

01.10.2023 17:33
InternLM-20B: 20-мільярдний ШІ фреймворк з відкритим вихідним кодом
У галузі обробки природної мови, що стрімко розвивається, дослідники постійно прагнуть розробити моделі, здатні розуміти, міркувати та генерувати текст, як людина. Ці моделі повинні враховувати складні лінгвістичні нюанси, заповнювати мовні прогалини та адаптуватися до різноманітних завдань. Однак традиційні мовні моделі з обмеженою глибиною та навчальними даними часто не відповідають цим очікуванням. Щоб вирішити ці проблеми, дослідницька спільнота представила InternLM-20B, нову модель з 20 мільярдами параметрів для попереднього навчання.
InternLM-20B являє собою значний стрибок в архітектурі мовної моделі та якості навчальних даних. На відміну від своїх попередників, які зазвичай використовували простішу архітектуру, ця модель використовує глибоку 60-шарову структуру. Причина такого вибору проста: глибша архітектура може підвищити загальну продуктивність зі збільшенням параметрів моделі.
Що дійсно відрізняє InternLM-20B, так це її ретельний підхід до навчальних даних. Дослідницька група провела ретельне очищення даних і ввела багаті на знання набори даних під час попереднього навчання. Така ретельна підготовка значно розширила можливості моделі, покращивши розуміння мови, міркування та збереження знань. Результатом стала чудова модель, яка добре справляється з різноманітними завданнями, пов’язаними з мовою, відкриваючи нову еру в обробці природної мови.
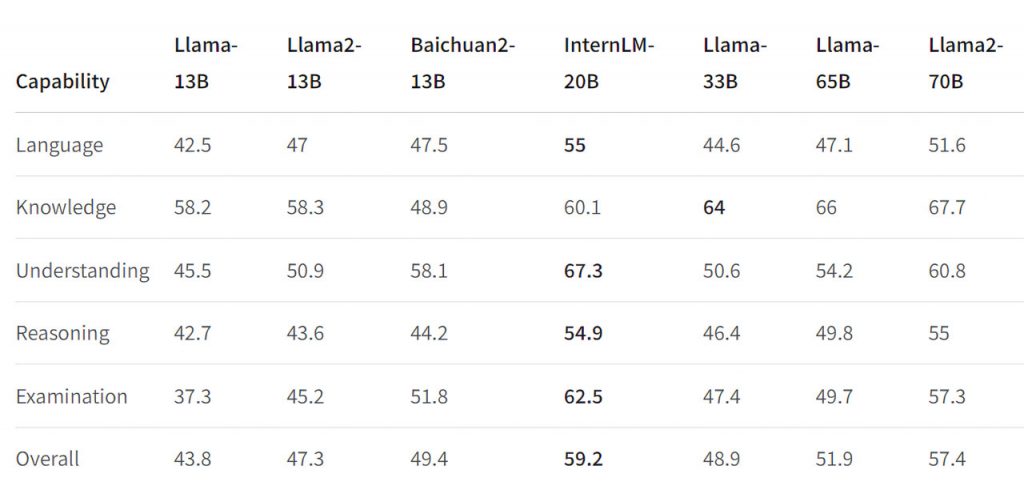
Метод InternLM-20B ефективно використовує величезні обсяги високоякісних даних на етапі попереднього навчання. Його архітектура, що складається з 60 шарів, вміщує величезну кількість параметрів, що дозволяє йому вловлювати складні структури в тексті. Така глибина дозволяє моделі досягати успіху в розумінні мови, що є критично важливим аспектом обробки природної мови (Natural Language Processing, NLP).
Що дійсно відрізняє InternLM-20B, так це його навчальні дані. Дослідницька група ретельно перевіряла ці дані, забезпечуючи їхню об’ємність і винятково високу якість. Це включало ретельне очищення даних і включення наборів даних, багатих на знання, що дозволило моделі демонструвати винятково хороші результати в різних вимірах.
InternLM-20B демонструє відмінні результати за різними критеріями оцінювання. Зокрема, вона перевершує існуючі моделі в розумінні мови, міркуванні та збереженні знань. Він підтримує вражаючу довжину контексту в 16 тис. слів, що є значною перевагою в завданнях, які вимагають більш широкого текстового контексту. Це робить його універсальним інструментом для різних застосувань NLP, від чат-ботів до мовного перекладу та узагальнення документів.
На закінчення, впровадження InternLM-20B відображає значний прогрес в обробці природної мови. Дослідники ефективно вирішили давні проблеми, пов’язані з глибиною мовної моделі та якістю даних, що призвело до створення моделі, яка перевершує інші за багатьма параметрами. Завдяки своїм вражаючим можливостям InternLM-20B має величезний потенціал для революції в багатьох сферах застосування NLP, що стало вагомою подією на шляху до більш наближеного до людського розуміння та генерування мови.
У світі, де комунікаційні та текстові системи штучного інтелекту продовжують відігравати все більш важливу роль, InternLM-20B є свідченням невпинного прагнення до досконалості в обробці природної мови.
)
)
)
)
)
)
)
)
