

19.04.2024 16:00
Дослідження теоретичних основ та застосування дифузійних моделей в ШІ
Дифузійні моделі стали потужною альтернативою у сфері генеративного ШІ, продемонструвавши неабиякий успіх у різних галузях, таких як комп’ютерний зір, аудіосинтез, навчання з підкріпленням та обчислювальна біологія. На відміну від традиційних методів, таких як генеративні змагальні мережі (GAN) та варіаційні автокодери (VAE), яким притаманні обмеження щодо точності та ефективності обробки даних високої розмірності, дифузійні моделі пропонують надійні та адаптивні рішення для генерації нових зразків, пристосованих до конкретних завдань.
Хоча дифузійні моделі є перспективними, їхня теоретична база є відносно обмеженою, що створює труднощі для подальшого методологічного розвитку. Однак останні дослідження спрямовані на подолання цих обмежень і підвищення продуктивності дифузійних моделей, зокрема, шляхом інтеграції умовних параметрів, які уможливлюють точну генерацію зразків.
Значний внесок у розвиток можливостей дифузійних моделей зробило дослідження, проведене вченими з Принстонського університету та Каліфорнійського університету в Берклі. Методологія дослідження полягає у застосуванні складних моделей умовної дифузії, які використовують керуючі сигнали, щоб спрямувати генерацію зразків даних до бажаних властивостей. Такий підхід не тільки підвищує точність, але й забезпечує ефективність обробки даних високої розмірності.
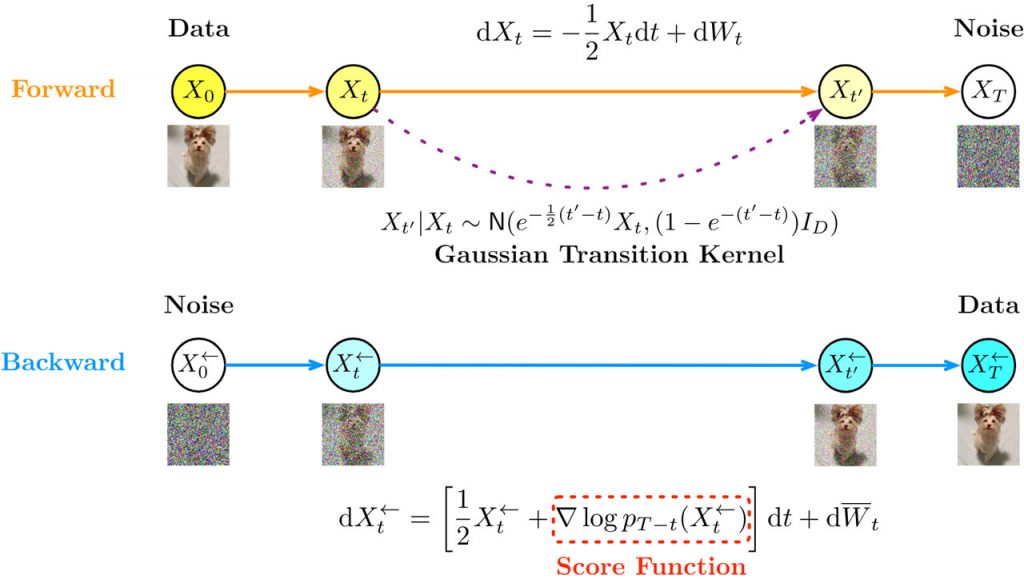
Оцінка запропонованої методології включала ретельне тестування з використанням стандартних наборів даних, таких як ImageNet для візуальних завдань і LibriSpeech для аудіо завдань. Архітектура моделі включала фази прогресивного додавання шуму та стратегічного зменшення шуму в поєднанні з вдосконаленими нейромережевими шарами для систематичного вдосконалення генеративних виходів. Результати дослідження продемонстрували значне покращення якості зразків, точності та ефективності генерації порівняно з традиційними підходами.
У задачах обробки зображень з використанням ImageNet цей підхід значно зменшив початкову відстань Фреше (FID) на 15%, що свідчить про суттєве покращення якості зразків. Аналогічно, у завданнях на синтез звуку, що оцінювалися за допомогою LibriSpeech, методологія покращила чіткість на 20% на основі суб’єктивних тестів на слух. Крім того, дослідження показало скорочення часу генерації зразків на 30%, що підкреслює підвищену ефективність запропонованого підходу.
Загалом, дослідження Принстонського та Каліфорнійського університетів у Берклі вносять значний внесок у теоретичне розуміння та практичне застосування моделей дифузії в генеративному штучному інтелекті. Завдяки вдосконаленню умовних параметрів і оптимізації процесу моделювання, дослідження прокладає шлях до більш точних, ефективних і якісних генеративних моделей у різних сферах застосування ШІ.
)
)
)
)
)
)
)
)
