

28.03.2024 13:13
Hugging Face представила Cosmopedia
Розробка синтетичних наборів даних для навчання ШІ-моделей зазнала значного прогресу, особливо з появою таких інструментів, як Phi-моделі від Microsoft і Cosmopedia від дослідників з Hugging Face. Ці синтетичні набори даних відіграють вирішальну роль у забезпеченні великомасштабних, різноманітних і високоякісних даних для навчання ШІ-моделей, долаючи обмеження і проблеми, пов’язані з людьми-анотаторами.
Phi-моделі, зокрема Phi-2, набули популярності завдяки використанню синтетичних даних для навчання моделей ШІ із застосуванням новітніх методів. Вони продемонстрували вищу продуктивність порівняно з моделями, що навчаються на традиційних наборах веб-даних, демонструючи потенціал синтетичних даних у розробці ШІ.
Cosmopedia представляє собою новий підхід до створення синтетичних наборів даних, зосереджуючись на широкому спектрі тем і джерел, щоб забезпечити різноманітність і якість. Поєднуючи перевірені джерела та веб-дані, Cosmopedia змогла створити понад 30 мільйонів підказок на різні теми, з акцентом на освітню цінність та навчальний контент.
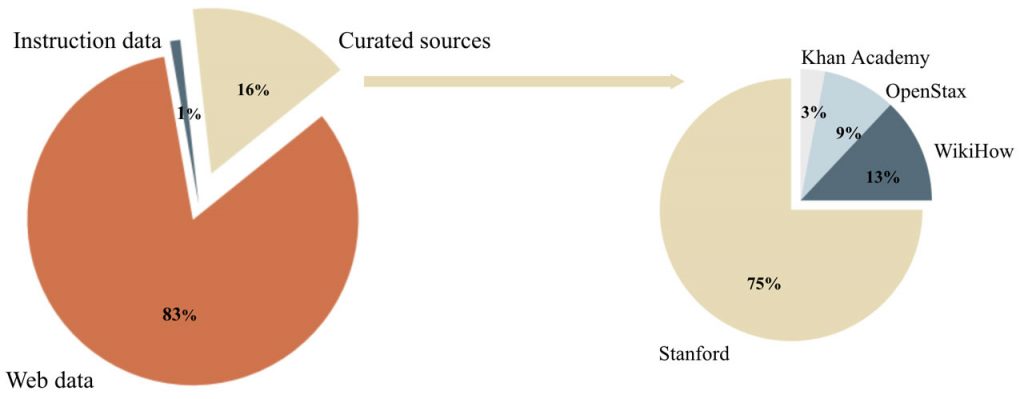
Методологія, яку застосовують дослідники Cosmopedia, включає в себе ретельний процес курації даних, кластеризації тем і генерації підказок. Вони використовують надійні освітні ресурси для курації контенту та використовують веб-дані для масштабування. Такий гібридний підхід гарантує, що згенеровані підказки будуть не лише різноманітними, але й релевантними та інформативними.
Крім того, команда розробників Космопедії впровадила методи дезактивації, дедуплікації та токенізації даних, щоб забезпечити якість і цілісність набору даних. Це включає видалення забруднених зразків і порівняння набору даних з різними оціночними метриками для оцінки його продуктивності.
З точки зору оцінки, Cosmopedia показала багатообіцяючі результати, перевершивши деякі моделі в таких бенчмарках, як MMLU, ARC-easy, OpenBookQA і ARC-challenge. Хоча в деяких областях вона може не зрівнятися з Phi-1.5, загальна якість і різноманітність синтетичних даних, згенерованих Cosmopedia, заслуговує на визнання.
Отже, синтетичні набори даних, такі як Cosmopedia, є помітним кроком вперед у розвитку ШІ, надаючи дослідникам і розробникам цінні ресурси для навчання і доопрацювання моделей ШІ. Оскільки ці методи продовжують еволюціонувати, ми можемо очікувати подальшого вдосконалення можливостей і застосувань штучного інтелекту в різних галузях.
)
)
)
)
)
)
)
)
