

16.07.2023 15:20
Ця модель штучного інтелекту надає моделям дифузії 3D-свідомість для надійної генерації тексту у 3D формат
Моделі текст-до-X останнім часом стрімко зросли у своєму розвитку, і більшість прогресу досягнуто в моделях текст-до-зображення. Ці моделі можуть генерувати фотореалістичні зображення за допомогою заданого текстового вказівника.
Генерація зображень – це лише один складовий елемент широкого спектру досліджень в цій галузі. В той час як вона є важливим аспектом, існують також інші моделі текст-до-X, які відіграють ключову роль у різних застосуваннях. Наприклад, моделі текст-до-відео мають на меті генерувати реалістичні відео на основі заданого текстового вказівника. Ці моделі можуть значно прискорити процес підготовки контенту.
З іншого боку, генерація тексту до 3D стала ключовою технологією в галузі комп’ютерного зору та графіки. Хоча вона все ще знаходиться на своїх початкових стадіях, можливість генерувати реалістичні 3D-моделі за допомогою текстового вводу викликала значний інтерес як від академічних дослідників, так і від фахівців промисловості. Ця технологія має великий потенціал для революціонізації різних галузей, і фахівці з різних галузей пильно стежать за її подальшим розвитком.
“Neural Radiance Fields (NeRF)” – це недавно запропонований підхід, який дозволяє відтворювати високоякісні зображення складних 3D сцен з набору 2D зображень або розрідженого набору 3D точок. Було запропоновано кілька методів поєднання моделей текст-до-3D з NeRF для отримання більш реалістичних 3D сцен. Однак, вони часто стикаються з спотвореннями та артефактами та є чутливими до текстових вказівок та випадкових значень.
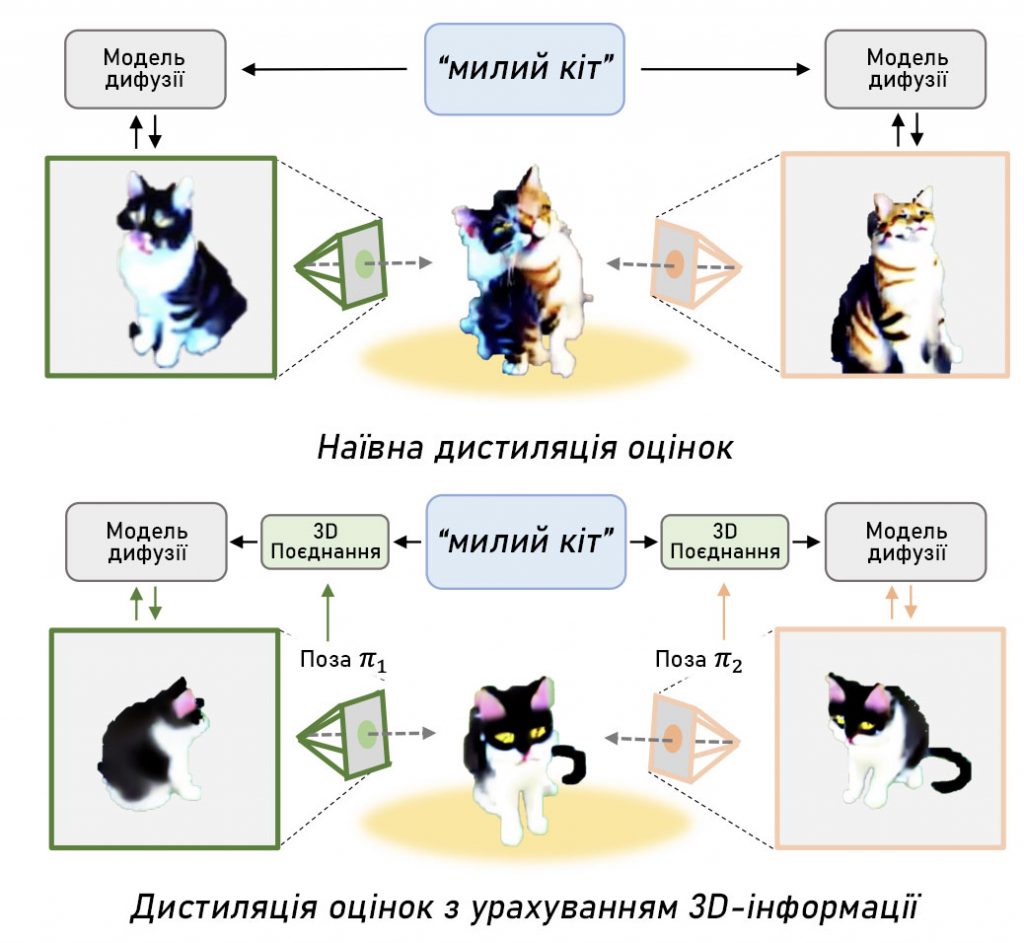
Зокрема, 3D-некогерентність – це поширена проблема, коли відтворені 3D сцени відтворюють геометричні особливості, які належать фронтальному виду, кілька разів з різних точок зору, що призводить до сильних спотворень 3D сцени. Ця помилка виникає через недостатню свідомість 2D моделі дифузії щодо 3D інформації, особливо позиції камери.
