

29.09.2023 14:52
Домашні роботи з 3D-зором тепер розуміють складні мовні запити зі зменшеною залежністю від даних
Розуміння тривимірного середовища має вирішальне значення для домашніх роботів, оскільки дозволяє їм виконувати такі завдання, як навігація та відповіді на складні запитання. Однак сучасні методи часто не справляються зі складними мовними запитами і вимагають великих обсягів маркованих даних.
Великі мовні моделі, такі як ChatGPT і GPT-4, володіють винятковими навичками розуміння мови, включаючи вирішення проблем і використання інструментів. Вони досягають успіху, розбиваючи складні проблеми на менші, керовані завдання, ефективно використовуючи інструменти та інтерпретуючи нюанси мови, щоб пов’язати її з реальними об’єктами в 3D-контексті.
Нікхіл Мадаан та команда дослідників з Мічиганського та Нью-Йоркського університетів представила LLM-Grounder — новаторський підхід до візуального визначення 3D-об’єктів. Ця система LLM-агентів працює з відкритим словником. У той час як типова візуальна підготовка перевершує базові іменникові фрази, LLM-Grounder використовує можливості великих мовних моделей для обробки складних мовних конструкцій, просторових міркувань і розуміння здорового глузду.
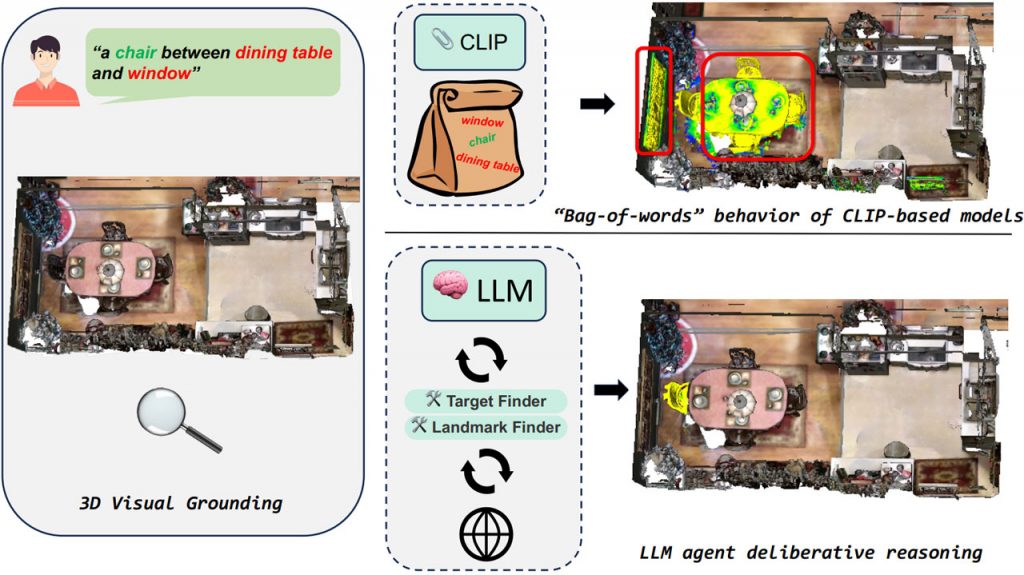
LLM-Grounder покладається на LLM для організації процесу заземлення. Отримавши запит природною мовою, LLM розбиває його на семантичні компоненти, такі як тип об’єкта, властивості (колір, форма, матеріал), орієнтири і просторові відносини. Ці підзапити потім пересилаються до інструменту візуального заземлення на основі CLIP, такого як OpenScene або LERF, обидва використовують відкритий словник для візуального заземлення 3D-зображень. Інструмент візуального позиціонування пропонує потенційні місця розташування об’єктів за допомогою обмежувальних рамок у сцені. Він також обчислює просторові дані, такі як об’єми об’єктів і відстані до орієнтирів, і надає ці дані агенту LLM. Такий комплексний підхід дозволяє LLM приймати обґрунтовані рішення на основі просторового контексту і міркувань здорового глузду, зрештою обираючи найкращого кандидата на основі початкового запиту. Процес триває ітеративно, поки не буде прийнято рішення, з додатковим акцентом на навколишньому контексті.
Одним з чудових аспектів LLM-Grounder є його здатність працювати без необхідності використання маркованих даних у навчанні. Це робить його адаптивним до різних 3D-сценаріїв і текстових запитів, навіть коли він має справу з новими середовищами. Експериментальні оцінки з використанням бенчмарку ScanRefer демонструють чудову точність нульового визначення місцезнаходження LLM-Grounder без мічених даних. Крім того, він покращує можливості позиціонування за допомогою підходів з відкритим словником, таких як OpenScene і LERF. Продуктивність LLM масштабується зі складністю мовних запитів, демонструючи його ефективність у вирішенні мовних проблем 3D-бачення. Це робить LLM-Grounder чудовим рішенням для додатків робототехніки, які вимагають контекстної обізнаності та швидких і точних відповідей на динамічні запитання.
)
)
)
)
)
)
)
)
