

04.06.2024 18:31
Що таке федеративне навчання (Federated Learning)?
Традиційний підхід до технології штучного інтелекту, який передбачає централізацію величезних обсягів даних для навчання моделей, все ще викликає значні занепокоєння з приводу захисту персональних даних. Федеративне навчання стало перспективним напрямком, який вирішує ці проблеми шляхом децентралізації процесу навчання, підвищуючи тим самим рівень конфіденційності та безпеки.
Тобто, федеративне навчання — це метод навчання моделей штучного інтелекту без розкриття ваших даних або прямого доступу до них, що дає змогу отримувати інформацію для створення нових додатків штучного інтелекту.
Що таке федеративне навчання?
Наші щоденні взаємодії зі штучним інтелектом, від спам-фільтрів до чат-ботів, ґрунтуються на величезних масивах даних, які часто збираються з Інтернету або від користувачів в обмін на цифрові послуги. Традиційно ці дані централізовані і використовуються для навчання моделей штучного інтелекту в одному місці. Тепер же з’являється нова парадигма: федеративне навчання.
Федеративне навчання міняє сценарій навчання моделей на основі великих обсягів даних. Замість того, щоб централізувати інформацію, воно дає можливість окремим пристроям – телефонам, ноутбукам або приватним серверам – спільно навчати моделі ШІ. Цей підхід пропонує вирішальну перевагу: конфіденційність даних. Інформація про користувача ніколи не покидає пристрій, що зменшує занепокоєння щодо зберігання даних і потенційного зловживання ними.
Цей децентралізований підхід стосується не лише конфіденційності. Федеративне навчання розкриває потенціал даних, що генеруються постійно зростаючою мережею датчиків у нашому світі – від супутників і електромереж до розумних пристроїв у наших будинках і на наших тілах. Завдяки локальній обробці даних федеративне навчання може задіяти цей величезний невикористаний ресурс.
Як працює федеративне навчання
Федеративне навчання пропонує новий підхід до навчання потужних моделей штучного інтелекту без шкоди для конфіденційності користувачів. Ось як це працює:
Уявіть, що на центральному сервері зберігається базова модель ШІ, наче рецепт навчання. Потім ця модель поширюється на окремі пристрої, такі як телефони або ноутбуки. Ключовим моментом є те, що дані користувача ніколи не залишають пристрій. Натомість пристрій використовує власні приватні дані для локального навчання моделі. Уявіть собі, що пристрій вносить власні вдосконалення в рецепт на основі своїх унікальних інгредієнтів.
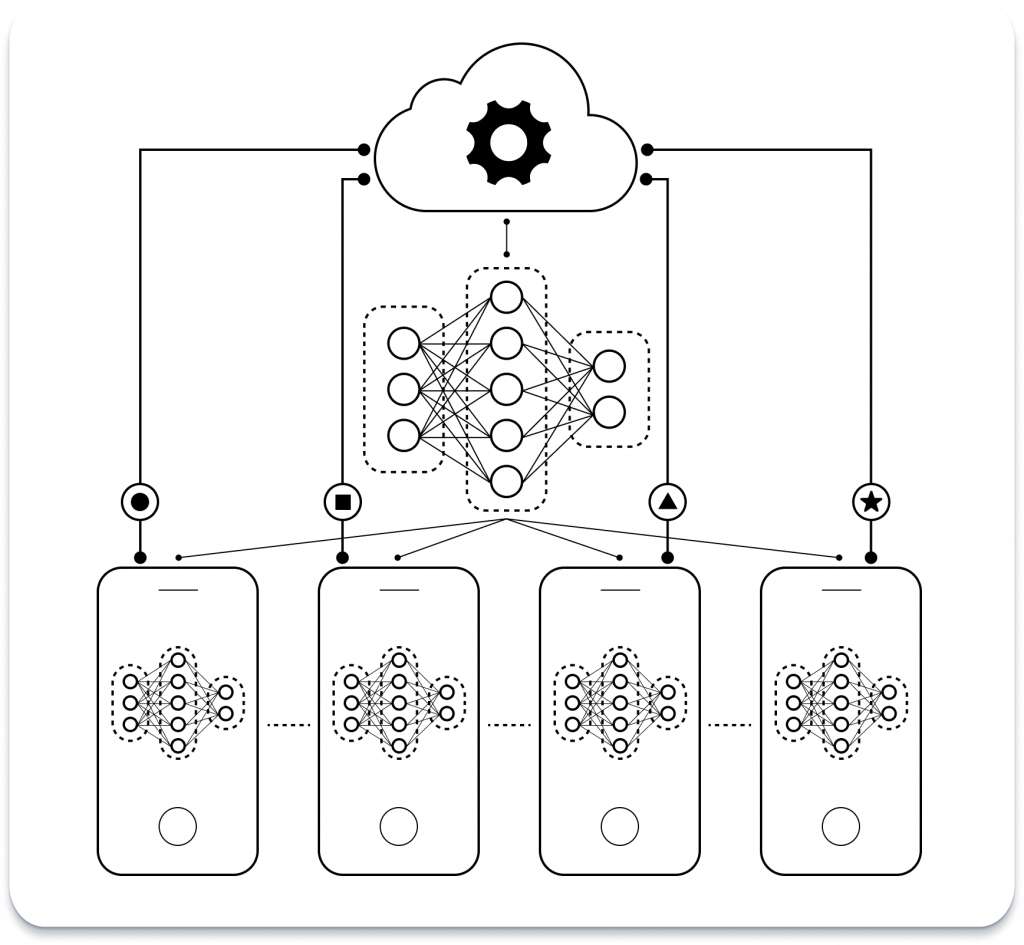
Після цього локального навчання пристрій не надсилає весь свій набір даних, а лише ті покращення, які він вніс до оригінальної моделі. Ці оновлення крихітні порівняно з початковими даними. Потім центральний сервер збирає ці оновлення з багатьох пристроїв і об’єднує їх, по суті, об’єднуючи всі дані, щоб створити кращу модель. Ця вдосконалена модель потім надсилається назад на окремі пристрої для ще одного раунду локального навчання. Цей цикл повторюється, ітеративно вдосконалюючи модель, при цьому вихідні дані не повинні залишати пристрої.
