

14.08.2023 12:30
Дослідники Salesforce представили XGen-Image-1
Поєднання штучного інтелекту та створення візуального контенту відкрило неабиякі можливості у сферах маркетингу, продажів та електронної комерції. Це поєднання знаменує собою значний прогрес, формуючи нову еру цифрової комунікації та трансформуючи способи взаємодії бізнесу зі своєю аудиторією. З розвитком технологій межа між текстом і зображенням стирається, відкриваючи світ більших творчих можливостей.
У цьому мінливому ландшафті команда Salesforce Research представляє надзвичайну інновацію: XGen-Image-1. Цей прорив у галузі генеративного штучного інтелекту зосереджений на перетворенні тексту в зображення. Використовуючи можливості моделей дифузії, що генерують зображення, XGen-Image-1 має потенціал, щоб переосмислити візуальний досвід. Навчання моделі з використанням досвіду та інновацій, проведене з бюджетом у $75 тисяч та за допомогою TPU і набору даних LAION, є видатним досягненням. Ця розробка конкурує з такими відомими моделями, як Stable Diffusion 1.5/2.1, які досі незмінно були на перших позиціях у галузі генерації зображень.
Розробники досягли злиття латентної моделі під назвою варіаційний автокодер (Variational Autoencoder, VAE) з легкодоступними апсемплерами, що стало основою їхньої інновації. Ця унікальна комбінація дозволяє навчатися з надзвичайно низькою роздільною здатністю, наприклад, 32×32 пікселі, і водночас без зусиль генерувати зображення з високою роздільною здатністю 1024×1024. Такий підхід значно скорочує витрати на навчання, зберігаючи при цьому найкращу якість зображень. Вміло використовуючи автоматизовану вибірку відбраковування, а також оцінювання та уточнення за допомогою PickScore під час процесу виведення, команда стратегічно покращує свої результати. Ця ретельна стратегія постійно створює першокласні зображення, підвищуючи надійність технології.
Занурюючись далі у свою методологію, команда розкриває шари свого підходу. XGen-Image-1 використовує модель латентної дифузії, ефективно поєднуючи піксельні та латентні моделі дифузії. У той час як піксельні моделі безпосередньо маніпулюють окремими пікселями, латентні моделі використовують зашумлені автокодовані представлення зображень у стиснутій просторовій області. Дослідження балансу між ефективністю навчання та роздільною здатністю в кінцевому підсумку призвело до інтеграції попередньо навченого автокодування та моделей з підвищеною дискретністю пікселів.
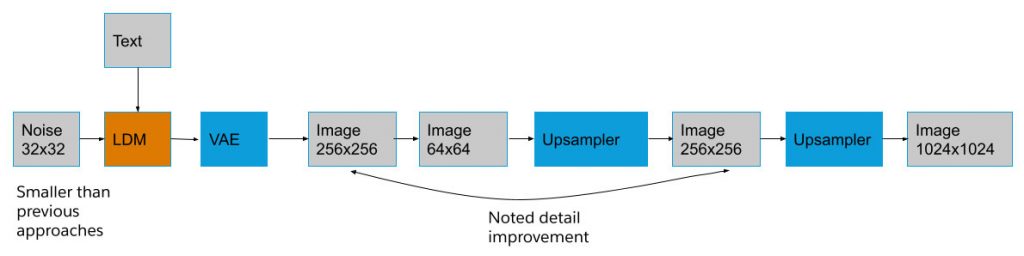
Навчання XGen-Image-1 ґрунтується на ретельно відібраному наборі даних LAION-2B, що містить зображення з естетичною оцінкою 4,5 або вище. Цей набір даних є наріжним каменем для навчання моделі, пропонуючи багатий набір концепцій, які зумовлюють її здатність генерувати різноманітні та реалістичні зображення. Оптимізація навчальної інфраструктури з використанням TPU v4s демонструє інноваційні навички команди у вирішенні проблем, ефективно вирішуючи виклики, пов’язані зі зберіганням та управлінням контрольно-пропускними пунктами.
Оцінка продуктивності слугує критичною параметром XGen-Image-1. Порівняння з моделями Stable Diffusion 1.5 і 2.1 підкреслює її можливості, продемонстровану за такими показниками, як CLIP Score і FID. Зокрема, XGen-Image-1 перевершує моделі зі стабільною дифузією за швидкістю вирівнювання та фотореалістичністю, демонструючи конкурентоспроможні показники за людськими оцінками. Та ж сама людська оцінка ще більше впливає на порівняння цієї нової розробки з найкращими існуючими моделями. Впровадження вибірки відбракування стає потужним інструментом для покращення результатів, доповненим стратегічними прийомами, такими як зафарбовування для покращення менш задовільних елементів.
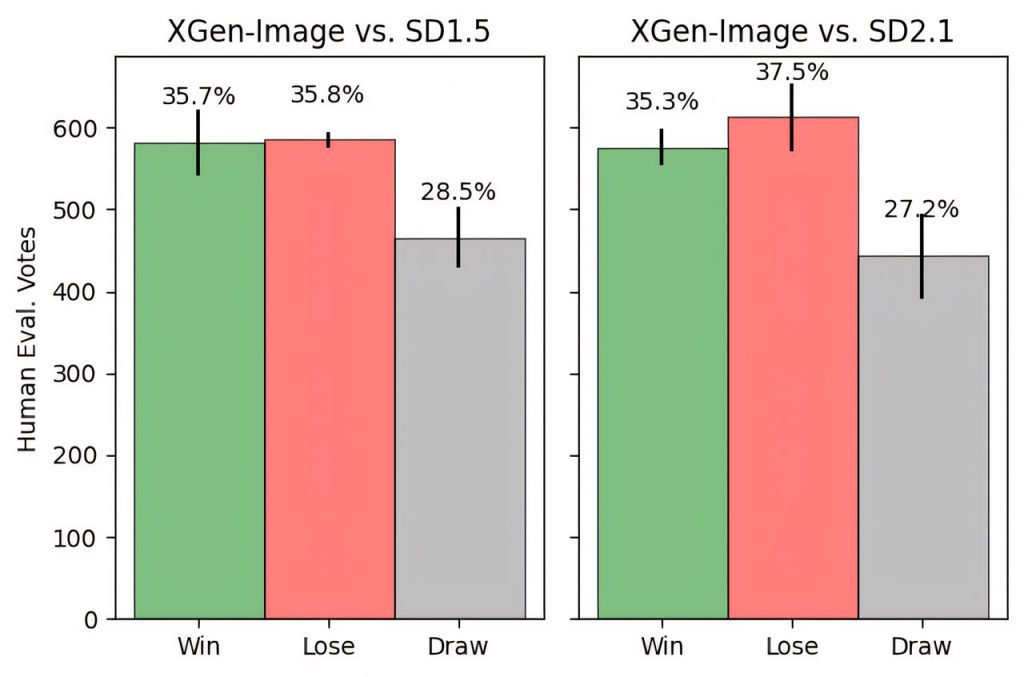
У міру того, як розробка продовжується XGen-Image-1, інсайти команди будуть формувати траєкторію створення зображень за допомогою штучного інтелекту, прокладаючи шлях до трансформаційних досягнень, які знаходять відгук у різних галузях.
)
)
)
)
)
)
)
)
