

02.02.2024 17:08
Що таке GPT?
Генеративний попередньо навчений трансформер (GPT) є свідченням неймовірного прогресу, досягнутого в галузі штучного інтелекту. Розроблений компанією OpenAI у 2018 році, GPT є значною віхою в обробці природної мови (NLP), зробивши революційний прорив у тому, як машини розуміють і генерують людську мову. GPT, що розшифровується як Generative Pre-trained Transformer, — це сімейство великих мовних моделей, які навчаються на величезних обсягах текстових даних, що дозволяє їм виконувати різноманітні завдання.
Що таке генеративний попередньо навчений трансформер?
За своєю суттю GPT — це модель глибокого навчання, заснована на архітектурі трансформерів, нейромережевій архітектурі, яка чудово справляється з обробкою послідовних даних, таких як мова. Особливістю GPT є підхід до попереднього навчання, який передбачає тренування моделі на великих обсягах текстових даних, щоб вивчити тонкощі мови, перш ніж налаштувати її для виконання конкретних завдань. Цей етап попереднього навчання дозволяє GPT розвинути глибоке розуміння синтаксису, семантики та контексту, що дозволяє йому генерувати зв’язний і контекстуально релевантний текст.
Чому GPT є важливим?
Поява моделей GPT, особливо з використанням трансформерної архітектури, відзначила значний прорив у дослідженнях штучного інтелекту. Ці моделі позначають вирішальний момент у широкому впровадженні машинного навчання (ML), оскільки вони пропонують можливість автоматизувати і покращити різноманітні завдання. Моделі GPT демонструють надзвичайну багатофункціональність: від мовного перекладу та узагальнення документів до створення контенту, розробки веб-сайтів, візуального дизайну, анімації, кодування, складних досліджень і навіть написання віршів.
Цінність цих моделей полягає в їхній неперевершеній швидкості та масштабованості. Наприклад, в той час як створення статті з ядерної фізики зазвичай вимагає годин досліджень, написання та редагування, GPT-модель може згенерувати таку статтю за лічені секунди. Така вражаюча ефективність підштовхнула дослідження в галузі штучного інтелекту до створення загального інтелекту, де машини можуть суттєво підвищити продуктивність організації та революціонізувати додатки і досвід клієнтів.
По суті, GPT-моделі є трансформаційною силою в галузі ШІ, яка обіцяє змінити вигляд взаємодії між людиною і машиною та вивести нас на безпрецедентний рівень інновацій та ефективності.
Як працює GPT?
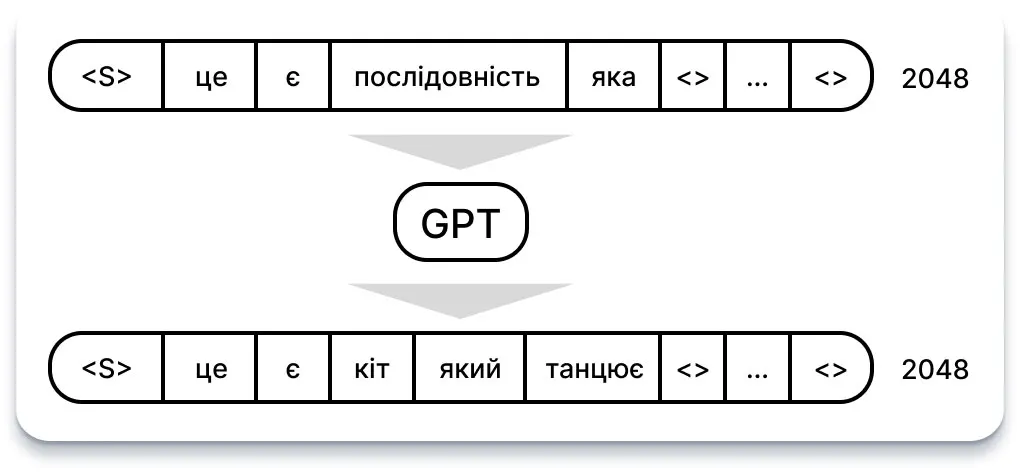
Щоб зрозуміти, як працює GPT, дуже важливо розуміти структуру його вхідних та вихідних даних. Простіше кажучи, на вхід подається послідовність з N слів, також відомих як токени. І навпаки, вихід складається з передбачення слова, яке з найбільшою ймовірністю слідує за вхідною послідовністю.
Введення / виведення

Цей простий механізм вводу-виводу лежить в основі чудових можливостей GPT. Захоплюючі діалоги, захопливі історії або переконливі приклади — все це генерується за цією базовою схемою: ви вводите послідовність слів і отримуєте наступне передбачення слова.
По суті, цей спрощений процес підкреслює потужність і універсальність GPT, дозволяючи йому створювати різноманітні та зв’язні текстові результати на основі наданих вхідних даних.
«Не всі герої носять плащі» — популярна фраза, яка підкреслює ідею, що героїзм може проявлятися в різних формах, виходячи за межі традиційних символів, таких як плащі. У контексті генерації тексту за допомогою таких моделей, як GPT-3, ця фраза ілюструє ітеративний процес передбачення та розширення.