Але що, якби був спосіб поєднати моделі текст-до-3D з прогресом в NeRF для отримання реалістичних 3D відтворень? Знайомтесь з 3DFuse.
- Вхідні дані: Пайплайн 3DFuse приймає текстовий ввід, який представляє опис 3D сцени або об’єкта, який потрібно відтворити.
- Текст-до-3D Модель: Перший крок полягає в використанні текст-до-3D моделі, яка перетворює текстовий ввід у відповідний 3D простір. Ця модель створює внутрішній представлення тексту, що враховує геометричні та структурні аспекти об’єктів.
- NeRF Модель: Другий етап використовує модель Neural Radiance Fields (NeRF), щоб отримати високоякісні 3D відтворення з обмеженої кількості 2D зображень або розрідженого набору 3D точок. NeRF модель дозволяє генерувати реалістичні зображення, враховуючи освітлення та тіні.
- 3D Об’єднання: Останній крок полягає в поєднанні результатів з текст-до-3D моделі та NeRF моделі для отримання реалістичних 3D відтворень сцени або об’єкта з текстовим описом.
- Відтворення 3D Сцени: Після завершення пайплайну отримані результати можуть бути використані для відтворення 3D сцени, зображення об’єкта або розширення текстового опису сцени за допомогою візуальних репрезентацій.
3DFuse – це підхід, який поєднує попередньо навчену 2D модель дифузії, наповнену 3D-свідомістю, для того, щоб зробити її придатною для оптимізації 3D-послідовності NeRF. Він ефективно впроваджує 3D-свідомість в попередньо навчені 2D моделі дифузії.
3DFuse починається з вибіркового семантичного коду для прискорення семантичної ідентифікації створеної сцени. Фактично, цей семантичний код є згенерованим зображенням та заданим текстовим вказівником для моделі дифузії. Після завершення цього кроку, модуль впровадження послідовності 3DFuse бере цей семантичний код і отримує карту глибини для конкретної точки зору, проектуючи грубу 3D геометрію для заданої точки зору. Для досягнення цієї карти глибини використовується існуюча модель. Карта глибини та семантичний код потім використовуються для впровадження 3D-інформації в модель дифузії.
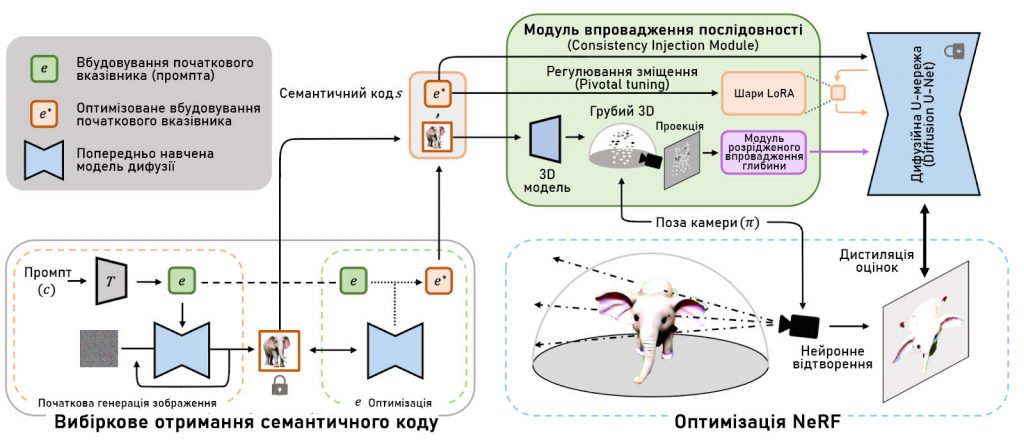
Проблема полягає в тому, що передбачена 3D геометрія піддається помилкам, що може змінити якість створеної 3D моделі. Тому це слід вирішити до продовження роботи у пайплайні. Для вирішення цієї проблеми, 3DFuse вводить розріджений впроваджувач глибини, який неявно знає, як виправити проблематичну інформацію про глибину.
Завдяки дистиляції оцінок моделі дифузії, що виробляє 3D-послідовні зображення, 3DFuse стабільно оптимізує NeRF для послідовної генерації 3D за текстовим вказівником. Ця структура досягає значного покращення порівняно з попередніми роботами як у якості генерації, так і в геометричній послідовності.
)
)
)
)
)
)
)
)
