22
Голлівуд вдома з моделлю ШІ, яка може досягти контрольованої генерації відео
Генеративний ШІ досяг значних успіхів за останні роки, особливо з появою великомасштабних моделей дифузії. Ці потужні моделі, що охоплюють як текстові, так і графічні дані, призначені для поступового перетворення випадкового шуму на складні та реалістичні результати, що нагадують поступовий розвиток об’єктів реального світу.
Дифузійні моделі в першу чергу проходять навчання на великих наборах даних, що містять реальні зображення або текст. Їхній унікальний підхід до створення контенту має великі перспективи в різних сферах, від розваг до освіти.
Крім того, вражаючий прогрес спостерігається у створенні відео. Ця технологія, заснована на глибокому навчанні та генеративних моделях, може створювати динамічний і реалістичний відеоконтент. Вона дозволяє створювати широкий спектр відео — від фантастичних сцен сновидінь до високореалістичних симуляцій нашого світу.
Історично, створення відео значною мірою покладалося на візуальні підказки з початкових кадрів, які мали обмеження у прогнозуванні складної часової динаміки. Останні дослідження змістилися в бік включення текстових описів і даних про траєкторії для кращого контролю.
Знайомтесь, DragNUWA — модель генерації відео з урахуванням траєкторії, яка забезпечує тонкий контроль. Вона легко інтегрує текст, зображення та інформацію про траєкторію, забезпечуючи надійне та зручне керування.

DragNUWA працює за простою формулою з трьома основними механізмами керування: семантичним, просторовим і часовим.
- Семантичний контроль: Текстові описи відіграють вирішальну роль у додаванні сенсу та семантики до створеного відео. Вони передають намір, що стоїть за відео, розрізняючи, наприклад, реальну рибу, що плаває, та її зображення на картині.
- Просторовий контроль: Зображення використовуються для візуального контролю, пропонуючи просторовий контекст і деталі для точного представлення об’єктів і сцен у відео. Вони надають створеному контенту глибини та чіткості.
- Часове керування: Інновація полягає в управлінні траєкторією. DragNUWA використовує управління траєкторією у відкритому домені, що було проблемою для попередніх моделей. Він використовує семплер траєкторії (Trajectory Sampler, TS), багатомасштабне злиття (Multiscale Fusion, MF) та адаптивне навчання (Adaptive Training, AT) для створення відео зі складними траєкторіями з відкритою областю, реалістичними рухами камери та складними взаємодіями між об’єктами.
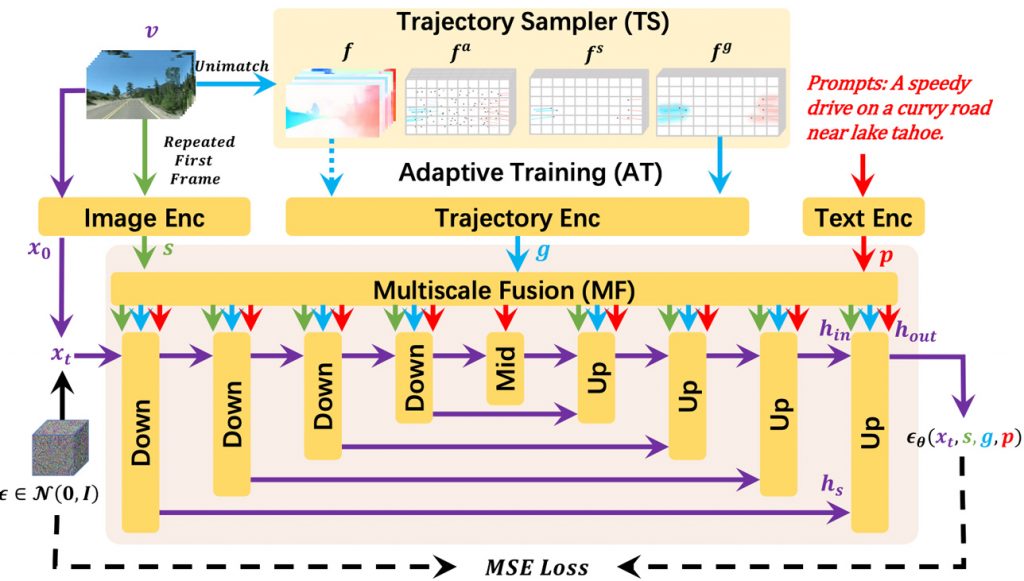
DragNUWA представляє комплексне рішення, яке об’єднує ці три механізми керування — текст, зображення та траєкторію. Ця інтеграція надає користувачам точний та інтуїтивний контроль над відеоконтентом. Вона революціонізує управління траєкторією при створенні відео, роблячи його придатним для складних і різноманітних відеосценаріїв.
)
)
)
)
)
)
)
)
