

24.10.2023 15:51
Нова безтренувальна та теоретико-ігрова процедура ШІ для декодування мовних моделей
Деякі завдання, пов’язані зі створенням або перевіркою фактичних тверджень, такі як відповіді на запитання, перевірка фактів і генерація безумовного тексту, досить добре виконуються сучасними мовними моделями. Тим не менш, все більше фактів свідчить про те, що зі збільшенням розміру мовних моделей вони стають більш схильними до генерації помилкових, але часто повторюваних тверджень. Вони далекі від того, щоб бути повністю надійними. Складність полягає в тому, що лінгвістичні моделі мають багато можливостей для вирішення завдань генерації фактів.
Мовні моделі можуть слугувати як генеративно (надаючи найбільш вірогідну відповідь на питання), так і дискримінативно (представляючи пару “питання-відповідь” та оцінюючи прийнятність відповіді). Однак ці два підходи іноді дають суперечливі результати. Генеративні методи можуть помилятися, коли ймовірність розподілена між кількома суперечливими відповідями, тоді як дискримінантні методи можуть зазнати невдачі через неправильне калібрування або тонкі залежності між питаннями. Як ми можемо отримати найточнішу оцінку істинності мовної моделі з цих хаотичних і часто суперечливих вхідних даних?
У цьому дослідженні, проведеному вченими з Массачусетського технологічного інституту (MIT), гра консенсусу, сигнальна гра, використовується як метод для поєднання генеративного та дискримінативного процесів декодування мовних моделей. Агент-дискримінатор повинен передати високорівневе абстрактне значення правильності агенту-генератору, але він обмежений обмеженою кількістю можливих виразів природної мови. Цілком логічно, що спільна політика, в якій генератор і дискримінатор досягають консенсусу щодо присвоєння значень правильності виразам, була б успішною стратегією для цієї гри. Вони досліджують такий підхід для визначення кандидатів, які, на думку всіх, є правильними. Розв’язання цієї багатокрокової гри зі складним простором дій, що включає вирази природної мови, вимагає використання алгоритмів навчання без жалю. Ці алгоритми набули популярності для визначення оптимальних стратегій у різних іграх, включаючи покер, стратегію та дипломатію.
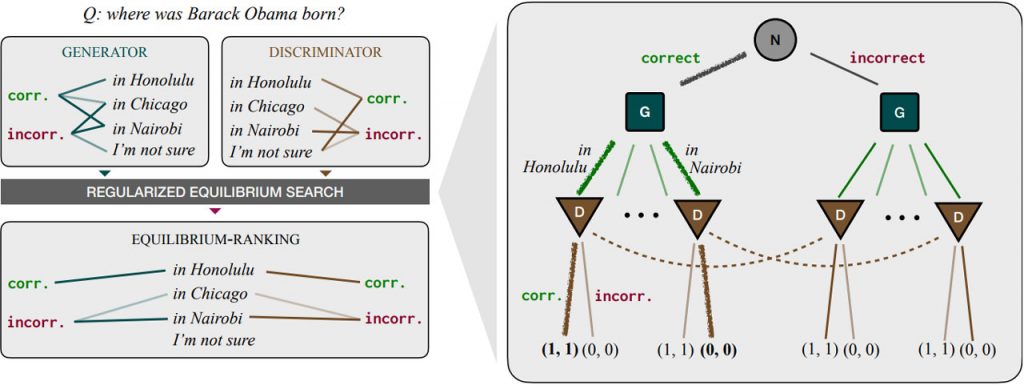
Метод декодування мовних моделей, заснований на теорії ігор, називається рівноважним ранжуванням (Equilibrium Ranking). Будучи застосованим до шести бенчмарків (MMLU, ARC, RACE, HHH, TruthfulQA та GSM8K), рівноважне ранжування перевершує сучасні генеративні, дискримінантні та змішані методи декодування. У ширшому контексті, це дослідження показує, як інструменти теорії ігор можуть бути використані для формалізації та покращення зв’язності мовних моделей, що призводить до підвищення точності у фактичних задачах.
)
)
)
)
)
)
)
)