Ось як це працює: Спочатку ми надаємо моделі початкову послідовність, наприклад, «Не всі герої носять плащі». Потім модель прогнозує наступне слово, яке ми додаємо до існуючої послідовності, щоб сформувати новий вхід. Цей процес продовжується ітеративно, з кожним наступним передбаченим словом послідовність розширюється.
Не всі герої носять плащі → але
Не всі герої носять плащі, але → всі
Не всі герої носять плащі, але всі → лиходії
Не всі герої носять плащі, але всі лиходії → носять
Однак є кілька нюансів, які слід врахувати:
Для GPT-3 вхідна послідовність фіксована на рівні 2048 слів. Незважаючи на те, що ми можемо вводити коротші послідовності, решта позицій заповнюються «порожніми» значеннями.
На виході GPT-3 ми отримуємо не просто одну здогадку, а послідовність здогадок, кожна з яких представляє ймовірність ймовірного слова для кожної позиції в послідовності. Однак, генеруючи текст, ми зазвичай зосереджуємося лише на прогнозі для останнього слова в послідовності.
Використовуючи цей ітеративний підхід і розуміючи тонкощі вхідної структури і вихідних здогадок, ми можемо генерувати зв’язний і розгорнутий текст, використовуючи моделі на кшталт GPT-3.
Кодування
Хоча може здатися, що GPT розуміє слова, в основі своєї роботи він оперує числовими векторами. Отже, як нам перевести слова в ці числові представлення?
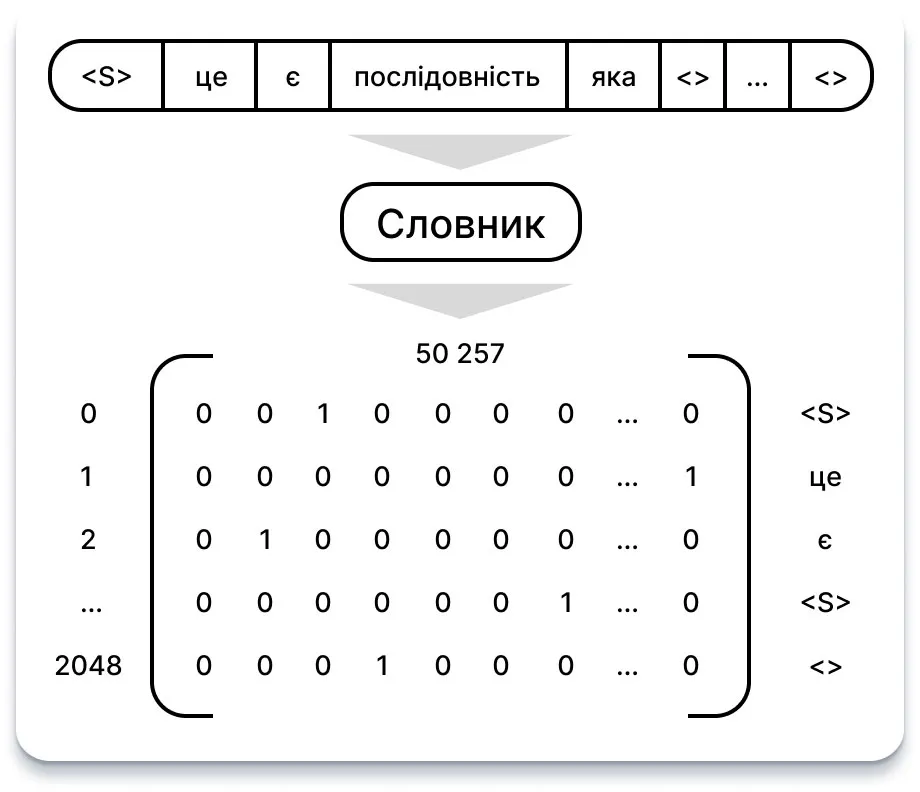
Процес починається з ведення словника всіх слів, що зустрічаються, з присвоєнням кожному слову унікального значення. GPT використовує словник з 50 257 слів.
Отже, кожне слово може бути перетворено у вектор кодування розміром 50 257. У цьому векторі лише розмірність, що відповідає значенню слова, встановлюється в 1, тоді як всі інші розмірності залишаються 0. В результаті отримуємо матрицю 2048 x 50 257, що складається з одиниць та нулів, кожен рядок якої представляє слово у вхідній послідовності.
Однак, з міркувань ефективності, GPT-3 фактично використовує підхід до токенізації диграмного кодування на байтовому рівні. У цьому методі слова у словнику розглядаються не як цілі слова, а як групи символів (або байти), які часто зустрічаються в тексті. Отже, при використанні токенізатора кодування байтових пар на базі GPT-3 фраза на кшталт «Не всі герої носять плащі» розбивається на такі токени, як «не», «всі», «герой», «носити», «плащ» і «<множинне значення>», кожному з яких присвоюється унікальний ідентифікатор у словнику.
Такий підхід до токенізації підвищує ефективність та гнучкість моделі при обробці різноманітних текстових даних. Крім того, інструмент токенізатора OpenAI полегшує вивчення того, як текст розбивається на токени, пропонуючи розуміння процесу токенізації, що лежить в основі.
Вбудовування
Векторний простір, представлений 50 257 вимірами, є досить об’ємним, переважно заповненим нулями, що може призвести до значної неефективності.
