

14.02.2024 17:51
Ефективність та обмеження послідовного моделювання
Розуміння та генерування послідовностей, від мови до музики, стало однією з ключових задач штучного інтелекту. На цій арені панують трансформери, відомі своєю безпрецедентною здатністю фіксувати нюанси послідовних даних. Однак прагнення до ефективності стимулює дослідження, що призвело до появи узагальнених моделей простору станів (GSSM). Ці моделі, які можуть похвалитися ефективністю завдяки пам’яті фіксованого розміру, кидають виклик моделям, заснованим на архітектурі трансформерів, і викликають дискусії про їхні справжні можливості.
В основі цих дебатів лежить критично важливе завдання реплікації послідовностей, що є випробуванням для будь-якої моделі послідовностей на міцність. Хоча GSSM видаються перспективними, традиційні методи часто спотикаються там, де трансформери досягають успіху. Це спонукало дослідників заглибитись у дослідження, порівнюючи ці архітектури, щоб знайти найкращу для задач з послідовністю.
Нещодавнє дослідження гарвардських дослідників проливає світло на цю битву, використовуючи як теоретичний аналіз, так і емпіричне тестування. Їхні висновки демонструють притаманну трансформерам перевагу в реплікації послідовностей, що значно перевищує можливості GSSM. Ця перевага випливає з динамічної пам’яті трансформера, що дозволяє йому обробляти і реплікувати експоненціально довші послідовності — досягнення, яке не під силу GSSM з їхніми обмеженнями фіксованого розміру.
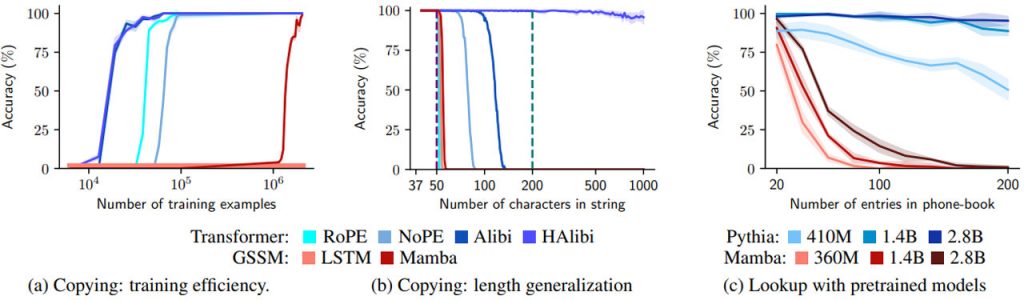
(b) Копіювання: узагальнення довжини. Навчаємо моделі копіювати на рядках довжиною ≤ 50, поки всі моделі не досягнуть ідеального розподілу, і оцінюємо точність на рівні рядків. Фіолетова пунктирна лінія вказує на максимальну довжину навчального рядка, а зелена пунктирна лінія вказує на контекстне вікно під час навчання. Оцінюючи довші вхідні дані, трансформаційні моделі значно перевершують GSSM. Використовуючи позиційне кодування Hard-Alibi, можна навіть узагальнити дані, що виходять далеко за межі розміру навчального контексту. (c) Пошук за допомогою попередньо навчених моделей. Тут завдання вимагає пошуку та отримання номера з “телефонної книги” різного розміру, який повністю знаходиться в контексті. Ми оцінюємо попередньо навчені моделі на одній спробі без жодних налаштувань. Pythia (побудована на архітектурі трансформерів) значно перевершує Mamba (GSSM). Джерело
Подальші експерименти підтверджують ці теоретичні висновки, демонструючи перевагу трансформерів у реплікації послідовностей, ефективності та узагальненні в різних синтетичних задачах. Ці задачі, розроблені для імітації реальних додатків, що вимагають пошуку та реплікації послідовностей, виявляють обмеження GSSM, коли вони стикаються з операціями, що потребують багато пам’яті.
Дослідження показало, що моделі на основі архітектури трансформерів перевершують GSSM в задачах, які вимагають від моделі запам’ятовування та реплікації частин вхідної послідовності. Ця перевага означає кращу ефективність і ширше застосування в різноманітних задачах, від простої реплікації послідовностей до складного пошуку інформації. Ці висновки очевидні в різних експериментах, що підкреслюють переваги трансформера в доступі та маніпулюванні великими частинами вхідної послідовності.
З цього дослідження випливає кілька ключових висновків:
- Динамічна пам’ять розширює можливості моделей, заснованих на трансформаційній архітектурі: Трансформери з їхніми механізмами динамічної пам’яті перевершують GSSM у моделюванні послідовностей, особливо в задачах, пов’язаних з реплікацією вхідної послідовності або пошуком контекстної інформації.
- Фіксована пам’ять обмежує GSSM: Теоретичний та емпіричний аналізи висвітлюють внутрішні обмеження GSSM через їхній фіксований розмір латентного стану, підкреслюючи архітектурну перевагу трансформерів для задач, що потребують багато пам’яті.
- Майбутнє належить гібридним моделям: Це дослідження прокладає шлях для майбутніх досліджень гібридних моделей, які могли б поєднати обчислювальну ефективність GSSM з можливостями динамічної пам’яті трансформерів, відкриваючи нові шляхи для прогресу в ШІ.
Насамкінець, битва за першість у моделюванні послідовностей, можливо, ще не закінчена. Хоча сьогодні трансформери утримують перевагу завдяки своїй динамічній пам’яті, GSSM пропонують кращу ефективність. Майбутнє може полягати в об’єднанні їхніх сильних сторін, створенні гібридних моделей, які розкриють ще більший потенціал у світі штучного інтелекту.
)
)
)
)
)
)
)
)
