

26.07.2023 09:05
Модулювання попередньо навчених дифузійних моделей для синтезу мультимодальних зображень
Моделі штучного інтелекту, що генерують зображення, штурмують простір за останні кілька місяців. Ці моделі здатні генерувати фотореалістичні зображення за заданими підказками, незалежно від того, наскільки дивними є ці підказки. Хочете побачити, як Пікачу бігає Марсом? Вперед, попросіть одну з цих моделей зробити це для вас, і ви це отримаєте.
Існуючі моделі дифузії покладаються на великомасштабні навчальні дані. Коли ми говоримо “великі”, ми маємо на увазі дійсно великі.Наприклад, сама Stable Diffusion була навчена на більш ніж 2,5 мільярдах пар зображень і підписів. Отже, якщо ви планували навчити власну модель дифузії в домашніх умовах, можливо, вам варто переглянути це рішення, оскільки навчання цих моделей є надзвичайно дорогим з точки зору обчислювальних ресурсів.
З іншого боку, існуючі моделі зазвичай є безумовними або обумовленими абстрактним форматом, наприклад, текстовими підказками. Це означає, що вони беруть до уваги лише одну річ при створенні зображення, і неможливо передати зовнішню інформацію, таку як карта сегментації. Поєднання цього з залежністю від великих наборів даних означає, що великомасштабні моделі генерації обмежені в застосуванні в областях, де ми не маємо великого набору даних для навчання.
Одним з підходів до подолання цього обмеження є точне налаштування попередньо навченої моделі для конкретної області. Однак це вимагає доступу до параметрів моделі та значних обчислювальних ресурсів для розрахунку градієнтів для повної моделі. Крім того, точне налаштування повної моделі обмежує її застосовність і масштабованість, оскільки для кожної нової області або комбінації модальностей потрібні нові повнорозмірні моделі.Крім того, через великий розмір цих моделей, вони мають тенденцію швидко підлаштовуватися під меншу підмножину даних, на яких вони були точно налаштовані.
Також можна навчати моделі з нуля, залежно від обраної модальності. Але знову ж таки, це обмежується наявністю навчальних даних, а навчання моделі з нуля є надзвичайно дорогим. З іншого боку, люди намагалися спрямувати попередньо навчену модель під час виведення до бажаного результату. Вони використовують градієнти з попередньо навченого класифікатора або CLIP-мережі, але такий підхід сповільнює вибірку моделі, оскільки додає багато обчислень під час виведення.
Що, якби ми могли використовувати будь-яку існуючу модель і адаптувати її до наших умов, не вдаючись до надзвичайно дорогого процесу? Що, якби ми не вдавалися до громіздкого і тривалого процесу зміни режиму дифузії? Чи можна було б його все одно обумовити? Відповідь – так, і дозвольте мені представити її вам.

Запропонований підхід, мультимодальні модулі кондиціонування (MCM), є модулем, який можна інтегрувати в існуючі дифузійні мережі. Він використовує невелику дифузійну мережу, яка навчається модулювати прогнози вихідної дифузійної мережі на кожному кроці дискретизації таким чином, щоб згенероване зображення відповідало заданим умовам.
MCM не вимагає ніякого навчання вихідної дифузійної моделі. Навчається лише модулююча мережа, яка є маломасштабною і її навчання не є дорогим. Цей підхід є обчислювально ефективним і вимагає менше обчислювальних ресурсів, ніж навчання дифузійної мережі з нуля або точне налаштування існуючої дифузійної мережі, оскільки він не вимагає обчислення градієнтів для великої дифузійної мережі.
Більше того, MCM добре узагальнює навіть тоді, коли ми не маємо великого набору навчальних даних. Він не сповільнює процес виведення, оскільки немає градієнтів, які потрібно обчислювати, і єдині обчислювальні витрати пов’язані з роботою з малою дифузійною сіткою.
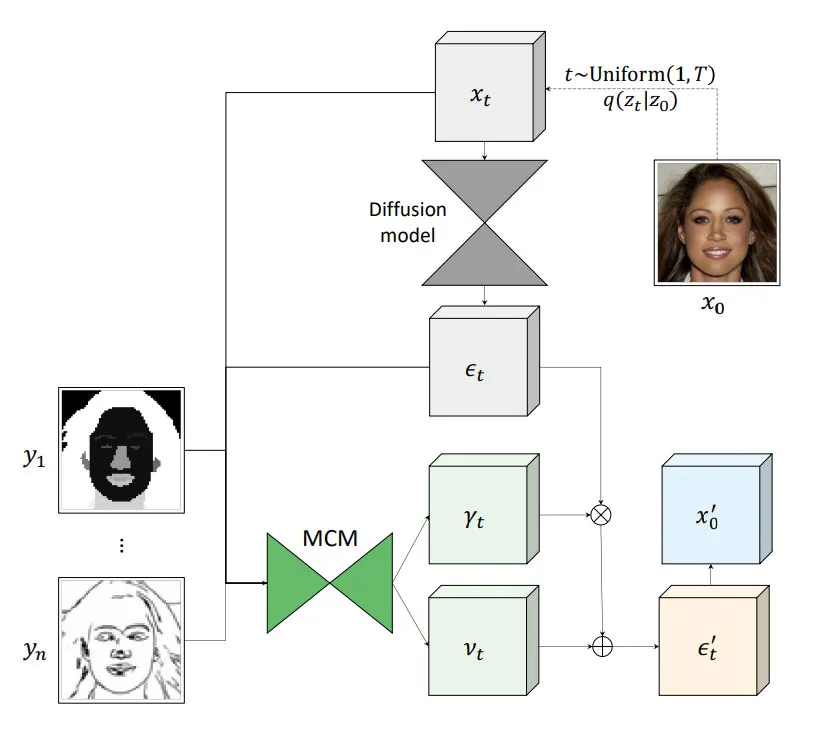
Включення модуля мультимодального кондиціювання додає більше контролю над генерацією зображень завдяки можливості обумовлювати додаткові модальності, такі як карта сегментації або ескіз. Основний внесок підходу полягає у впровадженні модулів мультимодального кондиціонування – методу адаптації попередньо навчених моделей дифузії для умовного синтезу зображень без зміни параметрів вихідної моделі, що дозволяє отримати якісні та різноманітні результати, при цьому коштує дешевше і використовує менше пам’яті, ніж навчання з нуля або точне налаштування великої моделі.
)
)
)
)
)
)
)
)
