

23.10.2023 11:21
Точне налаштування ШІ в 10 разів зменшує кількість параметрів, що піддаються навчанню
Оскільки сфера застосування програм обробки природної мови продовжує розширюватися, зростає попит на моделі, здатні розуміти і діяти відповідно до конкретних інструкцій з мінімальними обчислювальними ресурсами і пам’яттю. Це дослідження розглядає обмеження існуючих методів і представляє новий підхід під назвою VeRA, покликаний значно покращити процеси налаштування інструкцій.
Мовні моделі часто стикаються з труднощами, пов’язаними з пам’яттю та обчисленнями, що знижує їхню ефективність у застосуванні в умовах реального світу. Щоб вирішити цю проблему, дослідники представили VeRA – новий підхід, який дозволяє моделі Llama2 7B ефективно виконувати інструкції, використовуючи лише 1,4 мільйона параметрів, що піддаються навчанню. Це суттєвий прогрес порівняно з попереднім методом LoRA, який вимагав набагато більшої кількості параметрів – 159,9 мільйона з рангом 64. Помітне зменшення кількості параметрів при збереженні продуктивності підкреслює ефективність і перспективність методу VeRA.
Успіх VeRA можна пояснити його всеосяжною стратегією точного налаштування, яка в першу чергу фокусується на всіх лінійних шарах, за винятком верхнього шару. Крім того, використання методів квантування для навчання на одному графічному процесорі та використання очищеної версії набору даних Alpaca відіграли ключову роль у демонструванні можливостей VeRA. Дослідницька група провела навчання на підмножині з 10 000 зразків з набору даних Alpaca, перед цим провівши велику перевірку швидкості навчання для забезпечення оптимальної продуктивності. Такий ретельний підхід до відбору даних і методології навчання підкреслює надійність результатів дослідження.
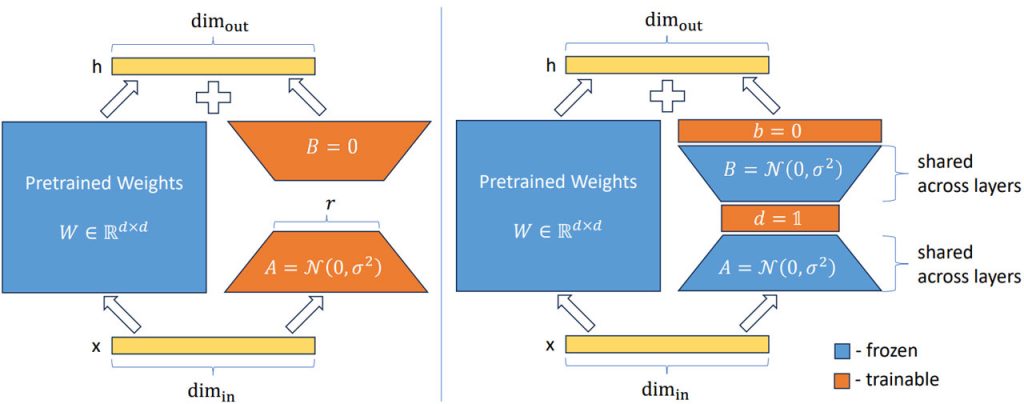
На етапі оцінювання дослідницька група застосувала підхід, що передбачав генерування модельних відповідей на заздалегідь визначений набір із 80 запитань та оцінювання цих відповідей за допомогою GPT-4. Отримані дані свідчать про вищу ефективність VeRA, на що вказують вищі загальні бали порівняно з традиційним підходом LoRA. Це значне досягнення підкреслює ефективність VeRA у покращенні здатності виконувати інструкції, зберігаючи при цьому ефективність.
Вплив VeRA виходить за межі його безпосереднього застосування, означаючи зміну концепції налаштування інструкцій та оптимізації мовної моделі. Завдяки значному зменшенню кількості параметрів, що піддаються навчанню, VeRA ефективно усуває критичне вузьке місце в застосуванні мовних моделей, прокладаючи шлях до більш ефективних і доступних послуг зі штучного інтелекту. Цей прорив має величезний потенціал для різних галузей і секторів, які покладаються на рішення на основі ШІ, пропонуючи практичний і дієвий підхід до налаштування інструкцій для різноманітних застосувань.
Отже, впровадження методу VeRA є важливою віхою в еволюції мовних моделей і методів налаштування навчання. Його успіх демонструє потенціал досягнення оптимальної продуктивності з мінімальними вимогами до обчислень і пам’яті. Оскільки попит на ефективні та практичні рішення у сфері ШІ продовжує зростати, VeRA свідчить про постійний прогрес у дослідженнях ШІ та його здатність трансформувати різні галузі та сектори. Висновки дослідницької групи знаменують собою значний крок вперед у пошуках більш доступних і спрощених рішень для ШІ, створюючи основу для майбутніх інновацій і розробок в області обробки природної мови і методів налаштування інструкцій.
)
)
)
)
)
)
)
)
