

26.09.2024 12:09
NVIDIA розширює межі точності та ефективності з Llama-3.1-Nemotron-51B
NVIDIA представила Llama 3.1-Nemotron-51B, що являє собою справжній винахід у мовних моделях, заснованих на Llama 3.1-70B від Meta. Ця нова модель, яка використовує методи пошуку нейронної архітектури (NAS), забезпечує виняткову продуктивність, балансуючи між високою точністю та ефективністю. Ключовим досягненням є те, що модель може працювати на одному графічному процесорі NVIDIA H100, що робить її більш доступною для широкого розгортання.
Однією з найбільш помітних переваг Llama 3.1-Nemotron-51B є її економічність. Хоча фундаментальні моделі відомі своїми дивовижними можливостями в таких завданнях, як міркування та узагальнення, вони часто дорогі в експлуатації через високі витрати на обчислення висновків. Нова модель розв’язує цю проблему шляхом розміщення на одному графічному процесорі, що спрощує її використання на різних платформах, від периферійних систем до хмарних інфраструктур. Це знижує загальну вартість експлуатації, що робить її цінним рішенням для компаній, які шукають високоякісні моделі штучного інтелекту за зниженою ціною.
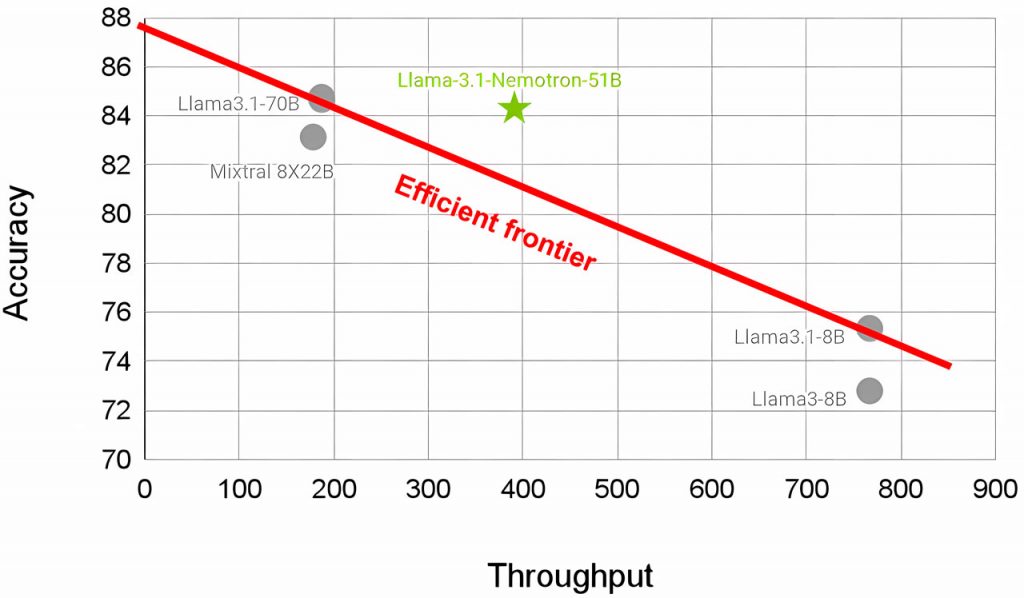
Модель Llama 3.1-Nemotron-51B призначена для розширення меж ефективності мовних моделей, що передбачає найвищу точність при збереженні високої пропускної здатності (що корелює з меншими витратами).
Завдяки цьому вона стане в нагоді для додатків, які потребують масштабованого штучного інтелекту, наприклад, у середовищі Kubernetes або при обслуговуванні декількох моделей в корпоративній інфраструктурі.
Для покращення розгортання модель була оптимізована за допомогою NVIDIA NIM (Neural Inference Microservice) з використанням рушіїв TensorRT-LLM. Ця інтеграція забезпечує вищу продуктивність під час виведення, одночасно спрощуючи процеси розгортання для бізнесу.
При створенні Llama 3.1-Nemotron-51B використовується технологія NAS (Network Based Storage), яка дозволяє адаптувати модель спеціально для ефективного виведення на графічних процесорах. Оптимізувавши структуру трансформерних блоків і використавши методи блокової дистиляції, NVIDIA зменшила обсяг пам’яті моделі, обчислювальні накладні витрати та кількість операцій з рухомою комою (FLOP), зберігши при цьому точність. Така архітектурна інновація дозволяє NVIDIA економічно ефективно створювати варіанти великих мовних моделей, оптимізованих для конкретних апаратних обмежень.
В цілому, випуск Llama 3.1-Nemotron-51B є впевненим кроком на шляху до розробки більш ефективних та доступних моделей штучного інтелекту, а також підкреслює прагнення NVIDIA переглянути продуктивність та економічність великих мовних моделей (LLM).
)
)
)
)
)
)
)
)
