

06.11.2023 17:40
Дослідницька група розробила модель штучного інтелекту для ефективного усунення упереджень у наборі даних
Процес збору даних за допомогою штучного інтелекту створює значний ризик введення ненавмисних помилок. Навчання моделі на упереджених даних, а потім її застосування до даних, що не піддаються розподілу, може призвести до значного зниження продуктивності. Тому усунення та пом’якшення упередженості в системах ШІ має вирішальне значення. У попередніх дослідженнях вивчалися методи зменшення або усунення упередженості, в тому числі такі методи, як змагальне навчання для вилучення незалежних від упередженості ознак. Хоча ці підходи виявилися багатообіцяючими, їм часто важко повністю відокремити ознаки схильності до упередження від моделей.
Команда з Інституту науки і технологій Дейгу Гьонбук (DGIST) представила нову модель перекладу зображень з потенціалом для значного зменшення упередженості даних. Навіть коли модель ШІ будується на основі різноманітної колекції фотографій з різних джерел, упередження можуть зберігатися, впливаючи на продуктивність моделі. Ця нова модель може зменшити упередженість даних без попереднього знання про ці упередження, пропонуючи значні переваги в таких галузях, як автономні транспортні засоби, створення контенту та охорона здоров’я.
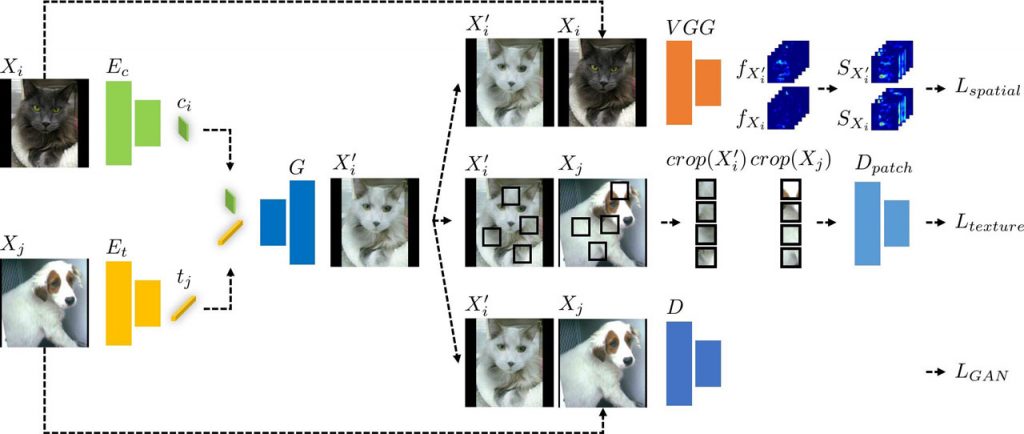
Однією з поширених проблем моделей глибокого навчання є навчання на упереджених наборах даних, що може призвести до того, що моделі навчаться зосереджуватися на відмінностях у процедурах обробки зображень, а не на важливих якостях, необхідних для точної ідентифікації. Рішення команди враховує втрату просторової самоподібності, співпадіння текстур і втрати GAN, щоб генерувати високоякісні зображення з послідовним вмістом і схожими локальними і глобальними текстурами. Після того, як ці зображення створені на основі навчальних даних, можна навчати класифікатор або модифіковану модель сегментації.
Ключові переваги цього підходу такі:
- Спільна поява текстур та втрата просторової самоподібності: Дослідники запропонували використання втрат текстури та просторової самоподібності для перекладу зображень, які раніше не досліджувалися незалежно один від одного. Показано, що ці втрати генерують оптимальні зображення для згладжування та адаптації до домену, коли обидва типи втрат оптимізовано.
- Ефективне пом’якшення неочікуваних упереджень: Дослідники представили стратегію навчання наступних задач, яка ефективно зменшує непередбачувані упередження під час навчання. Це досягається шляхом явного збагачення навчального набору даних без використання міток упередженості. Крім того, цей підхід не залежить від модуля сегментації, що робить його сумісним з найсучаснішими інструментами сегментації.
- Висока продуктивність: Створена модель глибокого навчання перевершує існуючі алгоритми завдяки створенню набору даних шляхом згладжування текстур і використання його для навчання. Вона працює краще, ніж попередні методи, на наборах даних з текстурними упередженнями, наприклад, для класифікації чисел, розрізнення собак і котів з різним кольором шерсті та ідентифікації COVID-19 від бактеріальної пневмонії.
Таким чином, модель перекладу зображень, розроблена командою DGIST, є значним кроком у вирішенні проблеми упередженості даних у системах штучного інтелекту та пом’якшення її наслідків. Оптимізувавши співпадіння текстур і втрати просторової самоподібності, вони досягли чудових результатів у дебазисі та перекладі зображень, перевершивши існуючі методи на різних наборах даних з упередженнями.
)
)
)
)
)
)
)
)