Щоб вирішити цю проблему, використовується функція вбудовування: нейронна мережа, призначена для перетворення 50 257 вимірних однократно закодованих векторів у менші n-вимірні вектори дійсних чисел. По суті, ця функція має на меті сконденсувати або спроектувати семантичну інформацію слова в більш компактний простір.
Наприклад, якщо ми виберемо розмірність вбудовування 2, це буде схоже на присвоєння кожному слову певної координати у двовимірному просторі. Крім того, ми можемо уявити, що кожен вимір представляє гіпотетичну властивість, таку як «м’якість» або «шорсткість», де окреме значення кожної властивості однозначно ідентифікує слово.
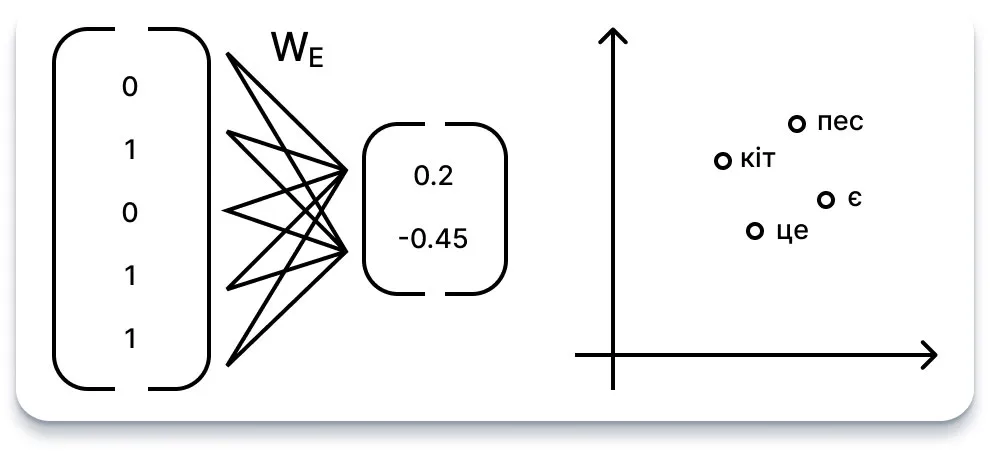
На практиці, кожне слово-вектор множиться на вивчену вагу (WE) мережі вбудовування, однак, розмірність вбудовування, як правило, набагато більша за 2. GPT, наприклад, використовує 12 288 вимірів для своїх вбудовувань.
Ваги контролюють сигнал (або силу зв’язку) між двома нейронами. Іншими словами, вага визначає, наскільки сильно вхідні дані впливатимуть на вихідні.
Процес полягає у множенні кожного вектора закодованого слова розміром 2048 x 50,257 на вивчену матрицю вагових коефіцієнтів вбудовування розміром 50,257 x 12,288. Результатом цього множення є послідовність векторів вбудовування розміром 2048 x 12,288, що ефективно стискає семантичну інформацію кожного слова в більш керований простір.
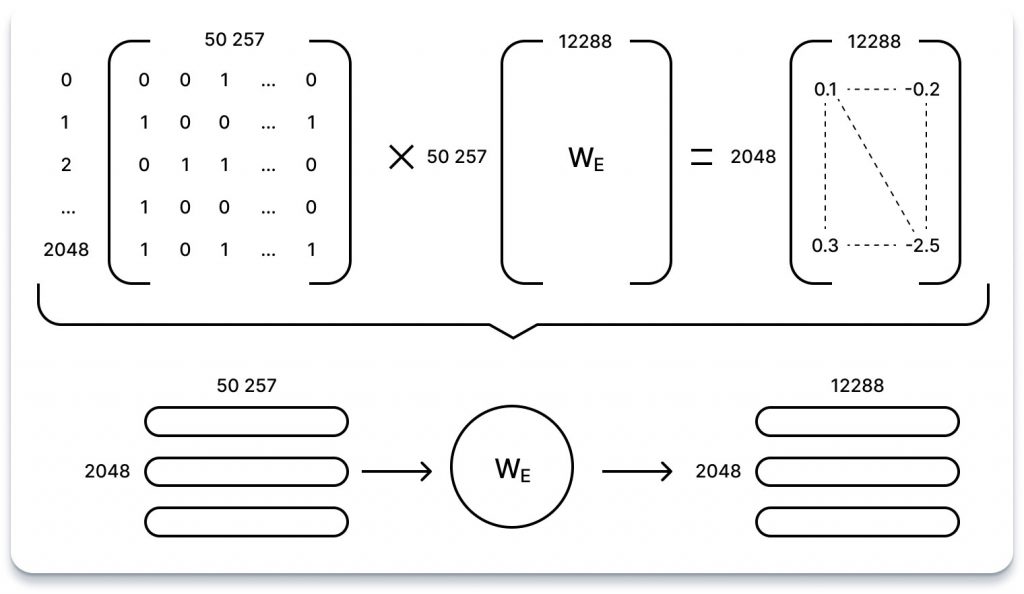
Важливо зазначити, що під час цього процесу кодування кожного слова перетворюється функцією вбудовування окремо, без передачі інформації через послідовність або щодо абсолютного чи відносного положення токенів. Отже, отримані вставки відображають внутрішні властивості окремих слів без урахування їхнього контексту в послідовності.
