

19.09.2024 13:57
Наскільки добре моделі ШІ можуть фіксувати емоції за звуком?
В умовах еволюції розмовних мовних моделей однією з головних проблем є відсутність метрик оцінювання, які б виходили за рамки простого генерування тексту. Чинні моделі можуть генерувати мовлення, яке є синтаксично та семантично точним, але їм важко врахувати повний спектр акустичних особливостей, таких як емоції, особистість мовця та фоновий шум. Ці фактори є невіддільною частиною людського спілкування, де навіть незначні зміни в тоні або оточенні можуть повністю змінити значення вимовленої фрази. Проте критерії для оцінки цих тонкощів залишаються недостатньо розробленими. Наявність цієї прогалини стає особливо очевидною в практичних застосуваннях, таких як розпізнавання емоцій або системи з декількома спікерами, де акустичні сигнали відіграють вирішальну роль для коректної інтерпретації мовлення.
Сучасні методи оцінювання розмовних мовних моделей зазвичай зосереджуються на текстових показниках, таких як передбачення слів або граматична точність, які дають обмежене уявлення про можливості моделі. Деякі спеціалізовані тестові системи, такі як ProsAudit, оцінюють просодичні елементи, але вони охоплюють лише вузький аспект акустичних характеристик. Крім того, наявні методи часто покладаються на ресурсомісткі обчислення, що робить їх непридатними для використання в режимі реального часу. Важливо, що ці оцінки не враховують нелінгвістичну інформацію, закладену в мовленні, таку як особистість мовця або акустика приміщення, які є важливими для створення зв’язної та контекстно орієнтованої мовленнєвої моделі.
Щоб виправити ці недосконалості, дослідники з Єврейського університету в Єрусалимі представили SALMON — систему комплексного оцінювання акустичної узгодженості та акустико-семантичного вирівнювання в розмовних мовних моделях. Основні завдання SALMON зосереджені на тому, наскільки добре модель може підтримувати акустичні властивості та наскільки ефективно вона може узгоджувати ці властивості з семантичним змістом мовлення. Наприклад, перевіряється, чи може модель виявити раптові зміни в ідентичності мовця, зміни фонового шуму або зміну настрою. На відміну від попередніх тестових систем, SALMON є масштабованою та ефективною, пропонуючи швидку, але ретельну оцінку великих моделей у широкому діапазоні акустичних параметрів.
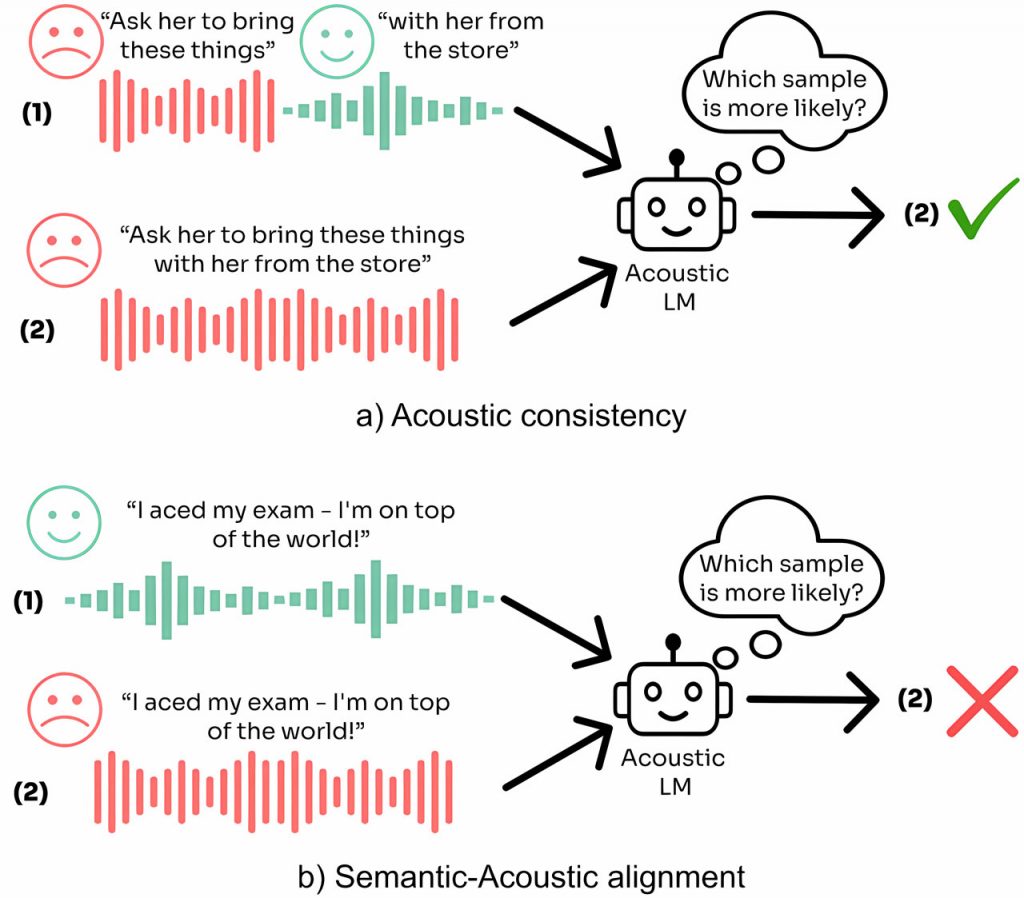
Пакет використовує спеціалізовані набори даних, такі як VCTK для узгодженості динаміки, Expresso для узгодженості емоцій і FSD50K для визначення фонового шуму, що робить його універсальним у роботі з різними акустичними елементами. Один з конкретних тестів, завдання узгодженості імпульсної характеристики приміщення (RIR), передбачає виявлення змін в акустиці приміщення в межах одного запису, пропонуючи конкретний приклад того, як SALMON фіксує нюанси акустичних зрушень.
Ще однією ключовою особливістю SALMON є завдання акустико-семантичного вирівнювання, яке ставить перед моделями завдання узгодити звуки навколишнього середовища або емоційні тони з мовленнєвим змістом. Наприклад, коли в мовному зразку згадується «спокійний пляж», модель повинна надати більшу ймовірність аудіокліпу зі звуками океану, а не іншому звуку, наприклад, будівельному шуму. Цей тип оцінювання імітує реальні сценарії, коли мовленнєвий контент повинен відповідати навколишньому звуковому середовищу для правильної інтерпретації.
Початкове тестування SALMON показало, що хоча розмовні мовні моделі можуть впоратися з простими акустичними завданнями, вони значно відстають від людського сприйняття складніших завдань. Наприклад, такі моделі, як TWIST 7B і pGSLM, належно виконували такі завдання, як визначення гендерної відповідності, але не змогли впоратися зі складними завданнями, такими як акустика приміщення або визначення настрою. У цих складних завданнях люди-оцінювачі незмінно перевершували моделі, часто з результатами, що перевищували 90%, порівняно з набагато нижчими показниками точності моделей.
Загалом, SALMON демонструє серйозні зрушення в оцінюванні діяльності розмовної мовної моделі, дозволяючи вийти за рамки генерації тексту та охопити акустичні характеристики, необхідні для розуміння мовлення в реальних умовах. Його впровадження прокладає шлях для майбутніх досліджень і розробки моделей, спрямованих на створення більш контекстно орієнтованих і акустично узгоджених розмовних мовних моделей, наближаючи нас до створення систем, які не поступатимуться людським комунікативним здібностям у різноманітних середовищах.
)
)
)
)
)
)
)
)
