

09.10.2023 12:49
Чи можемо ми довірити ШІ нанесення водяних знаків?
Стрімкий розвиток генеративного штучного інтелекту відкрив нову еру створення цифрового контенту, але він також несе з собою значні виклики, особливо в ідентифікації та відстеженні контенту, створеного штучним інтелектом. Надреалістичні цифрові медіа, створені штучним інтелектом, викликають занепокоєння щодо дезінформації, шахрайства та їхнього потенціалу для обману і заподіяння шкоди.
Щоб протидіяти зловживанню контентом, створеним штучним інтелектом, нещодавні досягнення в моделях генеративного ШІ зробили необхідним розрізняти автентичні матеріали та матеріали, створені штучним інтелектом. Одним із підходів до вирішення цієї проблеми є нанесення водяних знаків – метод, спрямований на те, щоб відрізнити фотографії, створені штучним інтелектом, від інших джерел. Дослідники з факультету комп’ютерних наук Університету Меріленда вивчали стійкість різних детекторів зображень зі штучним інтелектом, включно з водяними знаками та детекторами підробок на основі класифікаторів.
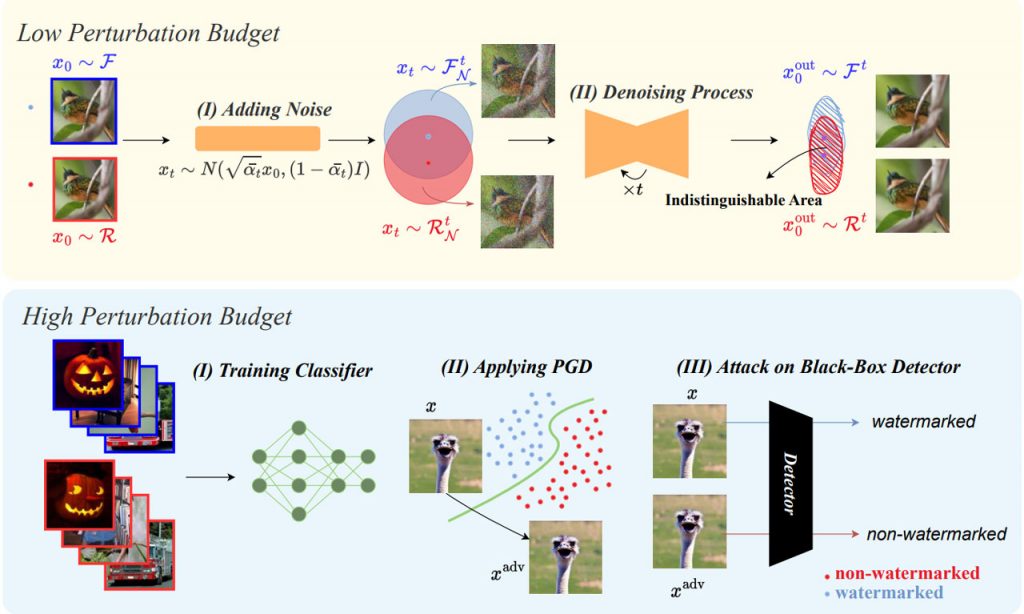
Їхнє дослідження виявило фундаментальний компроміс між частотою помилок ухилення та частотою помилок підробки при використанні методів водяних знаків, які вносять тонкі збурення в зображення. Частота помилок ухилення показує частку зображень з водяними знаками, які помилково визначаються як зображення без водяних знаків, тоді як частота помилок підробки показує частку зображень без водяних знаків, які помилково визначаються як зображення з водяними знаками, коли вони піддаються атаці дифузійного очищення.
Дослідження емпірично продемонструвало, що атака дифузійного очищення може ефективно видаляти водяні знаки із зображень з низькорівневими збуреннями. Зображення, які були незначно змінені методами нанесення водяних знаків, є більш вразливими до цієї атаки. Однак атака дифузійного очищення менш успішна проти методів водяних знаків, які суттєво змінюють зображення. У відповідь на це дослідження пропонує інший тип атаки, який називається атакою підміни моделі, яка може успішно усунути водяні знаки від методів водяного маркування з високим ступенем збурення. Ця атака змушує модель захисту від водяних знаків вважати, що вміст з водяними знаками видалено.
Крім того, дослідження підкреслює вразливість методів нанесення водяних знаків до атак підміни. Під час спуфінг-атаки зловмисник намагається зробити так, щоб реальні зображення, включаючи непристойний або відвертий контент, виглядали так, ніби на них нанесені водяні знаки. Дослідження демонструє, що навіть маючи доступ до технології водяних знаків лише через чорний ящик, зловмисник може згенерувати шумове зображення з водяними знаками. Додавши це шумове зображення до реальних фотографій, зловмисник може позначити їх як такі, що містять водяні знаки, потенційно завдаючи шкоди та підриваючи репутацію авторів фотографій.
Основний внесок цього дослідження можна підсумувати наступним чином:
- Визначення фундаментального компромісу між помилками ухилення та підробки при нанесенні водяних знаків на зображення, особливо при атаках дифузійного очищення.
- Розробка моделі атаки заміщення для ефективного видалення водяних знаків з методів водяного маркування зображень з високим рівнем збурень, які суттєво змінюють оригінальні зображення.
- Виявлення атак підміни методів водяних знаків шляхом введення шумових зображень з водяними знаками до зображень без водяних знаків, що може завдати потенційної шкоди репутації автора.
- Визнання компромісу між стійкістю та надійністю детекторів глибоких підробок.
Отже, це дослідження проливає світло на проблеми та вразливості детекторів зображень зі штучним інтелектом, зокрема методів нанесення водяних знаків, перед обличчям зловмисних атак і поширення контенту, створеного штучним інтелектом. Воно підкреслює важливість постійного розвитку та вдосконалення методів виявлення в епоху генеративного ШІ для ефективного вирішення цих проблем.
)
)
)
)
)
)
)
)