Позиційне кодування
Щоб включити позиційну інформацію кожного токена в послідовність, використовується унікальний підхід: позиція токена, що представлена у вигляді скалярного значення, пропускається через скалярну функцію i в діапазоні від 0 до 2047, через 12 288 синусоїдальних функцій, кожна з яких має свою частоту.
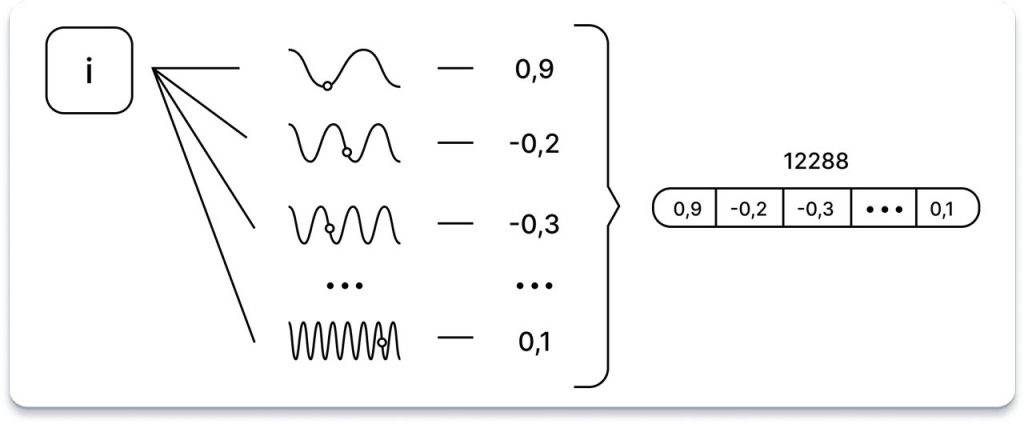
Хоча точне обґрунтування цієї методології може бути не відразу очевидним, але припускається, що вона генерує численні кодування відносного положення, які виявляються корисними для продуктивності моделі. Один із способів концептуалізувати цей вибір — розглянути, як сигнали можуть бути представлені як суми періодичних відліків, як це можна побачити в перетвореннях Фур’є або архітектурах на кшталт мереж SIREN. Крім того, цілком ймовірно, що мові притаманні цикли різної довжини, як, наприклад, у поезії.
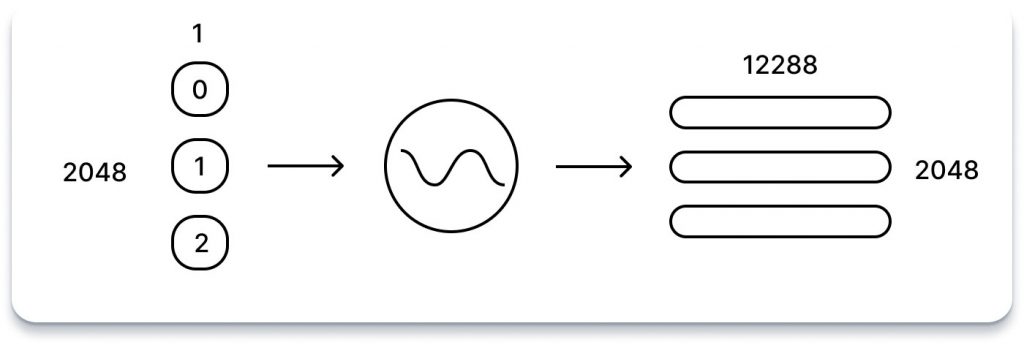
Результатом цього процесу є 12,288-вимірний вектор чисел для кожного токена. Подібно до векторів вбудовування, ці позиційні коди потім об’єднуються в єдину матрицю, що складається з 2,048 рядків, кожен з яких представляє 12,288-вимірне позиційне кодування лексеми в послідовності.
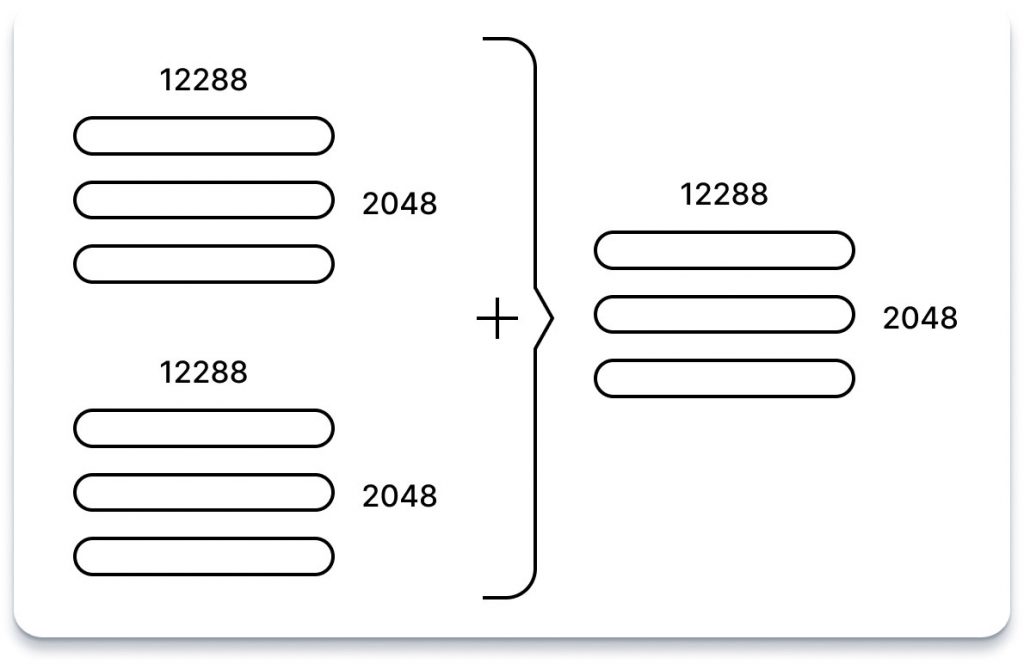
Нарешті, ця матриця позиційних кодів, що відображає форму матриці входжень послідовності, просто додається до неї. Це додавання ефективно інтегрує позиційну інформацію у вбудовування послідовності, дозволяючи моделі краще відображати контекстні зв’язки між токенами в послідовності.
