

27.09.2023 14:01
Дослідники Університету Цінхуа представили OpenChat
У сфері обробки природної мови (Natural Language Processing, NLP), що стрімко розвивається, можливості великих мовних моделей зростають в геометричній прогресії. Дослідники та організації постійно розширюють межі цих моделей, щоб покращити їхню продуктивність у різних завданнях NLP. Одним з найважливіших аспектів розвитку цих моделей є якість навчальних даних, на які вони покладаються. У цій статті ми розглянемо наукову роботу, яка вирішує проблему вдосконалення мовних моделей з відкритим вихідним кодом за допомогою даних змішаної якості та її наслідки для обробки природної мови.
Дані змішаної якості, які включають як згенеровані експертами, так і неоптимальні дані, становлять значну проблему при навчанні мовних моделей. Експертні дані, згенеровані сучасними моделями, такими як GPT-4, зазвичай мають високу якість і слугують золотим стандартом для навчання. На противагу цьому, неоптимальні дані зі старих моделей, таких як GPT-3.5, можуть демонструвати нижчу якість і створювати проблеми під час навчання. Це дослідження враховує цей сценарій змішаної якості даних і має на меті покращити здатність мовних моделей з відкритим вихідним кодом слідувати інструкціям.
Перш ніж заглибитися в запропонований метод, давайте коротко розглянемо сучасні методи та інструменти, що використовуються для навчання мовних моделей. Одним з поширених підходів є контрольоване точне налаштування (Supervised Fine-Tuning, SFT), коли моделі тренуються на завданнях, що вимагають виконання інструкцій, використовуючи високоякісні, згенеровані експертами дані, щоб керувати генерацією правильних відповідей. Крім того, набули популярності методи навчання з підкріпленням (Reinforcement Learning Fine-Tuning, RLFT). RLFT передбачає збір зворотного зв’язку від людей про їхні вподобання та навчання моделей для максимізації винагороди на основі цих вподобань.
Університет Цінхуа запропонував інноваційний метод у своїй дослідницькій роботі під назвою OpenChat. OpenChat — це фреймворк, який покращує мовні моделі з відкритим вихідним кодом, використовуючи дані змішаної якості, а його основним компонентом є точне налаштування навчання з умовним підкріпленням (Conditioned Reinforcement Learning Fine-Tuning, C-RLFT). C-RLFT спрощує процес навчання та зменшує залежність від моделей навчання з підкріпленням.

C-RLFT збагачує вхідну інформацію для мовних моделей, розрізняючи різні джерела даних на основі їхньої якості. Це досягається за допомогою реалізації політики, обумовленої класами, яка допомагає моделі розрізняти дані, згенеровані експертами (високої якості), і субоптимальні дані (нижчої якості). Таким чином, C-RLFT надає моделі чіткі сигнали, що дозволяє їй покращити свої здібності до виконання інструкцій.
Продуктивність OpenChat, зокрема моделі open chat-13b, оцінювали за допомогою різних тестів. Одним з найвідоміших бенчмарків є AlpacaEval, де тестується здатність моделі слідувати інструкціям. Openchat-13b демонструє чудові результати, перевершуючи інші моделі з відкритим вихідним кодом на 13 мільярдів параметрів, такі як LLaMA-2. Вона досягає більш високих показників виграшу і чудової продуктивності в завданнях на виконання інструкцій, демонструючи ефективність методу C-RLFT.
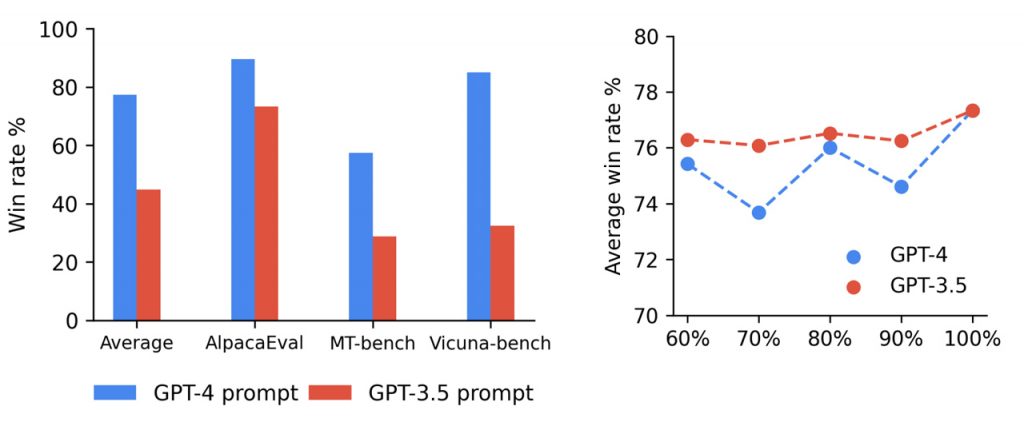
Дослідницька група підкреслює важливість якості даних. Незважаючи на свою обмежену кількість, експертні дані відіграють вирішальну роль у підвищенні продуктивності мовних моделей. Здатність розрізняти експертні та неоптимальні дані в поєднанні з методом C-RLFT призводить до суттєвого покращення продуктивності моделі. Це підкреслює важливість курування високоякісних навчальних даних для забезпечення успіху навчання мовних моделей.
Висновки та подальші дослідження
Фреймворк OpenChat і метод C-RLFT є багатообіцяючими для майбутнього обробки природної мови. Цей підхід відкриває нові шляхи для досліджень і розробок, спрощуючи процес навчання і зменшуючи залежність від складних моделей винагороди. Він також вирішує проблему даних змішаної якості, роблячи їх більш доступними для ефективного використання різноманітних навчальних наборів даних.
На закінчення, OpenChat представляє інноваційне рішення для покращення мовних моделей з відкритим вихідним кодом за допомогою даних змішаної якості. Завдяки впровадженню методу C-RLFT, цей підхід досягає чудових можливостей слідування інструкціям, що демонструється його продуктивністю в бенчмарках. Оскільки обробка природної мови продовжує розвиватися, інноваційні методи, такі як OpenChat, прокладають шлях до більш ефективного та результативного навчання мовних моделей.
)
)
)
)
)
)
)
)
