

31.10.2023 12:17
Фреймворк імітаційного навчання для маніпуляцій на основі зору з об’єктно-орієнтованими 3D-пріоритетами
Оскільки штучний інтелект продовжує набирати популярність і знаходити застосування в різних сферах, навчання через імітацію (IL) виявилося ефективним методом навчання нейромережевих візуально-моторних стратегій, що дозволяє їм виконувати складні маніпуляційні задачі. Проблема створення роботів, здатних виконувати широкий спектр маніпуляційних завдань, давно спантеличує робототехнічну спільноту. Реальні умови вносять елементи навколишнього середовища, такі як зміна перспективи камери, зміщення фону та поява нових об’єктів, які постійно створюють проблеми для традиційних методів робототехніки.
Підвищення стійкості та адаптивності алгоритмів штучного інтелекту до змінних навколишнього середовища має вирішальне значення для використання їхнього потенціалу. Попередні дослідження показали, що навіть незначні візуальні зміни в навколишньому середовищі, такі як зміна кольору фону, зміна точки зору камери або поява нових об’єктів, можуть вплинути на всю політику навчання. Тому політику навчання часто оцінюють у контрольованих умовах, використовуючи добре відкалібровані камери та фіксовані фони.
Нещодавно дослідники з Техаського університету в Остіні та Sony AI представили нову техніку імітаційного навчання під назвою GROOT, призначену для створення надійних правил для завдань маніпулювання на основі зору. GROOT вирішує проблему забезпечення ефективної роботи роботів у реальних умовах, де фактори навколишнього середовища часто змінюються, включаючи зміни фону, ракурсу камери та появу нових об’єктів. Щоб подолати ці перешкоди, GROOT зосереджується на створенні об’єктно-орієнтованих 3D-представлень і використовує трансформаційний підхід для міркувань над цими представленнями. Він також вводить модель зв’язків для сегментації, що дозволяє узагальнювати політики для нових об’єктів під час тестування.
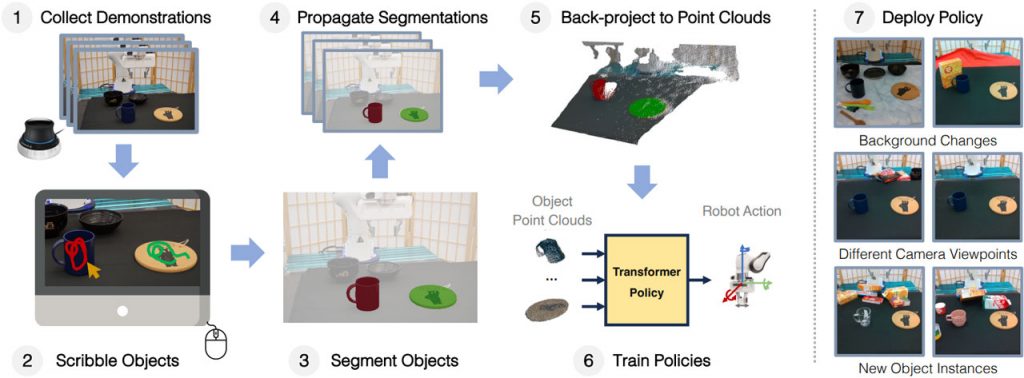
Основна інновація GROOT полягає в розробці об’єктно-орієнтованих 3D-репрезентацій. Ці уявлення керують сприйняттям робота, дозволяючи йому зосередитися на релевантних для завдання аспектах, фільтруючи візуальні відволікаючі фактори. Мислячи в трьох вимірах, GROOT забезпечує роботові більш інтуїтивне розуміння навколишнього середовища, покращуючи його здатність приймати рішення. Трансформаторний підхід, який використовує GROOT, полегшує ефективний аналіз цих об’єктно-орієнтованих тривимірних зображень, що є значним кроком на шляху до оснащення роботів більш досконалими когнітивними здібностями.
Особливістю GROOT є його здатність до узагальнення, що виходить за рамки початкових умов навчання, адаптуючись до різних фонів, кутів камери і наявності раніше невидимих об’єктів. Така адаптивність різко контрастує з багатьма методами роботизованого навчання, які не можуть працювати в таких динамічних умовах. GROOT є винятковим рішенням для складних завдань, з якими роботи стикаються в реальному світі, завдяки своїй чудовій здатності до узагальнення.
Дослідники провели широке тестування GROOT, оцінюючи його продуктивність як в змодельованих, так і в реальних умовах. У змодельованих сценаріях GROOT продемонстрував виняткову продуктивність, особливо за наявності варіацій сприйняття, перевершивши сучасні методи, такі як стратегії, засновані на об’єктних пропозиціях, і наскрізні підходи до навчання.
Таким чином, GROOT є значним досягненням в галузі роботизованого зору і навчання. Його акцент на надійності, адаптивності і узагальненні в реальних сценаріях відкриває двері для численних потенційних застосувань. GROOT ефективно вирішує складні завдання надійного маніпулювання роботами в динамічному середовищі, дозволяючи роботам безперешкодно працювати в складних і постійно мінливих умовах.
)
)
)
)
)
)
)
)