Уважність
По суті, мета уваги полягає в тому, щоб визначити для кожного виходу послідовності, на яких вхідних лексемах слід зосередитися і в якій мірі. Для ілюстрації розглянемо послідовність, що складається з трьох токенів, кожен з яких представлений 512-вимірним вкладом.

Модель проходить навчання, щоб вивчити три різні лінійні проекції, кожна з яких застосовується до вкладок послідовності. Простіше кажучи, отримуються три вагові матриці, які слугують для перетворення вкладених послідовностей у три окремі матриці 3×64, кожна з яких призначена для певної задачі.
Перші дві матриці, які називаються «запити» і «ключі», піддаються множенню (QKt), в результаті чого утворюється матриця 3×3. Ця матриця, нормалізована за допомогою нормалізованої експоненціальної функції (Softmax), позначає значення кожного токена по відношенню до всіх інших токенів.
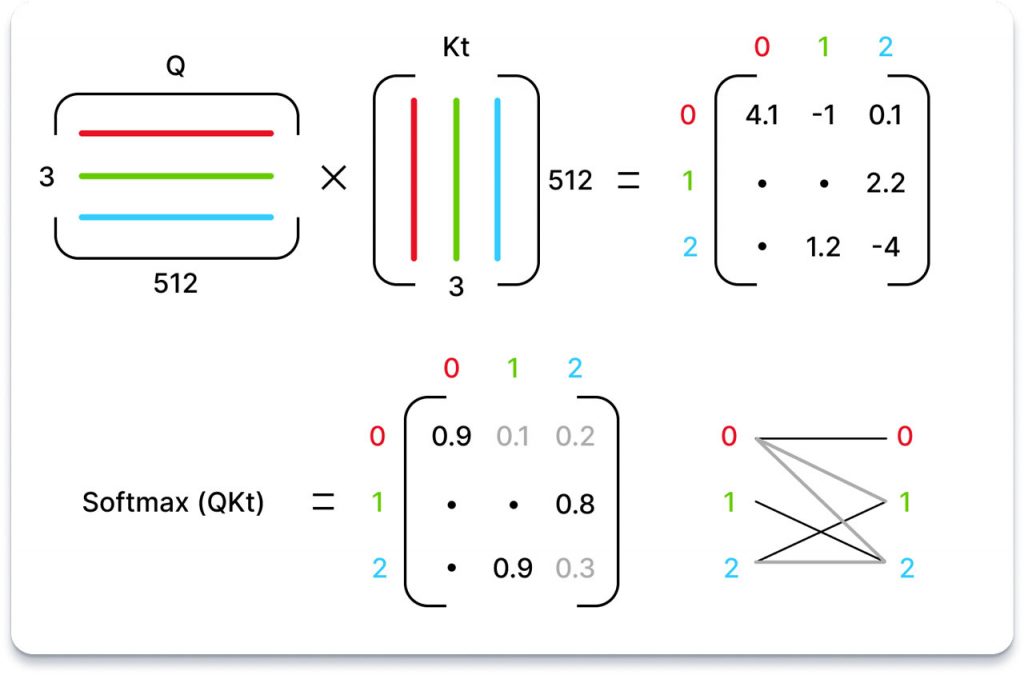
Важливо зазначити, що ця операція (QKt) є єдиним аспектом GPT, де взаємодія відбувається між словами в послідовності. Це єдина операція, де рядки матриці взаємодіють один з одним.
Третя матриця, відома як «значення», потім множиться на цю матрицю важливості. Таким чином, для кожного токена з’являється суміш усіх інших значень токенів, зважених на важливість, приписувану відповідним токенам.
