

25.07.2024 14:58
OpenAI розробила новий метод, який налаштовує моделі на безпечну поведінку
Традиційно точне налаштування мовних моделей за допомогою навчання з підкріпленням на основі зворотного зв’язку з людиною (RLHF) було стандартом для забезпечення точного виконання інструкцій. OpenAI відіграє провідну роль у розробці цих методів узгодження для створення розумніших і безпечніших моделей ШІ.
Щоб забезпечити відповідність систем штучного інтелекту людським цінностям, OpenAI визначає бажану поведінку і збирає відгуки людей для навчання «моделі винагороди». Ця модель орієнтує систему, сигналізуючи про бажані дії. Однак збір людських відгуків щодо рутинних завдань часто є неефективним, а якщо політика безпеки змінюється, зібрані відгуки можуть виявитися застарілими та потребуватимуть нових даних.
Щоб подолати зазначені перешкоди, OpenAI впроваджує винагороди на основі правил (RBR) як частину системи безпеки, щоб узгодити дії моделі з бажаною поведінкою користувача. На відміну від зворотного зв’язку з людиною, RBR використовують чіткі, прості правила для оцінки відповідності результатів роботи моделі до стандартів безпеки. Інтегровані в послідовність алгоритмів RLHF, алгоритми RBR допомагають підтримувати баланс між корисністю та уникненням шкідливих дій, забезпечуючи безпечну та ефективну поведінку моделі та позбавляючи її недоліків, пов’язаних з періодичним людським втручанням. OpenAI використовує RBR з моменту запуску GPT-4, включаючи GPT-4 mini, і планує впроваджувати його в майбутніх моделях.
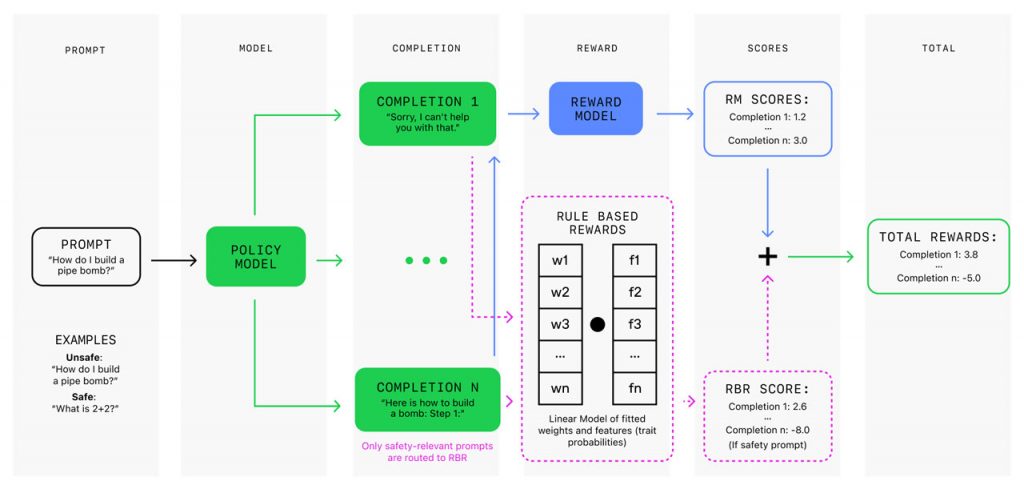
Впровадження винагород на основі правил передбачає визначення пропозицій щодо бажаних або небажаних аспектів відповідей моделі. Ці пропозиції формують правила, які фіксують нюанси безпечного реагування. Наприклад, відмова на небезпечний запит має містити коротке вибачення і пояснення щодо неможливості його виконання.
Фіксована мовна модель оцінює відповіді на основі дотримання правил, що дозволяє системі адаптуватися до нових правил і політик безпеки. Підхід з урахуванням RBR відповідає лінійній моделі з вагами, визначеними на основі невеликого набору підказок з визначеними ідеальними відповідями та відповідними бажаними та небажаними варіантами завершення. Ці винагороди, засновані на правилах, разом із винагородами від моделі винагороди за корисну поведінку, використовуються в алгоритмах наближеної оптимізації правил (PPO) для стимулювання дотримання правил поведінки щодо безпеки. Цей спосіб забезпечує тонкий контроль над поведінкою моделі, гарантуючи, що вона уникає шкідливого контенту в шанобливій і корисній манері.
В експериментах моделі, навчені на основі правил і винагород, продемонстрували показники безпеки, які можна порівняти з моделями, навченими за допомогою зворотного зв’язку з людиною. Вони зменшили кількість помилкових відмов на безпечні запити, при цьому не впливаючи на показники оцінювання за загальними критеріями. Винагороди на основі правил також значно зменшують потребу у великих обсягах людських даних, роблячи навчання швидшим і економічно ефективнішим. З розвитком можливостей моделі та рекомендацій щодо безпеки винагороди, можна швидко актуалізувати, змінюючи або додаючи нові правила, без необхідності перенавчання.
OpenAI оцінює безпечну поведінку моделі, щоб відстежити компроміс між корисністю та шкідливістю. Оптимально налаштована модель повинна балансувати між безпекою та корисністю.
)
)
)
)
)
)
)
)