Математичне формулювання для федеративного навчання
Федеративне навчання передбачає спільне навчання глобальної моделі на локальних наборах даних, що знаходяться на різних пристроях. Ось спрощене математичне представлення:
Цільова функція:
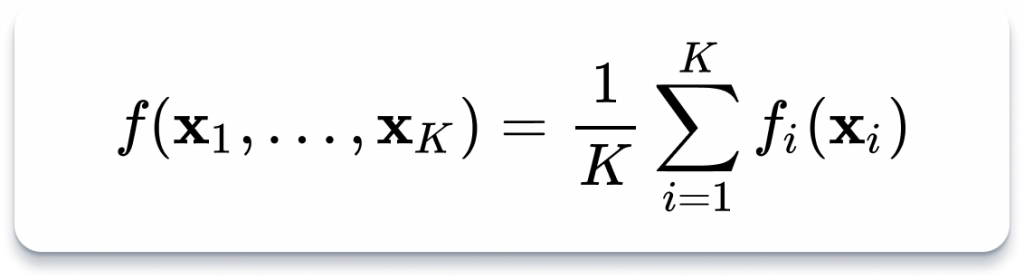
де 𝐾 — кількість вузлів, 𝑥𝑖 — вага моделі з точки зору вузла 𝑖, і 𝑓𝑖 — локальна цільова функція вузла 𝑖, яка описує, як ваги моделі 𝑥𝑖 відповідають локальному набору даних вузла 𝑖.
Задача оптимізації:

де 𝑛 — загальна кількість точок даних, 𝐹𝑖(𝑥) — похибка між точною та передбачуваною мітками точки даних 𝑖, а 𝑥 — параметри моделі.
Розподілена оптимізація:

де 𝑓𝑘(𝑥) — середній збиток кожного клієнта 𝑘, а 𝑛𝑘 — кількість точок даних, що належать клієнту 𝑘
Метою федеративного навчання є розв’язання оптимізаційних задач без обміну даними між агентами. Зазвичай це досягається за допомогою ітеративних процесів, що включають клієнт-серверну взаємодію, де локальні моделі тренуються на кожному вузлі, а потім агрегуються для формування глобальної моделі.
Виклики федеративного навчання
Федеративне навчання пропонує перспективний шлях для розвитку ШІ, який поважає конфіденційність користувачів. Однак воно супроводжується низкою перешкод, які необхідно подолати:
Накладні витрати на комунікацію: Безперервна передача оновлень моделі може створювати навантаження на ресурси. Пристрої з обмеженою пропускною здатністю можуть відчувати на собі цей вплив, що перешкоджає їхній участі та потенційно сповільнює процес навчання.
Не-IID дані: IID (незалежні та ідентично розподілені) дані ідеально підходять для навчальних моделей. У федеративному навчанні дані знаходяться на окремих пристроях і можуть суттєво відрізнятися. Уявіть, що ви навчаєте модель розпізнавати котів – на одному пристрої можуть бути переважно зображення пухнастих домашніх котів, а на іншому – дані із заповідника, де живуть леви й тигри. Така нерівномірність розподілу даних між пристроями може ускладнити процес навчання і призвести до неоптимальних моделей.
Ризики конфіденційності: Хоча федеративне навчання зберігає необроблені дані на пристроях, сам процес навчання не є повністю безризиковим. Зловмисники можуть скористатися вразливостями, щоб отримати інформацію про навчальні дані через оновлення моделі. Крім того, існує ймовірність порушення конфіденційності під час накопичення оновлень моделі на центральному сервері.
Загрози безпеці: Федеративні системи навчання вразливі до різних загроз безпеці. Зловмисники можуть ввести отруєні оновлення, щоб маніпулювати навчанням моделі, або отримати несанкціонований доступ до центрального сервера, щоб порушити процес навчання.