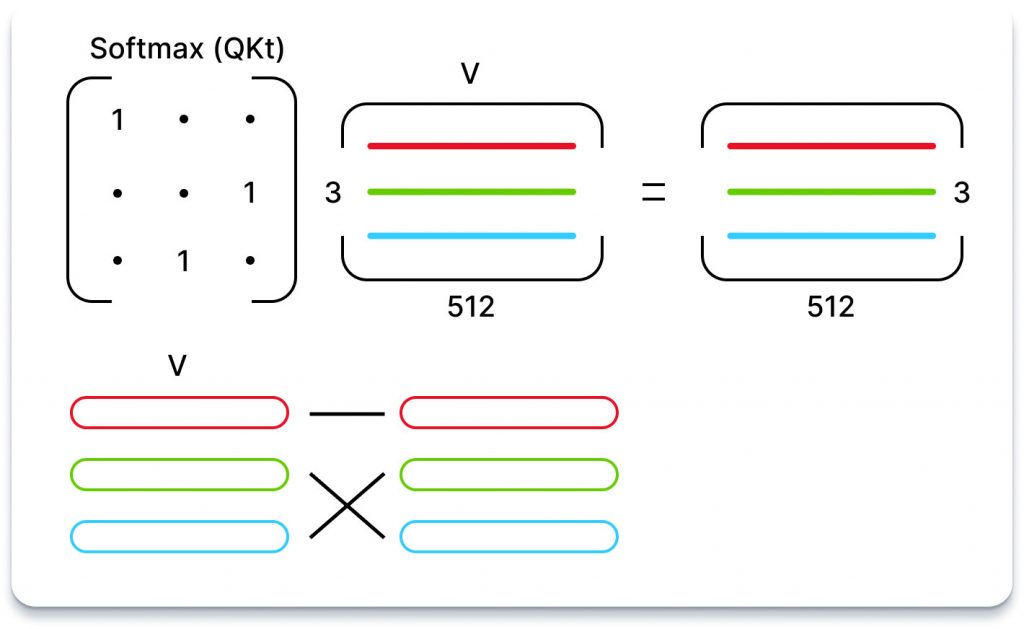
Наприклад, якщо матриця важливості складається лише з одиниць та нулів (що означає, що кожна лексема має лише одну важливу лексему), то результат нагадує вибір рядків у матриці значень на основі найбільш важливої лексеми.
Хоча це пояснення може не повністю прояснити інтуїтивне розуміння процесу уваги, воно проливає світло на точні алгебраїчні операції, що використовуються.
Багатополюсна увага
У моделі GPT використовується багатополюсна увага, що означає, що процес уваги повторюється багато разів (96 разів у випадку GPT-3), причому на кожній ітерації використовуються різні вивчені ваги запиту (Wq), ключа (Wk) та проекції значень (Wv).
Результати роботи кожного напрямку уваги, представлені у вигляді однієї матриці розміром 2048 x 128, об’єднуються разом. Ця конкатенація дає матрицю 2048 x 12288, яка потім проходить додаткову операцію множення на лінійну проекцію (зі збереженням форми матриці). Варто зазначити, що використання розрідженої уваги в GPT-3, спрямоване на підвищення обчислювальної ефективності.
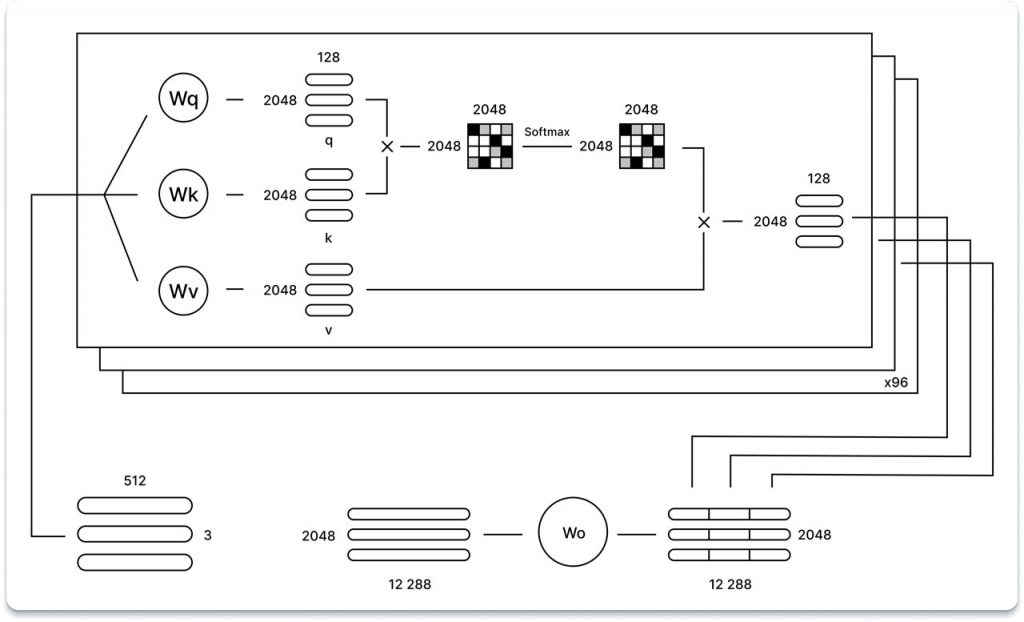
Невеликий нюанс, який слід врахувати, полягає в тому, що хоча ілюстрація пропонує окремі вагові матриці для кожного окремого напрямку, практичні реалізації моделей уваги можуть використовувати єдиний комплексний об’єднаний ваговий тензор для всіх напрямків. У таких випадках множення матриці виконується один раз, а потім результат розбивається на окремі матриці для кожного з напрямків (q, k, v). Однак, з теоретичної точки зору, такий підхід не повинен впливати на результати моделі, оскільки основні алгебраїчні операції залишаються послідовними в обох реалізаціях.
Пряме поширення
Блок прямого зв’язку в архітектурі GPT нагадує традиційний багатошаровий персептрон (MLP) з одним прихованим шаром. Він приймає вхідні дані, виконує множення матриці з вивченими вагами, додає вивчені зсуви, повторює процес і в кінцевому підсумку видає результат.
У цьому блоці форма вхідних та вихідних даних залишається незмінною — 2048 x 12288. Однак прихований шар може похвалитися розміром у 4 рази більшим за 12288.

Ця операція зображена у вигляді кола. На відміну від інших вивчених проекцій в архітектурі (таких як вбудовування, проекції запит/ключ/значення), це «коло» фактично охоплює дві проекції, що виконуються послідовно. Спочатку матриця вивчених ваг множиться на вхідні дані, потім додаються вивчені упередження, і цей процес повторюється. Нарешті, до результату застосовується функція випрямленої лінійної одиниці (ReLU).
Додавання та нормалізація
Після застосування блоків багатополюсної уваги та прямого поширення вхідні дані блоку додаються до його вихідних даних, а результат нормалізується. Ця практика, широко відома як залишковий зв’язок, була поширена в моделях глибокого навчання з часів ResNet.
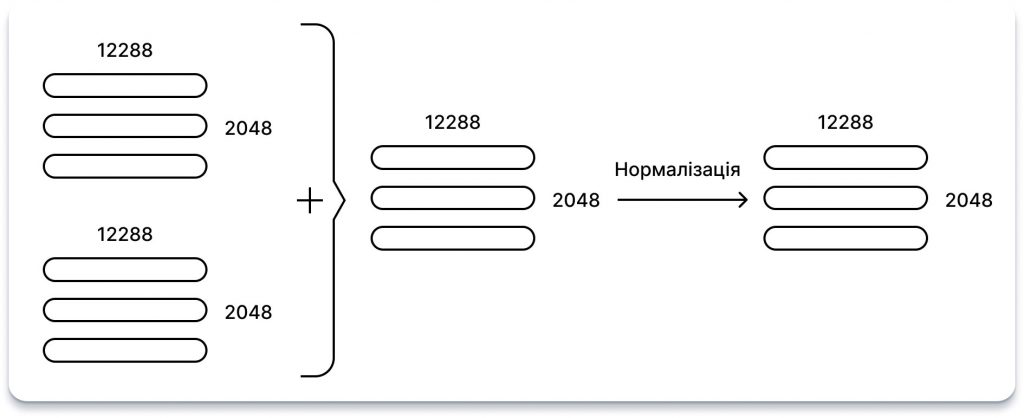
З часів GPT-2 були внесені зміни, зокрема: «Нормалізація шару була перенесена на вхід кожного підблоку, подібно до залишкової мережі до активації, а додаткова нормалізація шару була додана після останнього блоку самоуваги».
Розшифровка
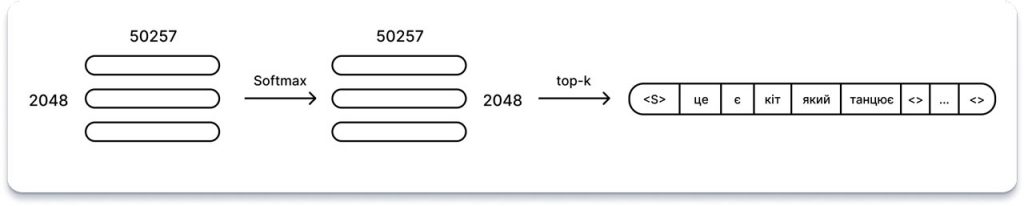
Ми майже на фінішній прямій! Пройшовши через усі 96 рівнів уваги та нейронної мережі GPT-3, вхідні дані були перетворені на матрицю 2048 x 12288. Ця матриця повинна містити для кожної з 2048 вихідних позицій послідовності 12288 векторів інформації про те, яке слово має з’явитися. Але як витягти цю інформацію?
Якщо ви пам’ятаєте, з розділу Вбудовування ми ознайомилися з відображенням, яке перетворює задане (однократне кодування слова) у 12288-векторне вбудовування. Цікаво, що ми можемо обернути це відображення, щоб перетворити вихідне 12288-векторне вбудовування назад у кодування 50257 слів. Це пояснюється тим, що якщо ми вклали значні зусилля у вивчення надійного відображення від слів до чисел, то має сенс використати його знову.
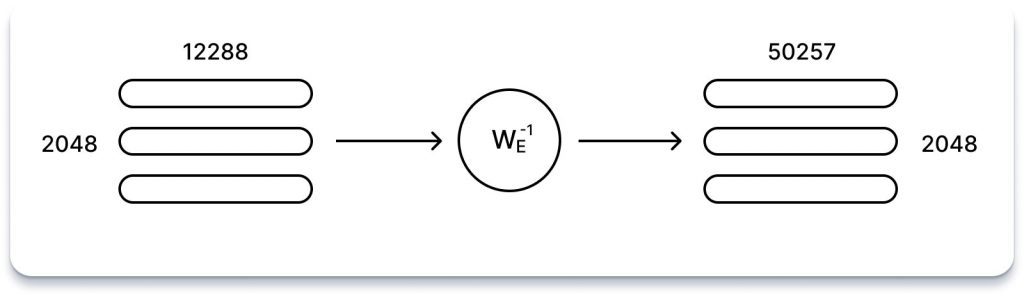
Щоправда, це перетворення не дасть одиниць і нулів, як ми починали, але це навіть корисно: швидка операція з нормалізованою експоненціальною функцією дозволяє нам розглядати отримані значення як ймовірності для кожного слова.