Чесність і підзвітність: Оскільки дані зберігаються на пристроях, забезпечити чесність і підзвітність у навчальному процесі може бути складно. Упередження, присутні в локальних наборах даних, можуть посилюватися під час навчання, що призводить до створення моделей, які увічнюють дискримінацію. Крім того, важко визначити джерело помилок або упереджень, якщо модель працює погано.
Обмежений контроль і прозорість: Розподілена природа федеративного навчання ускладнює централізований моніторинг і контроль навчального процесу. Важко відстежити внесок окремих пристроїв або забезпечити якість і цілісність локальних навчальних даних.
Підходи до федеративного навчання
Концепція федеративного навчання, яка пропонує шлях до розробки ШІ із збереженням конфіденційності, покладається на центральний сервер для координації процесу навчання. Цей централізований аспект може бути ідеальним не для всіх сценаріїв. Тут на допомогу приходять децентралізовані підходи до навчання:
Пірінгове навчання (P2P): Пристрої безпосередньо обмінюються оновленнями моделей один з одним, усуваючи потребу в центральному сервері. Такий підхід сприяє створенню більш розподіленого і потенційно більш безпечного середовища. Однак управління зв’язком між пристроями та забезпечення ефективного прогресу в навчанні може виявитися досить складним.
Навчання на основі блокчейну: Технологія блокчейн, відома своїм безпечним і прозорим управлінням даними, може бути використана у федеративному навчанні. Кожне оновлення моделі може бути записане до блокчейну, що забезпечить захист навчання від несанкціонованого втручання і потенційно сприятиме зміцненню довіри та співпраці між його учасниками. Виклики включають накладні витрати на обчислення, пов’язані з операціями на блокчейні, і потенційні проблеми масштабування навчання.
Ройове навчання: Натхненне поведінкою роїв у природі, ройове навчання дозволяє пристроям спільно навчати модель без центрального координатора. Пристрої спілкуються з найближчими сусідами, обмінюючись та агрегуючи оновленнями моделі. Цей підхід пропонує високу масштабованість і стійкість до збоїв, але може бути складно забезпечити конвергенцію (досягнення оптимального стану моделі) і ефективні схеми комунікації.
Федеративне мета-навчання: Цей підхід фокусується на навчанні центральної «мета-моделі», яка може ефективно навчатися на різних локальних наборах даних. Пристрої можуть завантажувати мета-модель і використовувати її для локального навчання на власних даних, що зменшує накладні витрати на зв’язок порівняно з традиційним федеративним навчанням. Однак розробка надійних алгоритмів метанавчання залишається активною сферою досліджень.
Ці децентралізовані підходи до навчання пропонують такі потенційні переваги, як підвищена конфіденційність, покращена безпека та більша масштабованість. Однак, вони також несуть з собою власний набір проблем, над вирішенням яких активно працюють дослідники. Оскільки федеративне навчання продовжує розвиватися, інтеграція методів децентралізованого навчання може повністю розкрити свій потенціал для безпечної розробки ШІ із збереженням конфіденційності.
Майбутнє федеративного навчання
Федеративне навчання може змінити спосіб навчання та впровадження штучного інтелекту. На відміну від традиційних методів, які централізують величезні обсяги даних, метод федеративного навчання зберігає дані, розподілені на окремих пристроях або серверах. Це пропонує цікаве рішення: використання колективної потужності цих децентралізованих даних для вдосконалення моделей ШІ, забезпечуючи при цьому конфіденційність користувачів.
Однією з ключових сфер майбутнього розвитку федеративного навчання є його здатність навчати великі мовні моделі (LLM). Для ефективного навчання LLM потрібно мати величезні набори даних. Федеративне навчання може розкрити потенціал джерел даних, які в даний час недостатньо використовуються, що призведе до створення ще більш потужних і деталізованих мовних моделей.
Крім того, федеративне навчання відкриває двері для ширшої співпраці в розробці ШІ. Такі установи, як лікарні, можуть навчати ШІ-моделі для медичної діагностики, не ставлячи під загрозу конфіденційні дані пацієнтів. Аналогічно, компанії можуть розробляти галузеві рішення на основі штучного інтелекту, об’єднуючи дані з різних організацій.
Однак проблеми залишаються. Забезпечення надійних протоколів зв’язку та заходів безпеки матиме вирішальне значення для широкого впровадження федеративного навчання. Крім того, вирішення проблем, пов’язаних з чесністю і потенційним витоком даних у федеративних системах, вимагає постійних досліджень і розробок.
Попри всі ці перешкоди, майбутнє федеративного навчання є світлим. В міру того, як технологія розвивається і її переваги стають все більш очевидними, ми можемо очікувати, що федеративне навчання відіграватиме центральну роль у формуванні наступного покоління додатків штучного інтелекту, орієнтованих на конфіденційність. Від охорони здоров’я до фінансів і персоналізованого користувацького досвіду, федеративне навчання має потенціал для трансформації багатьох секторів, одночасно сприяючи створенню більш безпечного і спільного ландшафту штучного інтелекту.
)
)
)
)
)
)
)
)