Крім того, в публікаціях GPT вводиться параметр top-k, який обмежує кількість можливих слів для вибірки на виході до k найімовірніших передбачених слів. Наприклад, з параметром top-k, рівним 1, ми завжди вибираємо найбільш ймовірне слово.
Загальна архітектура
Кілька матричних множень, трохи алгебри — і вуаля! Ми створили найсучаснішого гіганта для обробки природної мови. Всі компоненти об’єднані в єдину схему. Операції з навчальними вагами виділено червоним кольором.
Як використовувати GPT?
Можливості застосування моделей GPT продовжують розширюватися з розвитком технологій, ось лише кілька прикладів:
- Написання різних творчих форматів тексту: Моделі GPT можуть створювати текст у різних стилях і форматах — від віршів і сценаріїв до музичних творів і електронних листів, допомагаючи письменникам, музикантам і навіть маркетологам у створенні креативного контенту. Наприклад, GPT-3 було використано для створення пісні «Балада про кролика Роджера» для компанії Disney.
- Машинний переклад: Долаючи мовні бар’єри, моделі GPT перекладають мови з високою точністю і враховують такі нюанси, як ідіоми та культурні особливості. Google Translate і DeepL використовують GPT-моделі для виконання завдань перекладу, покращуючи комунікацію і взаєморозуміння між культурами.
- Чат-боти та віртуальні асистенти: GPT забезпечує роботу чат-ботів, таких як Bard, і віртуальних помічників, таких як Alexa, дозволяючи їм вести природні розмови, розуміти наміри користувача та інформативно відповідати на запитання. Це покращує якість обслуговування клієнтів і надає користувачам легкодоступну інформацію.
- Генерація коду: GPT-моделі можуть аналізувати існуючий код і генерувати нові фрагменти коду, допомагаючи розробникам з повторюваними завданнями і навіть пропонуючи інноваційні рішення на основі вивчених шаблонів. GitHub Copilot використовує Codex від OpenAI, модель на основі GPT, щоб допомогти розробникам писати кращий код.
- Узагальнення тексту: Просіюючи величезні масиви інформації, GPT-моделі можуть конденсувати довгі документи в стислі резюме, заощаджуючи час і зусилля дослідників, студентів і зайнятих професіоналів.
- Персоналізація: Від адаптації новинних стрічок до рекомендацій продуктів, GPT-моделі аналізують вподобання користувачів та їхню взаємодію, щоб створити персоналізований досвід. Це можна побачити на таких платформах, як Netflix або Spotify, які використовують алгоритми рекомендацій на основі GPT-подібних моделей.
- Освіта та навчання: Моделі GPT можуть адаптувати навчальні матеріали до індивідуальних стилів навчання, створюючи персоналізований навчальний досвід і допомагаючи викладачам створювати цікавий контент. Такі інструменти, як Duolingo, використовують GPT-моделі для персоналізованого вивчення мов.
- Дослідження та аналіз даних: Аналізуючи величезні обсяги текстових даних, GPT-моделі можуть виявляти закономірності, тенденції та ідеї, допомагаючи дослідникам у різних галузях, таких як соціальні науки, медицина та фінанси. Наприклад, GPT-моделі можна використовувати для аналізу медичної літератури, щоб швидше ставити діагнози та робити наукові відкриття.
Ключовим підсумком є те, що здатність GPT розуміти і генерувати людську мову відкриває двері до нових можливостей у різних галузях, пропонуючи захоплюючі можливості для творчості, спілкування і пошуку знань.
Висновок
Успіх GPT можна пояснити кількома факторами, зокрема масштабним попереднім навчанням на різноманітних наборах даних, використанням архітектури на основі трансформерів та механізмом самоконтролю, який дозволяє йому вловлювати довготривалі залежності в тексті. Крім того, GPT отримує вигоду від постійного прогресу в дослідженнях штучного інтелекту та апаратних можливостях, що дозволяє йому розширювати межі можливого в розумінні та створенні мови.
Однак, як і будь-яка інша потужна технологія, GPT також піднімає важливі етичні та соціальні питання. Занепокоєння щодо упередженості, дезінформації та можливості зловживання спонукають дослідників і політиків ретельно вивчати наслідки розгортання таких передових систем ШІ. Крім того, питання, пов’язані з конфіденційністю даних, інтелектуальною власністю та підзвітністю, залишаються центральними в постійному дискурсі навколо етики та управління штучним інтелектом.
Незважаючи на всі вищезгадані виклики, GPT є значним досягненням у сфері досліджень і розробок у галузі штучного інтелекту, що демонструє величезний потенціал машинного навчання для трансформації того, як ми взаємодіємо з мовою і розуміємо її. Оскільки дослідники продовжують вдосконалювати можливості GPT, він відіграватиме дедалі помітнішу роль у формуванні майбутнього комунікації, творчості та взаємодії між людиною і машиною.
)
)
)
)
)
)
)
)
